KI-Agenten in Produktion 2026: Muster und Antimuster nach dem Deployment in Nexo, PA und Kundenprojekten
Vom Kiwop-Team · Digitalagentur spezialisiert auf Softwareentwicklung und angewandte Künstliche Intelligenz für globale Kunden in Europa und den USA · Veröffentlicht am 19. April 2026 · Zuletzt aktualisiert: 19. April 2026
TL;DR — Fünfzehn Monate des Deployments von KI-Agenten in Nexo, PA und Kunden hinterlassen uns 8 Muster und 4 Antimuster für KI. Schlüsselregeln: Narrow Scope schlägt Generalist, menschliche Bestätigung vor irreversiblen Aktionen und niemals Lock-in mit einem einzigen LLM. Wenn Du bereits einen Agenten in Produktion hast oder kurz davor bist, ihn zu deployen, hier ist das komplette Rahmenwerk.

Das Jahr 2026 ist das erste, in dem KI-Agenten aufhören, Konferenz-Demos zu sein, und zu Infrastruktur werden, die jemand um 3 Uhr morgens neu starten muss, wenn ein Step fehlschlägt. Bei Kiwop bauen wir seit Januar 2025 Agenten, die in Produktion leben: innerhalb unseres eigenen SaaS Nexo, als interne Werkzeuge des Teams und in Kundenprojekten.
Dieser Artikel sammelt die Architekturentscheidungen, die diese fünfzehn Monate überlebt haben. Jedes Muster stammt aus einem konkreten Vorfall, Kosten, die wir nicht wieder zahlen wollten, oder einer Beschwerde, die uns zum Umdenken zwang. Jedes Antimuster ist etwas, das wir mindestens einmal falsch gemacht haben. Wenn Du kurz davor stehst, Deinen ersten Agenten zu deployen, oder wenn Du bereits einen hast und die Wartung mehr kostet als die ursprüngliche Entwicklung, ist dies der Leitfaden, den wir gerne gehabt hätten, als wir anfingen.
Kontext: Wo wir KI-Agenten bei Kiwop deployt haben
Bevor wir zu den Mustern kommen, eine Karte dessen, woher die Daten sprechen. Die KI-Agenten in Produktion bei Kiwop Stand April 2026 gruppieren sich in drei Kategorien.
Agenten in Nexo, unserem multi-tenant SaaS (HR, CRM, Projekte, Fakturierung). Innerhalb von Nexo laufen zwei Familien: Brain protocols, ein Multi-Step-Workflow-Motor pro Kunde und Workspace, und der Vertragsextraktor per KI, der PDFs verarbeitet, um die Erstellung von Verträgen und Abrechnungsmeilensteinen zu automatisieren. Brain hat mehrere Dutzend aktive Protokolle, verteilt über Kunden-Workspaces; der Extraktor verarbeitet einige Hundert Dokumente pro Monat.
PA, der interne persönliche Assistent. Detailliert beschrieben in Von OpenClaw zu PA mit Claude Code und MCP, verbindet er IMAP-E-Mail, Gmail, Slack, Telegram und Google Calendar mit einer persistenten Claude-Code-Sitzung. Er wird täglich von mehreren Teammitgliedern genutzt und verarbeitet insgesamt etwas über 1.000 Interaktionen pro Tag.
Kundenintegrationen. Maßgeschneiderte Agenten: ein Ticket-Triage-Agent für einen Fintech-Kunden, ein Lead-Enrichment-Agent für einen E-Commerce-Kunden und ein Dokumentations-Abfrage-Agent für einen Beraterkunden. Insgesamt bewegen sich die 200-400 Ausführungen pro Tag.
LLMs, die wir verwenden. Wir kombinieren Modelle von Anthropic (Haiku 4.5, Sonnet 4.5, Opus 4.7) für den Großteil der dialogorientierten und Reasoning-Lasten und Modelle von OpenAI (GPT-4o und GPT-4o-mini) für strukturierte Extraktion und kostensensitive Workloads. Die Wahl erfolgt per Feature und per Workspace über ein AiGateway, das wir weiter unten sehen werden.
Muster 1: Narrow Scope schlägt immer Generalist
Die erste Versuchung ist, einen Agenten zu bauen, der "alles macht" — E-Mails liest, Kalender abfragt, CRM aktualisiert, Slack antwortet, Meetings zusammenfasst. Ein einziger riesiger Prompt, ein einziger Agent. In der Demo sieht er spektakulär aus; in Produktion überlebt er nicht. Wenn der Agent zu viel abdeckt, füllt sich der Prompt mit widersprüchlichen Anweisungen, das LLM verliert Präzision, und wenn etwas fehlschlägt, ist es unmöglich zu wissen, in welcher Subtask er fehlgeschlagen ist. Schlimmer: Die Anweisung "wie Du eine E-Mail zusammenfasst" zu ändern, kann die von "wie Du eine Slack-Nachricht schreibst" verändern.
