AI Agents in Production 2026: Patterns and Antipatterns After Deploying in Nexo, PA and Client Projects
By the Kiwop team · Digital agency specialized in Software Development and Applied Artificial Intelligence · Published on April 19, 2026 · Last updated: April 19, 2026
TL;DR — Fifteen months deploying AI agents in Nexo, PA and client projects leave us with 8 patterns and 4 AI antipatterns. Key rules: narrow scope beats generalist, human confirmation before irreversible actions, and never lock-in with a single LLM. If you already have an agent in production or are about to deploy one, here's the full framework.

2026 is the first year where AI agents stop being conference demos and become infrastructure that someone has to reboot at 3 a.m. when a step fails. At Kiwop, we've been building agents that live in production since January 2025: inside our own SaaS Nexo, as internal team tools, and in client projects.
This article gathers the architecture decisions that have survived those fifteen months. Each pattern comes from a concrete incident, a cost we didn't want to pay again, or a complaint that forced us to rethink. Each antipattern is something we've done wrong at least once. If you're about to deploy your first agent, or you already have one and maintenance costs more than the initial development, this is the guide we wish we'd had when we started.
Context: where we've deployed AI agents at Kiwop
Before we get to the patterns, a map of where the data speaks from. AI agents in production at Kiwop as of April 2026 fall into three categories.
Agents in Nexo, our multi-tenant SaaS (HR, CRM, projects, billing). Inside Nexo two families run: Brain protocols, a multi-step workflow engine per client and workspace, and the AI contract extractor that processes PDFs to automate the creation of contracts and billing milestones. Brain has several dozen active protocols distributed across client workspaces; the extractor processes several hundred documents monthly.
PA, the internal personal assistant. Detailed in From OpenClaw to a PA with Claude Code and MCP, it connects IMAP email, Gmail, Slack, Telegram and Google Calendar with a persistent Claude Code session. Several team members use it daily and together it processes something above 1,000 daily interactions.
Client integrations. Custom agents: a ticket triage agent for a fintech client, a lead enrichment agent for an e-commerce client, and a legal documentation consultation agent for a consulting client. Together they clock around 200–400 daily runs.