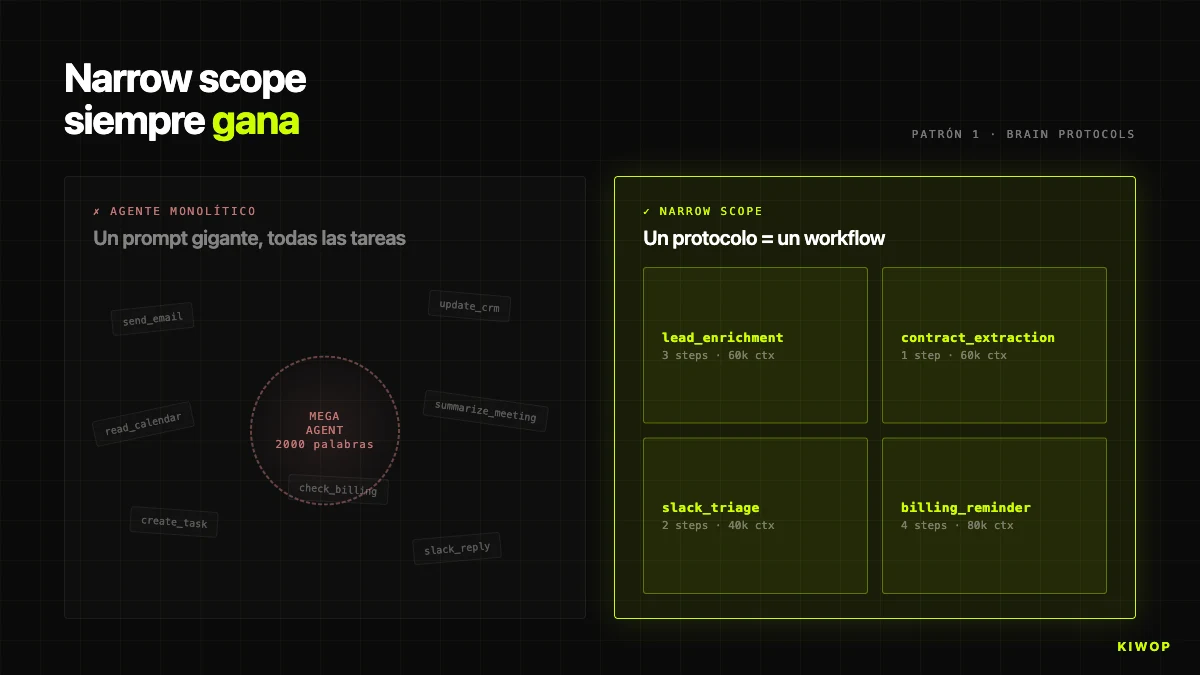
In Brain ist die Regel explizit: ein Protokoll = ein Workflow. Jedes Protokoll hat einen einzigen Zweck — lead_enrichment, contract_extraction_followup, project_health_check, weekly_billing_reminder. Wenn ein neuer Use Case auftaucht, wird ein neues Protokoll erstellt, kein bestehendes erweitert. Wenn ein Kunde verlangt, "dass Enrichment auch einen Slack sendet", ist die korrekte Antwort, ein zweites verkettetes Protokoll zu erstellen, nicht das erste aufzublähen.
Das zeigt sich im Code des BrainProtocolEngine: Jedes Protokoll hat seine eigenen steps, seine trigger_config, seine project_id und seine workspace_id. Wenn Enrichment für einen konkreten Lead fehlschlägt, laufen die anderen Protokolle desselben Workspace weiter, ohne etwas mitzubekommen.
Das entgegengesetzte Antimuster — "der Agent, der alles macht" — taucht häufig in Kundenvorschlägen auf: "ein Copilot für das Vertriebsteam, der E-Mails liest, das CRM abfragt, Angebote versendet, Nachverfolgung macht, an Verlängerungen erinnert". Unsere Standardantwort ist, diese Anfrage als fünf oder sechs unabhängige Agenten zu zeichnen, die mit verketteten Protokollen orchestriert werden. Der Unterschied bei den Gesamtbetriebskosten über zwölf Monate ist leicht 3x oder 4x. Wenn Dein Agent einen System-Prompt von 2.000 Wörtern braucht, um zu funktionieren, hast Du mit ziemlicher Sicherheit mehrere Agenten mit Klebeband zusammengeklebt. Trenne sie.
Muster 2: Menschliche Bestätigung vor irreversiblen Aktionen
Moderne LLMs irren sich etwa 1% der Male bei geschlossenen Aufgaben, die als "einfach" gelten. Das ist keine von uns streng gemessene Zahl — es ist die Größenordnung öffentlicher Benchmarks und entspricht unserer internen Erfahrung. Klingt niedrig, bis Du die Rechnung machst.
Ein Agent, der 1.000 Operationen pro Tag mit 1% Fehler ausführt, produziert 10 fehlerhafte Operationen täglich. Wenn es Leseoperationen sind, sind die Kosten null. Wenn es Schreiboperationen sind (E-Mail senden, Event erstellen, Datensatz ändern, etwas löschen), können die Kosten von einem Ärgernis bis zu einem Post-Mortem reichen. Zehn Vorfälle pro Tag sind nicht tragbar.
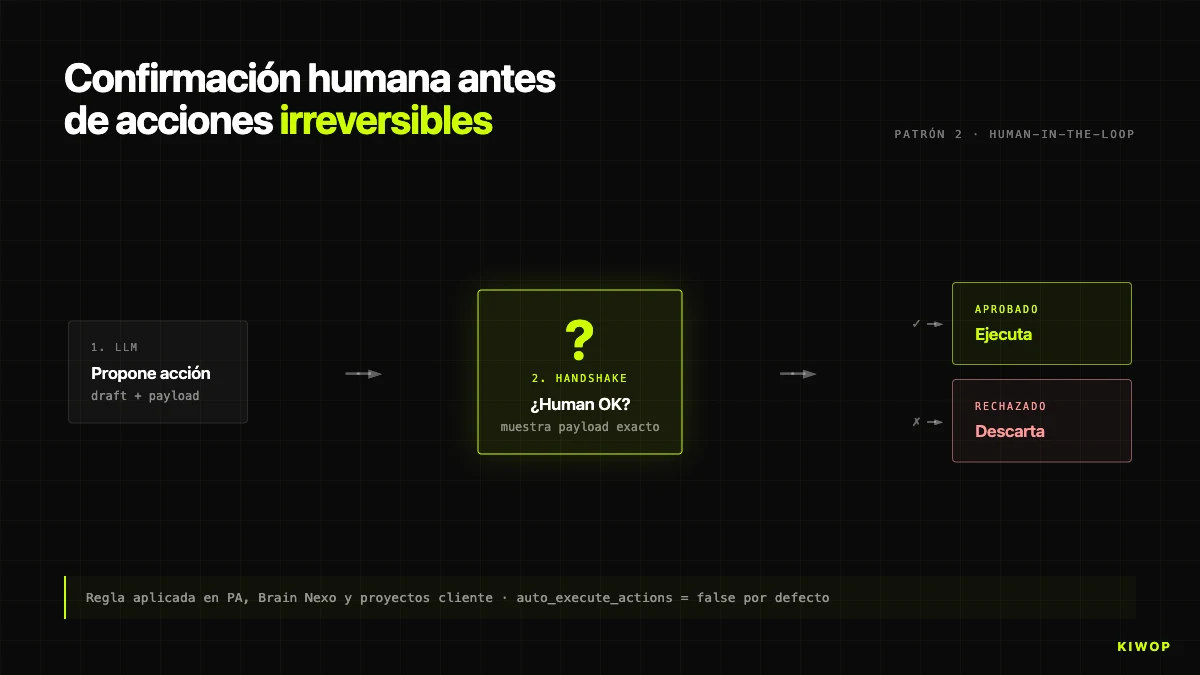
Die Regel ohne Ausnahmen: Der Agent führt niemals irreversible Aktionen ohne explizite menschliche Bestätigung aus. In PA, beschrieben in dem Post über den persönlichen Assistenten, kann der Agent das gesamte Postfach lesen, aber er sendet nicht, ohne dass der Mensch "ja" schreibt. In Brain ist das Äquivalent das Flag auto_execute_actions in BrainProtocol: standardmäßig auf false, wenn ein Step eine action generiert (Task erstellen, Angebot, Alarm), ist das, was erstellt wird, ein zur Genehmigung ausstehender AgentProposal, nicht die endgültige Aktion.
Wir aktivieren auto_execute_actions = true nur, wenn drei Bedingungen erfüllt sind: (1) die Aktion ist idempotent und reversibel, (2) nach mehreren Hundert manuell verifizierten Runs bleibt die beobachtete Fehlerrate unter 1%, obwohl die Messung methodisch nicht streng ist, und (3) der Kunde unterzeichnet die Aktivierung schriftlich. Stand April 2026 läuft weniger als ein Viertel der Protokolle im autonomen Modus.
Eine Falle: Die Bestätigung sollte nicht "bist Du sicher? [ja/nein]" sein, weil der Nutzer sich daran gewöhnt und klickt, ohne zu lesen. Der gut gestaltete Handshake zeigt genau, was passieren wird (Empfänger, Betreff, E-Mail-Body; zu ändernde DB-Entität; exakter Betrag). Wenn der Mensch wissen muss, was er bestätigt, liest er, was er bestätigt.
Dieses Muster verbindet sich mit der KI-Beratung: Das Gespräch beginnt mit "welche Aktionen kann der Agent ausführen, ohne zu fragen?" und fast immer fällt die anfängliche Antwort zu knapp aus. Berechtigungen zu erweitern ist einfach, sie nach einem Vorfall zu entziehen ist teuer.
Muster 3: Strenge Kontext- und Step-Limits
Multi-Step-Agenten sind gefräßig. Jeder Step fügt Informationen zum Kontext hinzu, jeder Call kann lange Antworten zurückgeben, und ohne explizite Obergrenze wächst der Kontext, bis eines von drei Problemen Dich trifft: unverhältnismäßige Kosten, Halluzination durch aufgeblähten Kontext oder Timeout des Anbieters.
Im BrainProtocolEngine haben wir zwei harte Konstanten:
MAX_STEPS = 10 bedeutet, dass ein Protokoll nicht mehr als 10 Steps pro Run ausführen kann, egal wie viele definiert sind. Protokolle mit mehr als 10 Steps sind fast immer ein Design, das besser in zwei verkettete aufgeteilt worden wäre; das Limit erzwingt dieses Gespräch.
MAX_CONTEXT_CHARS = 300000 gilt für den gesamten akkumulierten Kontext. Wenn das JSON 300.000 Zeichen überschreitet, wird ein Warning geloggt und der Prompt mit einer expliziten Nachricht an das Modell gekürzt: "KONTEXT WEGEN GRÖSSENBEGRENZUNG GEKÜRZT". Das Limit ist so kalibriert, dass es komfortabel in ein 200K-Token-Fenster passt und sich vom 1M der Modelle mit erweitertem Kontext entfernt — denn, wie wir später sehen werden, sind großer Kontext und nützlicher Kontext sehr verschiedene Dinge.