LLMs we use. We combine Anthropic models (Haiku 4.5, Sonnet 4.5, Opus 4.7) for most conversational and reasoning workloads, and OpenAI models (GPT-4o and GPT-4o-mini) for structured extraction and cost-sensitive workloads. The choice is made per feature and per workspace through an AiGateway we'll see later.
Pattern 1: Narrow scope always beats generalist
The first temptation is to build an agent that "does everything" — reads email, checks calendar, updates CRM, replies on Slack, summarizes meetings. One huge prompt, one agent. In a demo it looks spectacular; in production it doesn't survive. When the agent covers too much, the prompt fills with contradictory instructions, the LLM loses precision, and when something fails it's impossible to tell which sub-task failed. Worse: modifying the "how you summarize an email" instruction can alter the "how you write a Slack message" instruction.
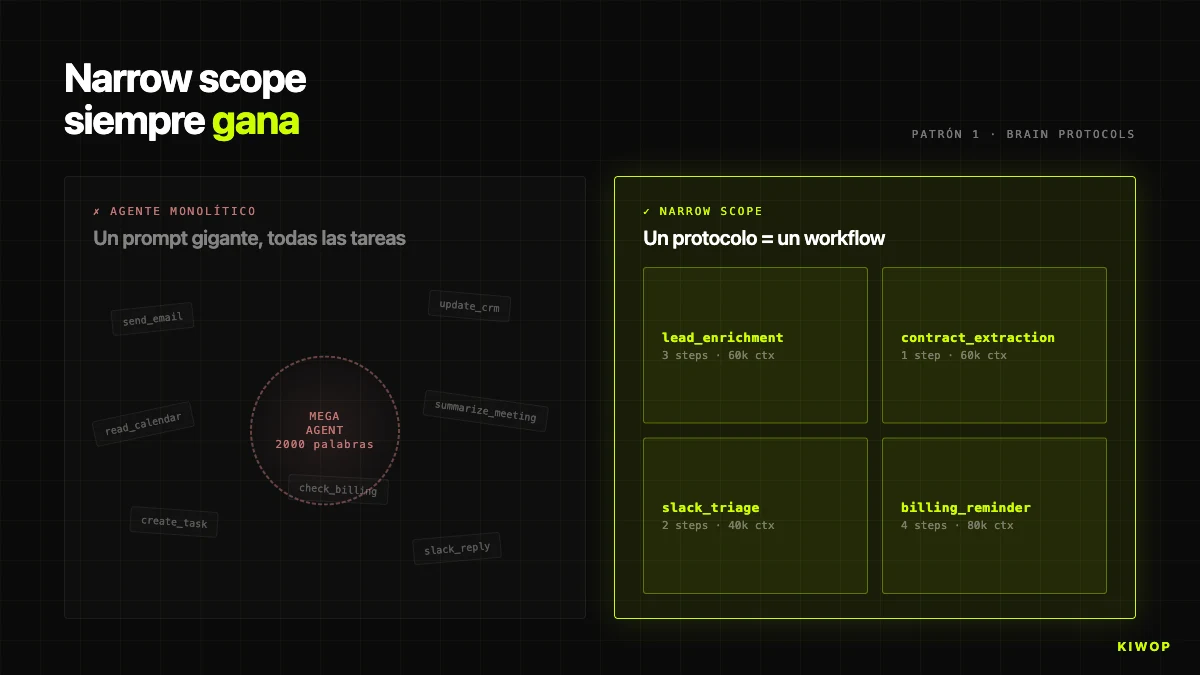
In Brain, the rule is explicit: one protocol = one workflow. Each protocol has a single purpose — lead_enrichment, contract_extraction_followup, project_health_check, weekly_billing_reminder. If a new use case emerges, a new protocol is created, not an existing one extended. When a client asks "can enrichment also send a Slack too", the correct answer is to create a second chained protocol, not bloat the first.
This shows up in the BrainProtocolEngine code: each protocol has its own steps, its trigger_config, its project_id and its workspace_id. If enrichment fails for a specific lead, the other protocols in the same workspace keep running without knowing.
The opposite antipattern — "the agent that does everything" — frequently appears in client proposals: "a copilot for the sales team that reads email, queries CRM, sends proposals, follows up, flags renewals". Our standard response is to redraw that request as five or six independent agents orchestrated with chained protocols. The difference in total cost of ownership over twelve months is easily 3x or 4x. If your agent needs a 2,000-word system prompt to work, you almost certainly have several agents duct-taped together. Separate them.
Pattern 2: Human confirmation before irreversible actions
Modern LLMs get it wrong about 1% of the time on closed tasks considered "easy". It's not a number we've measured rigorously — it's the order of magnitude of public benchmarks and matches our internal experience. Sounds low until you do the math.
An agent that executes 1,000 operations per day with a 1% error rate produces 10 erroneous operations per day. If they're reads, the cost is zero. If they're writes (sending an email, creating an event, modifying a record, deleting something), the cost can range from an annoyance to a post mortem. Ten incidents per day is unsustainable.