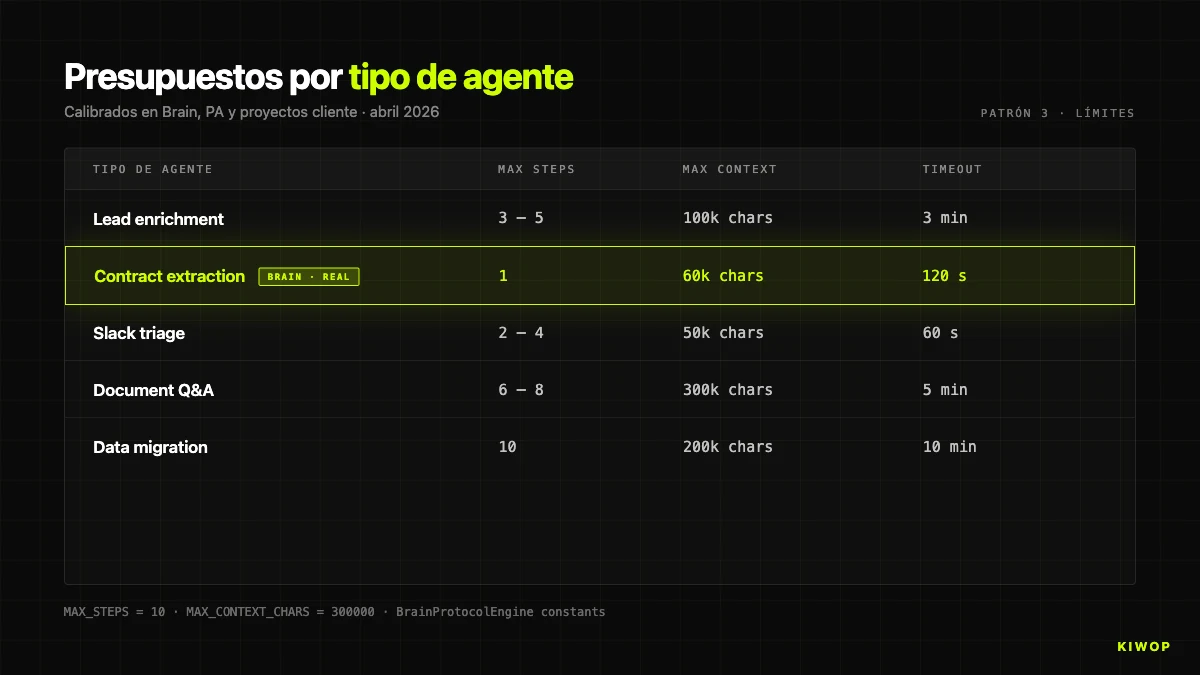
Als grobe Orientierung sind dies die Budgets, die wir je nach Agent-Typ standardmäßig verwenden:
Diese Werte sind nicht universell — sie sind diejenigen, die den Produktionstest in unseren Workloads bestanden haben. Wenn Du anfängst, starte konservativ und steigere nur, wenn Du Daten hast, die es rechtfertigen.
Muster 4: MCP als gemeinsame Sprache vor Ad-hoc-Integrationen
Vor 2025 war jede Integration zwischen einem Agenten und einem externen System maßgeschneiderter Code: ein Konnektor für Gmail, ein weiterer für Calendar, ein weiterer für Slack, jeder mit seiner Authentifizierung und Wartung. Der Großteil der Kosten für den Bau eines Agenten kam nicht vom Prompt oder Modell, sondern vom Glue Code.
Model Context Protocol (MCP) hat das 2025 geändert und seine Position 2026 konsolidiert. MCP ist ein offener Standard, damit jedes Modell mit jedem Werkzeug über dieselbe Grammatik von "tool calls" sprechen kann. 2024 von Anthropic veröffentlicht, wurde es von OpenAI, Google und den wichtigsten KI-Clients übernommen. Heute stützen sich die meisten Integrationen, die wir bauen, auf bereits existierende MCP-Server statt neuen Client zu schreiben.
Der Einfluss auf die Entwicklungskosten ist brutal. Für einen Agenten, der mit Gmail, Calendar, Drive, Slack, Linear und GitHub sprechen muss, ist der Unterschied zwischen dem Schreiben von sechs eigenen Konnektoren mit ihren OAuths und dem Einstecken von sechs existierenden MCP-Servern in der Größenordnung von Wochen gegen Stunden. Und die Wartung — wenn ein Dienst einen Endpoint ändert oder Credentials rotiert — ist nicht mehr Dein Problem.
Wenn Dir nicht klar ist, was MCP ist, erklärt WebMCP: Deine Website bereit für KI-Agenten es mit konkreten Beispielen. Für den Vergleich mit verwandten Protokollen geht MCP, WebMCP und A2A: die Protokolle, die KI-Agenten 2026 definieren ins Detail.
Operative Regel: Bevor Du einen eigenen Konnektor schreibst, prüfe, ob ein offizieller oder Community-MCP existiert. Wenn er existiert und von einem seriösen Team gepflegt wird, nutze ihn. MCP ist kein Allheilmittel — er hat blinde Flecken (Unternehmens-IMAP, Telegram, vertikale CRMs). Für diese Lücken schreiben wir eigene Skripte, aber in Form eines MCP, damit die Änderung, wenn morgen jemand einen veröffentlicht, schmerzlos ist.