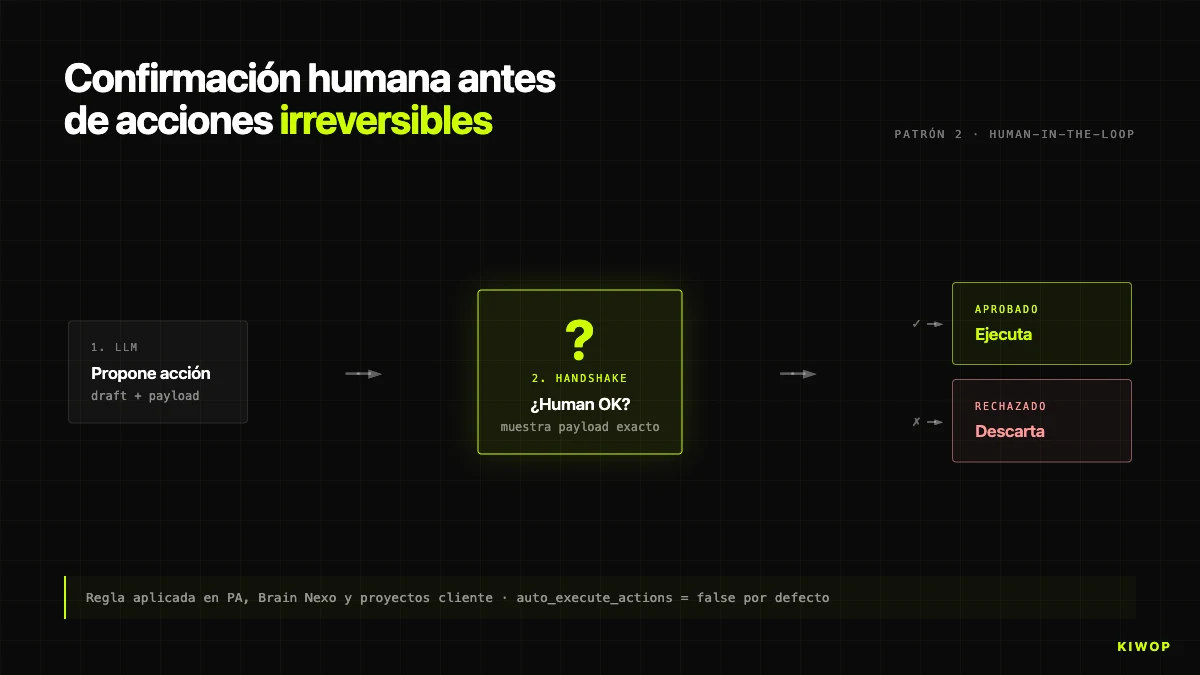
The no-exceptions rule: the agent never executes irreversible actions without explicit human confirmation. In PA, described in the personal assistant post, the agent can read the entire inbox but doesn't send without the human writing "yes". In Brain, the equivalent is the auto_execute_actions flag on BrainProtocol: by default false, when a step generates an action (create task, proposal, alert), what gets created is an AgentProposal pending approval, not the final action.
We only enable auto_execute_actions = true when three conditions are met: (1) the action is idempotent and reversible, (2) after several hundred manually verified runs, the observed error rate stays below 1%, even though the measurement isn't methodologically rigorous, and (3) the client signs off in writing. As of April 2026, less than a quarter of protocols run in autonomous mode.
A trap: the confirmation shouldn't be "are you sure? [yes/no]" because the user gets used to it and clicks without reading. The well-designed handshake shows exactly what's going to happen (recipient, subject, email body; DB entity to modify; exact amount). If the human has to know what they're confirming, they read what they're confirming.
This pattern connects to AI consulting: the conversation starts with "what actions can the agent take without asking?" and almost always the initial answer falls short. Expanding permissions is easy, pulling them back after an incident is expensive.
Pattern 3: Strict limits on context and steps
Multi-step agents are greedy. Each step adds information to the context, each call can return long responses, and without an explicit ceiling the context grows until one of three problems hits you: disproportionate cost, hallucination from inflated context, or provider timeout.
In BrainProtocolEngine we have two hard constants:
MAX_STEPS = 10 means a protocol cannot execute more than 10 steps per run, regardless of how many it has defined. Protocols with more than 10 steps are almost always a design that would have been better split into two chained ones; the limit forces that conversation.
MAX_CONTEXT_CHARS = 300000 applies to the total accumulated context. If the JSON exceeds 300,000 characters, a warning is logged and the prompt is truncated with an explicit message to the model: "CONTEXT TRUNCATED BY SIZE LIMIT". The limit is calibrated to fit comfortably in a 200K token window and stay away from the 1M of extended-context models — because, as we'll see later, big context and useful context are very different things.
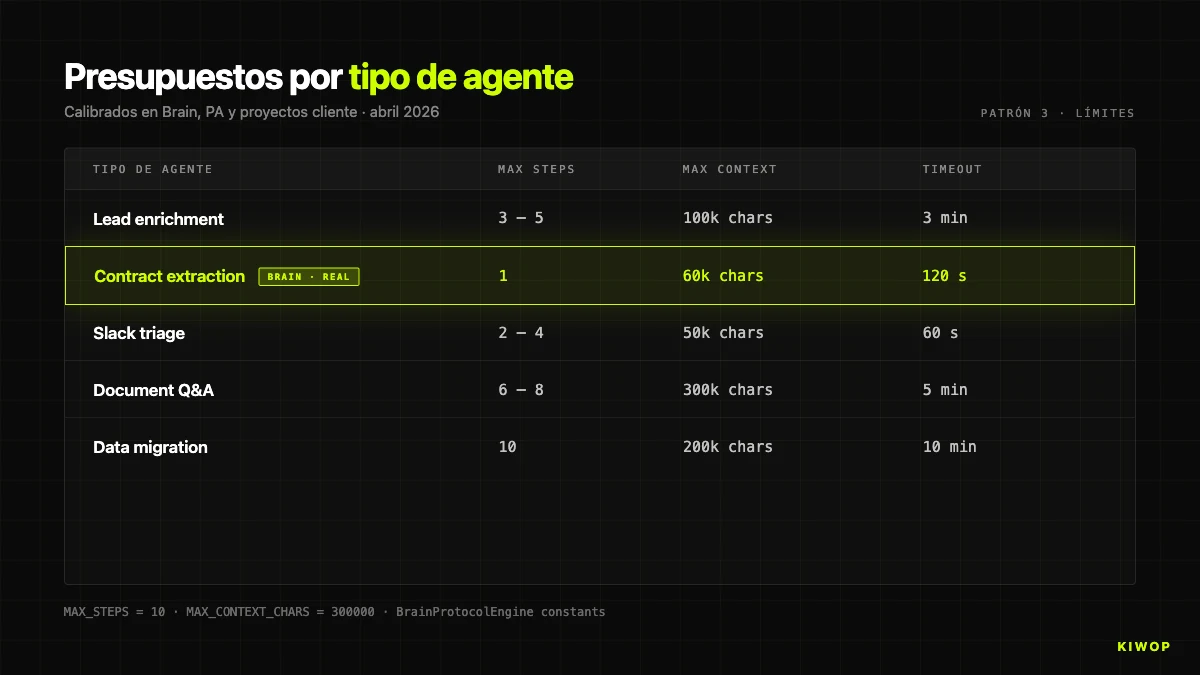
As an orientation reference, these are the default budgets we use by agent type:
These values are not universal — they're the ones that have passed the production test in our workloads. If you're starting out, start conservative and raise only when you have data to justify it.
Pattern 4: MCP as the common language instead of ad hoc integrations
Before 2025, each integration between an agent and an external system was custom code: a connector for Gmail, another for Calendar, another for Slack, each with its own authentication and maintenance. Most of the cost of building an agent didn't come from the prompt or the model, it came from the glue code.
Model Context Protocol (MCP) changed that during 2025 and has cemented its position in 2026. MCP is an open standard for any model to talk to any tool using a common "tool calls" grammar. Published by Anthropic in 2024, it was adopted by OpenAI, Google and the main AI clients. Today, most of the integrations we build lean on existing MCP servers instead of writing new clients.
The impact on development cost is brutal. For an agent that needs to talk to Gmail, Calendar, Drive, Slack, Linear and GitHub, the difference between writing six custom connectors with their OAuths and plugging in six existing MCP servers is on the order of weeks versus hours. And maintenance — when a service changes an endpoint or rotates credentials — stops being your problem.
If you're not clear on what MCP is, WebMCP: your website ready for AI agents explains it with concrete examples. For the comparison with sibling protocols, MCP, WebMCP and A2A: the protocols that define AI agents in 2026 goes into detail.
Operational rule: before writing a custom connector, check if there's an official or community MCP. If it exists and is maintained by a serious team, use it. MCP is not a panacea — it has blind spots (corporate IMAP, Telegram, vertical CRMs). For those gaps we write our own scripts, but in the shape of an MCP so that if someone publishes one tomorrow, the switch is painless.
Pattern 5: Explicit anti-hallucination in the prompt
LLMs hallucinate. It's an architectural feature of the transformer, not a bug that will disappear with the next model. Any agent that handles real data has to live with that reality.
The strategy that has worked best for us is inscribing anti-hallucination rules directly in the system prompt, literally and redundantly. Not "please, be precise". Numbered rules, critical terms in uppercase, operational instructions for what to do in case of doubt.
The clearest example in production is Nexo's contract extractor. The system prompt of OpenAiContractExtractor starts with these instructions:
CRITICAL RULES: 1. NEVER invent or hallucinate data. If a field is not clearly stated, return null. 2. Return ONLY valid JSON. No explanations outside the JSON. 3. For each field, provide: - value: The extracted value (or null if not found) - confidence: A score from 0.0 to 1.0 indicating how confident you are - evidence: A brief quote from the document supporting your extraction (or null) 4. Dates MUST be in YYYY-MM-DD format. If day/month is unclear, return null.