Muster 5: Explizite Anti-Halluzination im Prompt
LLMs halluzinieren. Es ist ein architektonisches Merkmal des Transformers, kein Bug, der mit dem nächsten Modell verschwinden wird. Jeder Agent, der echte Daten behandelt, muss mit dieser Realität koexistieren.
Die Strategie, die uns am besten funktioniert hat, ist, die Anti-Halluzinations-Regeln direkt im System-Prompt zu verankern, wörtlich und redundant. Kein "bitte sei präzise". Nummerierte Regeln, kritische Begriffe in Großbuchstaben, mit operativen Anweisungen, was im Zweifelsfall zu tun ist.
Das klarste Beispiel in Produktion ist der Vertragsextraktor von Nexo. Der System-Prompt des OpenAiContractExtractor beginnt mit diesen Anweisungen:
CRITICAL RULES: 1. NEVER invent or hallucinate data. If a field is not clearly stated, return null. 2. Return ONLY valid JSON. No explanations outside the JSON. 3. For each field, provide: - value: The extracted value (or null if not found) - confidence: A score from 0.0 to 1.0 indicating how confident you are - evidence: A brief quote from the document supporting your extraction (or null) 4. Dates MUST be in YYYY-MM-DD format. If day/month is unclear, return null.
Drei Mechanismen kommen ins Spiel:
Dem Modell erlauben, "ich weiß es nicht" zu sagen. null zurückzugeben, wenn ein Datenpunkt unklar ist, ist ein gültiges Ergebnis; ihn zu erfinden, nicht. Viele Leute schreiben Prompts ohne expliziten Ausweg auf "Datenpunkt nicht verfügbar", und das Modell füllt, gezwungen, mit dem Plausibelsten, das es findet.
Vertrauen und Beweis pro Feld verlangen. Die confidence zwingt das Modell, über seine Gewissheit zu meta-reflektieren. Die evidence — wörtliches Zitat aus dem Dokument — ist verifizierbar: Wenn das Zitat nicht erscheint, wird das Feld verworfen. Der Output wird auditierbar statt Black Box.
Strenge strukturierte Formate. Daten in YYYY-MM-DD, Zahlen als numerische Typen, geschlossene Aufzählungen ("fixed" | "hourly" | "monthly"). Je geschlossener das Format, desto weniger Raum für kreative Halluzination.
Diese Strategie eliminiert Halluzination nicht, reduziert sie aber mit menschlicher Bestätigung auf tolerierbare Niveaus. In unseren internen Daten hat der Übergang von lockeren Prompts zu Prompts mit wörtlichen Anti-Halluzinations-Regeln fälschlicherweise gefüllte Felder um etwa den Faktor fünf reduziert, ohne das Modell zu wechseln.
Muster 6: Obligatorische Observability
Das erste Mal, dass ein Kunde fragt "Warum hat der Agent das getan?" und Du keine Daten zum Antworten hast, lernst Du, dass Observability nicht optional ist. Jede Ausführung muss eine auditierbare Spur hinterlassen: Tokens, Latenz, ausgeführte Steps, Inputs, Outputs, wer ausgelöst hat und von wo.
In Brain wird das mit BrainProtocolRun implementiert. Jede Ausführung erstellt einen Datensatz mit:
status:running | completed | failed | cancelledstep_results: Array mit einem Objekt pro ausgeführtem Step (Name, Typ, Dauer in ms, Status, Ergebnis oder Fehler)context: der akkumulierte Kontext, zur Speicherung auf 50.000 Zeichen gekürztcurrent_step: bei welchem Step es sich befand, als es abgeschlossen wurde oder fehlschlugtokens_used: insgesamt verbrauchte Tokens (Summe Input + Output allerai_call)started_at/completed_attriggered_by_user_id/trigger_source: wer und von welchem Kanal den Run ausgelöst haterror: wenn es fehlschlug, die vollständige Nachricht