Three mechanisms come into play:
Allow the model to say "I don't know". Returning null when data isn't clear is a valid result; inventing it is not. Many people write prompts without an explicit "data unavailable" outlet, and the model, forced, fills in with the most plausible thing it can find.
Ask for confidence and evidence per field. The confidence forces the model to meta-reason about its certainty. The evidence — a literal quote from the document — is verifiable: if the quote doesn't appear, the field is discarded. The output becomes auditable instead of a black box.
Strict structured formats. Dates in YYYY-MM-DD, numbers as numeric types, closed enumerations ("fixed" | "hourly" | "monthly"). The more closed the format, the less room for creative hallucination.
This strategy doesn't eliminate hallucination but reduces it to tolerable levels with human confirmation. In our internal data, moving from lax prompts to prompts with literal anti-hallucination rules cut falsely filled fields by a factor of about five, without changing the model.
Pattern 6: Mandatory observability
The first time a client asks "why did the agent do that?" and you don't have data to answer, you learn that observability isn't optional. Every run has to leave an auditable trace: tokens, latency, executed steps, inputs, outputs, who triggered it and from where.
In Brain, this is implemented with BrainProtocolRun. Each run creates a record with:
status:running | completed | failed | cancelledstep_results: array with an object per executed step (name, type, duration in ms, status, result or error)context: the accumulated context, truncated to 50,000 characters for storagecurrent_step: which step it was on when it completed or failedtokens_used: total tokens consumed (sum of input + output of allai_call)started_at/completed_attriggered_by_user_id/trigger_source: who and from what channel triggered the runerror: if it failed, the full message
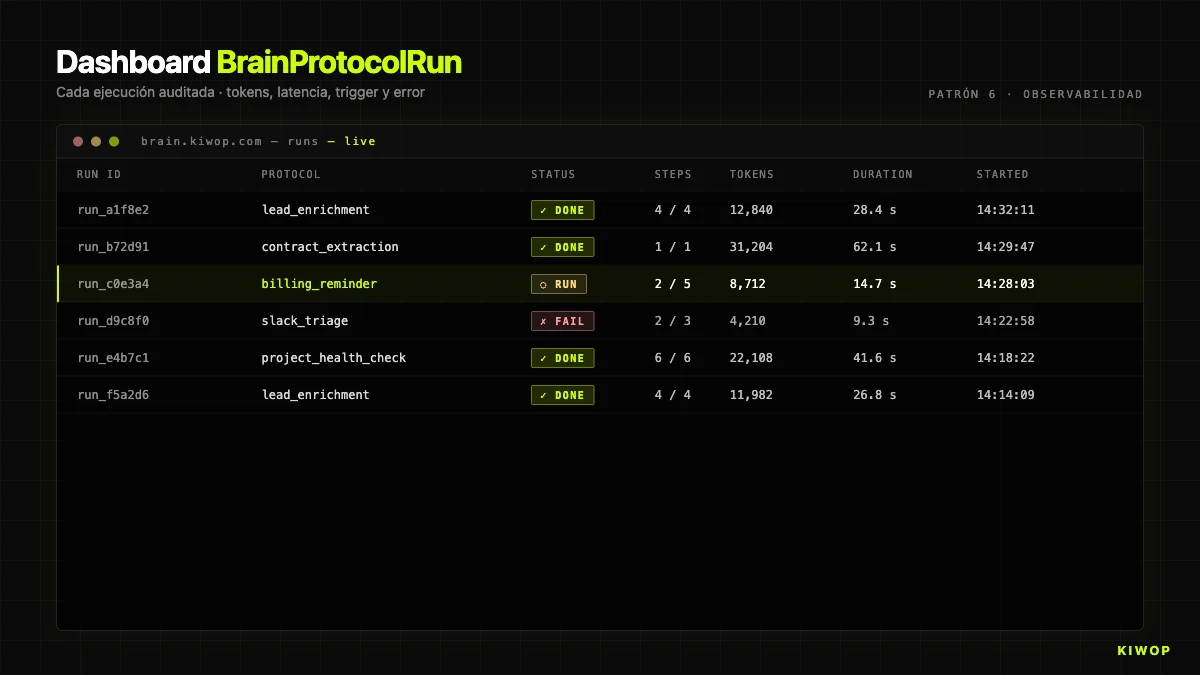
That structure answers the three questions always asked: how much does it cost? (sum of tokens_used × price per token), why did it fail? (error + step_results up to the step that failed), why did it take so long? (duration_ms per step).
Two additional rules learned the hard way:
Logs queryable in the moment. Files no one looks at are useless. The application DB is fine for low-medium volume; for high volume, a dedicated stack (Datadog, Grafana, Honeycomb) pays off before the first serious incident.
Always save `trigger_source` and `triggered_by_user_id`. When something goes wrong, the first question is forensic: did the scheduler trigger it, a user, an external integration, a webhook? Without that traceability, every incident is an archaeological dig.
This pattern is at the heart of our LLMOps offering: managing models in production isn't managing the models — it's managing the telemetry, cost, quality and security of the agents that use them.
Pattern 7: Agentic timeouts with exponential retry
External LLMs fail — demand spikes, network cuts, hung sessions. An agent that doesn't handle explicit timeouts is an agent that hangs, and a hanging agent is worse than a failing one: the human doesn't know what's happening.
Three components in our policy:
Explicit timeouts per step. In Brain each ai_call defines its max_tokens and effective timeout. Client default: 120 seconds. If a step exceeds it, the engine marks it as failed instead of leaving the run hanging.
Exponential retry with a cap. For transient errors (rate limit, 5xx, network timeouts) we retry with backoff: delay = base * 2^attempt + jitter, base = 500ms, max 3 retries, cap 30 seconds. Absorbs blips without hammering the provider.
Fail fast on unrecoverable errors. 4xx (invalid input, expired credentials, quota exhausted) are not retried — the next attempt is going to fail the same way. If the step is marked critical: true, it aborts the whole protocol.
Note for MCP agents: MCP servers also hang, and the client doesn't always propagate the timeout well. In PA we've wrapped some MCP calls with a process-level timeout. The lesson: don't trust timeouts from a single layer, stack several.
Pattern 8: LLM provider-agnostic design
On April 4, 2026 we learned firsthand the value of having infrastructure decoupled from the provider. That day Anthropic cut the OAuth tokens that allowed Claude Max and Pro subscriptions to be used with third-party harnesses, and several agents in the ecosystem were left without a backend. We tell the story in From OpenClaw to a PA with Claude Code and MCP and dedicated a specific post to the step-by-step build of the PA with Claude Code and MCP.
Nexo's infrastructure was unaffected because it was designed to be provider-agnostic. The key component is AiGateway, an abstraction that centralizes LLM calls and decides at runtime which client to use based on the workspace's connection and the feature.
Behind chat(), AiGateway resolves a WorkspaceAiConnection, builds the client (AnthropicClient, OpenAiClient or ClaudeCliClient for console-auth) and emits with the right model. Switching a workspace from Anthropic to OpenAI is a configuration change, not a code change.
Three concrete effects:
Resilience. If Anthropic has an incident, we rotate to OpenAI in minutes without touching protocol code. On April 4 we didn't have to because the cut affected Claude Code OAuth, not the API Nexo uses, but the capability was proven.
Per-feature choice. Chat uses Haiku 4.5 for cost; meeting summaries use Opus 4.7 for quality; contract extraction uses GPT-4o for its structured JSON mode. The abstraction lets you optimize each feature separately.
Per-workspace optimization. Small workspaces on cheap models, premium workspaces on premium models. Decision in workspaces_ai_connections, not in code.
The rule: never call the provider's API directly from your business code. Always go through your own intermediate layer. When the provider changes something — and they will — the impact stays in that layer.
LLM provider comparison as of April 2026
This table summarizes how we see the three major tier-top providers today from the perspective of an agent in production. It's not an absolute ranking — it's a guide for when it makes sense to lean on each within a multi-provider architecture like the one in the previous pattern.
Comparison as of April 2026; models and prices evolve quickly.
Next we break down four AI antipatterns of agents that we've seen derail projects — both ours and clients' — when any of the above disciplines isn't applied.