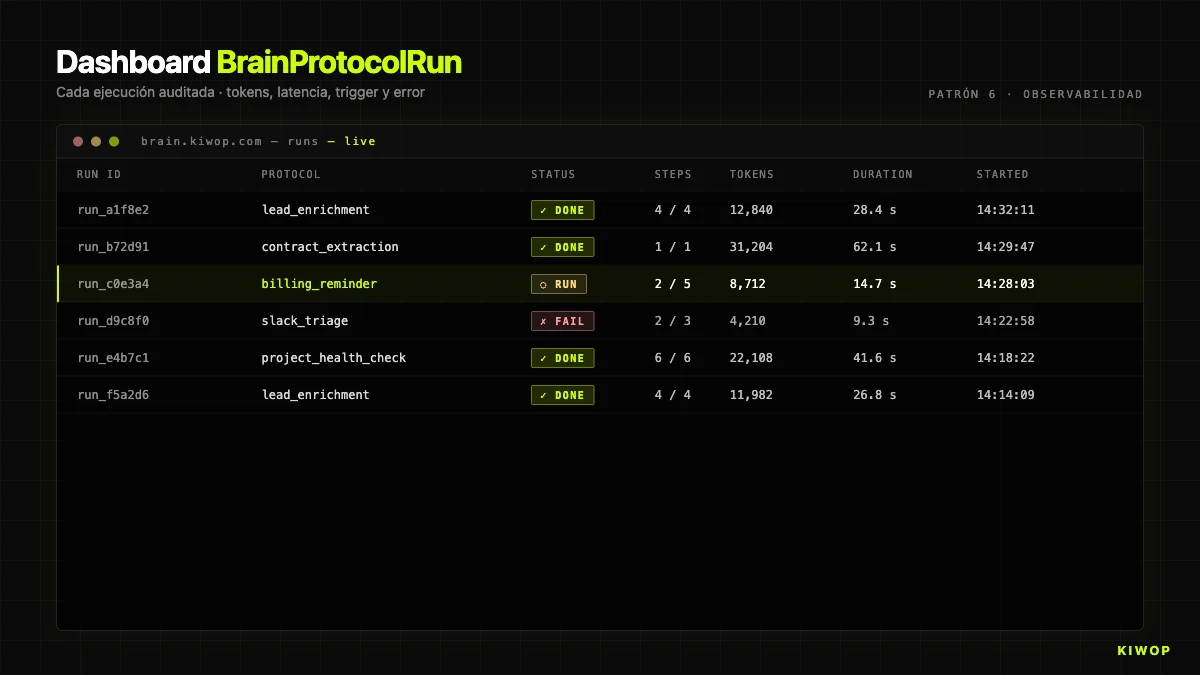
Diese Struktur beantwortet die drei Fragen, die immer am Ende gestellt werden: Wie viel kostet es? (Summe tokens_used × Preis pro Token), Warum ist es fehlgeschlagen? (error + step_results bis zum fehlgeschlagenen Step), Warum hat es so lange gedauert? (duration_ms pro Step).
Zwei zusätzliche Regeln, auf schmerzhafte Weise gelernt:
Heiße konsultierbare Logs. Archive, die niemand anschaut, nützen nichts. Die Anwendungs-DB ist für niedrig-mittleres Volumen okay; für hohes Volumen zahlt sich ein dedizierter Stack (Datadog, Grafana, Honeycomb) vor dem ersten schweren Vorfall aus.
Speichere immer `trigger_source` und `triggered_by_user_id`. Wenn etwas schiefgeht, ist die erste Frage forensisch: Hat es der Scheduler ausgelöst, ein Nutzer, eine externe Integration, ein Webhook? Ohne diese Nachverfolgbarkeit ist jeder Vorfall eine archäologische Untersuchung.
Dieses Muster steht im Herzen unseres LLMOps-Angebots: Modelle in Produktion zu verwalten bedeutet nicht, die Modelle zu verwalten — es bedeutet, die Telemetrie, die Kosten, die Qualität und die Sicherheit der Agenten zu verwalten, die sie nutzen.
Muster 7: Agentic Timeouts mit exponentiellem Retry
Externe LLMs fallen aus — Nachfragespitzen, Netzwerkausfälle, hängende Sitzungen. Ein Agent, der keine expliziten Timeouts handhabt, ist ein Agent, der hängt, und ein hängender Agent ist schlimmer als einer, der fehlschlägt: Der Mensch weiß nicht, was passiert.
Drei Komponenten in unserer Policy:
Explizite Timeouts pro Step. In Brain definiert jeder ai_call sein max_tokens und effektives Timeout. Client-Default: 120 Sekunden. Wenn ein Step es überschreitet, markiert der Engine ihn als failed, statt den Run hängen zu lassen.
Exponentielles Retry mit Limit. Bei transienten Fehlern (Rate Limit, 5xx, Netzwerk-Timeouts) versuchen wir es mit Backoff erneut: delay = base * 2^attempt + jitter, base = 500ms, maximal 3 Retries, Obergrenze 30 Sekunden. Absorbiert Blips, ohne den Anbieter zu bombardieren.
Schneller Ausfall bei nicht wiederherstellbaren Fehlern. 4xx (ungültiger Input, abgelaufene Credentials, erschöpftes Kontingent) werden nicht wiederholt — der nächste Versuch wird genauso fehlschlagen. Wenn der Step als critical: true markiert ist, bricht das gesamte Protokoll ab.
Hinweis für MCP-Agenten: Auch MCP-Server hängen sich auf, und der Client propagiert das Timeout nicht immer gut. In PA haben wir einige MCP-Aufrufe mit Timeout auf Prozessebene umhüllt. Die Lektion: Vertraue nicht auf Timeouts einer einzigen Schicht, stapele mehrere.
Muster 8: Anbieterunabhängiges Design des LLM
Am 4. April 2026 haben wir aus erster Hand den Wert gelernt, die Infrastruktur vom Anbieter zu entkoppeln. An diesem Tag kappte Anthropic die OAuth-Tokens, die die Nutzung der Claude Max- und Pro-Abonnements mit Drittanbieter-harnesses ermöglichten, und mehrere Agenten des Ökosystems waren ohne Backend. Wir erzählen die Geschichte in Von OpenClaw zu PA mit Claude Code und MCP und widmen einen spezifischen Post dem Schritt-für-Schritt-Aufbau von PA mit Claude Code und MCP.
Die Infrastruktur von Nexo war nicht betroffen, weil sie darauf ausgelegt war, anbieterunabhängig zu sein. Die Schlüsselkomponente ist AiGateway, eine Abstraktion, die die LLM-Aufrufe zentralisiert und zur Laufzeit entscheidet, welchen Client sie je nach Verbindung des Workspace und Feature verwendet.