Antipattern 1: Autonomous agent acting without supervision
The story of "the autonomous agent that decides on its own" sounds good in slides and ends badly in incidents. The reason isn't philosophical, it's statistical: any stochastic process (and LLMs are) will make mistakes, and unsupervised mistakes turn into cumulative damage.
Typical failure modes:
Infinite loop. An agent that "decides what to do next" can invoke the same tool 50 times in a row. Without a cap like MAX_STEPS = 10, the run consumes tokens without value.
Cascade of effects. A wrong invoice fires a webhook that sends email to the client, which opens a CRM ticket, which notifies the sales team. Unwinding the chain costs more than the original error.
State corruption. An agent with write permissions that misreads an instruction can modify records impossible to reconstruct without a prior backup.
Practical rule: no agent should have irreversible write permissions without human-in-the-loop at the start. Enabling autonomous mode for specific actions is possible after hundreds of verified runs and an error rate below the domain's threshold. Never before. Never by default.
Antipattern 2: Trusting the model's "infinite" context
2026 models boast 200K, 500K and even 1M token windows. The message that has stuck is that "now you can fit whatever you want". That's not true in production.
Three reasons not to trust the full window:
Quality degradation with inflated context. Public benchmarks and our internal evaluations show that retrieval precision (needle-in-a-haystack) degrades as you approach the limit. A model that finds a datum at 99% at 50K tokens may drop to 80% or less at 500K tokens.
Cost proportional to input. A 300K token context costs six times more than a 50K one. With 100 daily calls, the monthly difference between "it all fits" and "only what's needed" is counted in hundreds or thousands of euros.
First-token latency. A 300K token prompt can take several seconds to be processed before the model starts answering, even with prompt caching. For conversational UX, it kills the perception of speed.
Discipline: the context should be the minimum needed, not the maximum possible. In Brain, data_filter exists precisely to reduce context between steps: a connector_fetch can bring in 500 emails; the filter cuts them down to the 20 that meet criteria; the subsequent ai_call only sees those 20. The RAG pattern is born from the same discipline — for large document bases, enterprise RAG is the correct architecture, not a giant context.
Antipattern 3: No read/write separation
Agents that read and write in the same step are a ticking time bomb. If the call fails mid-way, you don't know whether the write executed. If it's retried, you may duplicate. If there's an interpretation error, you don't have a snapshot of the state the agent saw.
Rule: separate reading and writing into distinct steps with explicit materialization between them. In Brain, the step typology reflects this: connector_fetch and db_query are read-only; action is the only one that writes. A well-designed protocol has the shape "N read steps, 0 or 1 write at the end". If you need to write more than once, split the protocol in two.
In client integrations we apply the same pattern: the agent generates a proposal (DB object with the draft or change), and a second step — with human confirmation — executes the action. It enables audit, safe retry, rollback and human-in-the-loop without redesigning the flow. Legitimate exception: idempotent operations with a natural key. For the rest, separate.
Antipattern 4: A single critical LLM provider
We've touched on it in pattern 8, but it's worth underlining: a critical agent that depends on a single provider is a fragile agent. Not because the provider is bad, but because any unilateral decision — price change, policy, model sunset, service outage, OAuth cut — can leave you without a backend.
On April 4, 2026 Anthropic cut Claude Max OAuth for third parties. OpenAI adjusts API prices periodically. Google changes Gemini quotas. They aren't malicious moves — they're business decisions — but all have the same effect on anyone who built assuming nothing would change.
Three minimum decoupling layers:
Your own abstraction like AiGateway. Your code talks to your abstraction, not to the provider SDK.
Credentials and config in the DB. Changing model or provider shouldn't require a deploy, just an UPDATE.
Portable prompts. If your prompt only works with a specific model, you have a fragile prompt. Well-written prompts (explicit rules, structured format) work acceptably across the tier-top models of the three majors. If the differences are large, the problem is in the prompt, not the model.
With these three layers, when provider A changes something your migration cost is hours, not weeks.
How we apply these patterns in Kiwop's services

These eight patterns and four antipatterns are the framework with which we deliver AI projects at Kiwop. When a client comes in with "I want an agent for X", the conversation follows this order:
First, AI consulting to bound the real scope. Almost always what the client asks for is three or four agents tied to the same thing; the consulting work is to separate them and decide what's autonomous and what requires a human handshake.