Hinter chat() löst AiGateway eine WorkspaceAiConnection auf, baut den Client (AnthropicClient, OpenAiClient oder ClaudeCliClient für Console-Auth) und emittiert mit dem korrekten Modell. Einen Workspace von Anthropic zu OpenAI zu wechseln, ist eine Konfigurationsänderung, keine Codeänderung.
Drei konkrete Effekte:
Resilienz. Wenn Anthropic eine Störung hat, rotieren wir in Minuten zu OpenAI, ohne Protokoll-Code zu berühren. Am 4. April mussten wir es nicht tun, weil der Ausfall den OAuth von Claude Code betraf, nicht die API, die Nexo nutzt, aber die Fähigkeit war erprobt.
Wahl pro Feature. Chat nutzt Haiku 4.5 wegen der Kosten; Meeting-Zusammenfassungen nutzen Opus 4.7 wegen der Qualität; Vertragsextraktion nutzt GPT-4o wegen seines strukturierten JSON-Modus. Die Abstraktion erlaubt es, jedes Feature separat zu optimieren.
Optimierung pro Workspace. Kleine Workspaces auf günstigen Modellen, Premium-Workspaces auf Premium-Modellen. Entscheidung in workspaces_ai_connections, nicht im Code.
Die Regel: Rufe die API des Anbieters niemals direkt aus Deinem Business-Code auf. Geh immer durch eine eigene Zwischenschicht. Wenn der Anbieter etwas ändert — und er wird — bleibt der Einfluss in dieser Schicht.
Vergleich der LLM-Anbieter Stand April 2026
Diese Tabelle fasst zusammen, wie wir heute die drei großen Top-Tier-Anbieter aus der Perspektive eines Agenten in Produktion sehen. Es ist kein absolutes Ranking — es ist ein Leitfaden dafür, wann es sinnvoll ist, sich auf jeden einzelnen innerhalb einer Multi-Anbieter-Architektur wie der des vorherigen Musters zu stützen.
Vergleich Stand April 2026; Modelle und Preise entwickeln sich schnell.
Als Nächstes zerlegen wir vier Antimuster für KI bei Agenten, die wir Projekte entgleisen gesehen haben — sowohl unsere als auch die von Kunden — wenn eine der oben genannten Disziplinen nicht angewendet wird.
Antimuster 1: Autonomer Agent, der ohne Aufsicht handelt
Die Erzählung des "autonomen Agenten, der allein entscheidet" klingt gut auf Folien und endet schlecht in Vorfällen. Der Grund ist nicht philosophisch, er ist statistisch: Jeder stochastische Prozess (und LLMs sind es) wird Fehler machen, und Fehler ohne menschliche Aufsicht werden zu kumulierten Schäden.
Typische Fehlermodi:
Endlosschleife. Ein Agent, der "entscheidet, was als Nächstes zu tun ist", kann dasselbe Tool 50 Mal hintereinander aufrufen. Ohne eine Obergrenze wie MAX_STEPS = 10 verbraucht die Ausführung Tokens ohne Wert.
Effektkaskade. Eine fehlerhafte Rechnung löst einen Webhook aus, der eine E-Mail an den Kunden sendet, der ein Ticket im CRM öffnet, das das Vertriebsteam benachrichtigt. Die Kette rückgängig zu machen kostet mehr als der ursprüngliche Fehler.
Zustandskorruption. Ein Agent mit Schreibrechten, der eine Anweisung falsch interpretiert, kann Datensätze ändern, die ohne vorheriges Backup unmöglich zu rekonstruieren sind.
Praktische Regel: Kein Agent sollte zu Beginn irreversible Schreibrechte ohne Human-in-the-Loop haben. Den autonomen Modus für spezifische Aktionen zu aktivieren ist nach hunderten verifizierten Runs und Fehlerrate unter der Domänenschwelle möglich. Niemals vorher. Niemals standardmäßig.
Antimuster 2: Dem "unendlichen" Kontext des Modells vertrauen
Die Modelle von 2026 prahlen mit Fenstern von 200K, 500K und bis zu 1M Tokens. Die Botschaft, die durchgedrungen ist, lautet "jetzt kannst Du alles reinpacken". Das ist in Produktion nicht wahr.
Drei Gründe, nicht dem gesamten Fenster zu vertrauen:
Qualitätsverlust bei aufgeblähtem Kontext. Öffentliche Benchmarks und unsere internen Auswertungen zeigen, dass die Recall-Präzision (Needle-in-a-Haystack) sich degradiert, je näher man dem Limit kommt. Ein Modell, das bei 50K Tokens zu 99% einen Datenpunkt findet, kann bei 500K Tokens auf 80% oder weniger sinken.
Kosten proportional zum Input. Ein Kontext von 300K Tokens kostet sechsmal mehr als einer von 50K. Bei 100 täglichen Aufrufen zählt der monatliche Unterschied zwischen "alles passt rein" und "nur das Notwendige" in Hunderten oder Tausenden von Euro.
First-Token-Latenz. Ein Prompt von 300K Tokens kann mehrere Sekunden brauchen, bis er verarbeitet wird, bevor das Modell zu antworten beginnt, sogar mit Prompt Caching. Für Konversationserfahrung tötet es die Geschwindigkeitswahrnehmung.