Second, AI agent development with architecture that applies patterns 3 through 8 by default: limits, MCPs, anti-hallucination, observability, timeouts, provider abstraction.
Third, LLM integration over MCP when it exists and over custom connectors when it doesn't.
Fourth, once in production, LLMOps for lifecycle management: observability, per-workspace costs, model rotation, incident response.
The goal: that the agent we deliver on day 1 keeps working on day 365 at a predictable cost.
Frequently asked questions
When does it make sense to build an AI agent in production?
When there's a repetitive, semi-structured task with clear success criteria that tolerates a small percentage of errors thanks to human confirmation. Examples: email or ticket triage, lead enrichment, document extraction, meeting summaries, message classification. It doesn't make sense for tasks with very high error cost without supervision, or for tasks solvable by a deterministic rule without an LLM.
Which LLM to choose for an agent in 2026?
Depends on the feature. For chat and multi-step with cost priority, Haiku 4.5 or GPT-4o-mini. For complex reasoning and quality extraction, Sonnet 4.5, Opus 4.7 or GPT-4o. For strict JSON, GPT-4o for its native mode. Start with the cheapest model that passes your own evaluations and move up only when data justifies it.
How much does it cost to deploy an AI agent in production?
Development between €6,000 and €15,000 for a narrow-scope agent with existing MCPs (rises with custom integrations). Operating cost: an agent of ~500 daily interactions on Haiku 4.5 can run at €50–150 monthly in tokens; on Opus 4.7 the bill can multiply by 10 or more. Design for low cost and move up only where it adds visible value.
Is an AI agent that touches client data safe?
It can be: (1) sensitive data reviewed before the prompt; (2) irreversible actions with human confirmation; (3) each run audited with traceability. For regulated content (healthcare, legal, financial with professional secrecy), consider on-premise or regional models with specific no-training agreements. An enterprise RAG project with controlled infrastructure is usually the right option.
How do I prevent my agent from hallucinating data?
Several layers: (1) prompt with literal anti-hallucination rules ("if you don't have the data, return null"); (2) confidence and evidence per field for auditable output; (3) structured formats with closed enums; (4) deterministic validation before critical systems; (5) human confirmation on irreversible operations. None alone is enough; the five together reduce hallucination to tolerable levels.
What is a Brain protocol in Nexo?
A declarative workflow with typed steps (connector_fetch, data_filter, ai_call, db_query, action, condition) executed sequentially with mutable context. Unlike an "all-purpose" agent that decides which tool to call, a protocol is deterministic in sequence but flexible within each step. Hard limits (MAX_STEPS = 10, MAX_CONTEXT_CHARS = 300000) and each run audited in BrainProtocolRun with tokens, per-step latency, trigger source and result.
What do I do if my LLM provider changes prices or closes an access mode?
If you're decoupled (pattern 8), rotating is configuration: verify that prompts work with the new model and re-evaluate cost. If you weren't, first introduce the abstraction layer, separate credentials into config and test prompts on at least two providers. The work pays off very quickly the first time it saves you from an incident.
Can I start with an autonomous agent and add confirmation later?
The other way around: start with human confirmation on all irreversible actions and enable autonomous only when you have data of low error rate. Adding confirmation after an incident is more expensive than pulling it back when the agent proves solvent, especially in sensitive domains (money, client emails, CRM).
Conclusion: patterns scale, antipatterns too
2026 is the first year AI agents have become infrastructure: not the new thing we're trying, but the thing we had and need to keep working. That status change brings disciplines borrowed from classic engineering — observability, explicit limits, separation of concerns, provider decoupling — that the 2024 hype had pushed to the background.
The eight patterns and four antipatterns in this article are what, in our experience, separate an agent that survives twelve months in production from one that has to be rebuilt in three. The most expensive AI antipatterns aren't technical failures but design decisions: granting autonomy without supervision, trusting infinite context, mixing reads and writes, or locking in with a single provider. The value isn't in the model or the prompt — it's in the infrastructure that wraps the prompt and makes it correct, auditable, cheap and replaceable on day 365.
If you're starting your first agent, or you already have one and suspect it's costing you more to maintain than it helps, at Kiwop — Digital agency specialized in Software Development and Applied Artificial Intelligence for global clients in Europe and the US — we do AI agent development, AI consulting, LLM integration and LLMOps as coordinated pieces of the same process.