Disziplin: Der Kontext soll das Minimum Notwendige sein, nicht das Maximum Mögliche. In Brain existieren die data_filter genau dafür, den Kontext zwischen Steps zu reduzieren: Ein connector_fetch kann 500 E-Mails bringen; der Filter reduziert sie auf die 20, die Kriterien erfüllen; der nachfolgende ai_call sieht nur diese 20. Das RAG-Muster entsteht aus derselben Disziplin — für große Dokumentenbasen ist Enterprise RAG die korrekte Architektur, kein riesiger Kontext.
Antimuster 3: Ohne Trennung von Lesen und Schreiben
Agenten, die im selben Step lesen und schreiben, sind tickende Zeitbomben. Wenn der Call auf halbem Weg fehlschlägt, weißt Du nicht, ob der Schreibvorgang ausgeführt wurde. Wenn er wiederholt wird, kannst Du duplizieren. Wenn es einen Interpretationsfehler gibt, hast Du keinen Snapshot des Zustands, den der Agent sah.
Regel: Trenne Lesen und Schreiben in unterschiedliche Steps mit expliziter Materialisierung dazwischen. In Brain spiegelt die Step-Typologie das wider: connector_fetch und db_query sind read-only; action ist die einzige, die schreibt. Ein gut konzipiertes Protokoll hat die Form "N Lese-Steps, 0 oder 1 Schreib-Step am Ende". Wenn Du mehr als einmal schreiben musst, teilst Du das Protokoll in zwei.
In Kundenintegrationen wenden wir dasselbe Muster an: Der Agent generiert einen Vorschlag (Objekt in DB mit dem Entwurf oder der Änderung), und ein zweiter Schritt — mit menschlicher Bestätigung — führt die Aktion aus. Erlaubt Audit, sicheres Retry, Rollback und Human-in-the-Loop ohne Redesign des Flows. Legitime Ausnahme: idempotente Operationen mit natürlichem Schlüssel. Für den Rest: trennen.
Antimuster 4: Ein einziger kritischer LLM-Anbieter
Wir haben es schon in Muster 8 berührt, aber es verdient Hervorhebung: Ein kritischer Agent, der von einem einzigen Anbieter abhängt, ist ein fragiler Agent. Nicht weil der Anbieter schlecht ist, sondern weil jede einseitige Entscheidung — Preisänderung, Policy, Sunset eines Modells, Dienstausfall, OAuth-Abschaltung — Dich ohne Backend zurücklassen kann.
Am 4. April 2026 hat Anthropic OAuth von Claude Max für Dritte gekappt. OpenAI passt API-Preise regelmäßig an. Google ändert Gemini-Kontingente. Es sind keine böswilligen Bewegungen — es sind Geschäftsentscheidungen — aber alle haben denselben Effekt auf den, der unter der Annahme gebaut hat, dass sich nichts ändern würde.
Drei minimale Entkopplungsschichten:
Eigene Abstraktion vom Typ AiGateway. Dein Code spricht mit Deiner Abstraktion, nicht mit dem SDK des Anbieters.
Credentials und Config in DB. Das Modell oder den Anbieter zu wechseln sollte kein Deployment erfordern, sondern ein UPDATE.
Portable Prompts. Wenn Dein Prompt nur mit einem spezifischen Modell funktioniert, hast Du einen fragilen Prompt. Gut geschriebene Prompts (explizite Regeln, strukturiertes Format) funktionieren akzeptabel in den Top-Tier-Modellen der drei Großen. Wenn die Unterschiede groß sind, liegt das Problem am Prompt, nicht am Modell.
Mit diesen drei Schichten kostet Dich die Migration Stunden, nicht Wochen, wenn Anbieter A etwas ändert.
Wie wir diese Muster in den Kiwop-Dienstleistungen anwenden

Diese acht Muster und vier Antimuster sind das Rahmenwerk, mit dem wir KI-Projekte bei Kiwop liefern. Wenn ein Kunde mit "ich will einen Agenten für X" kommt, folgt das Gespräch dieser Reihenfolge:
Erstens, KI-Beratung, um den echten Scope abzugrenzen. Fast immer ist das, was der Kunde verlangt, drei oder vier Agenten, die am Gleichen hängen; die Beratungsarbeit besteht darin, sie zu trennen und zu entscheiden, was autonom ist und was einen menschlichen Handshake erfordert.
Zweitens, Entwicklung von KI-Agenten mit einer Architektur, die die Muster 3 bis 8 standardmäßig anwendet: Limits, MCPs, Anti-Halluzination, Observability, Timeouts, Anbieter-Abstraktion.
Drittens, LLM-Integration auf MCP, wenn vorhanden, und auf eigene Konnektoren, wenn nicht.
Viertens, sobald in Produktion, LLMOps für das Lifecycle-Management: Observability, Kosten pro Workspace, Modell-Rotation, Reaktion auf Vorfälle.
Das Ziel: Dass der Agent, den wir am Tag 1 liefern, am Tag 365 mit vorhersehbaren Kosten noch funktioniert.
Häufig gestellte Fragen
Wann ist es sinnvoll, einen KI-Agenten in Produktion zu bauen?
Wenn es eine wiederholte, semi-strukturierte Aufgabe mit klaren Erfolgskriterien gibt und die dank menschlicher Bestätigung einen kleinen Prozentsatz von Fehlern toleriert. Beispiele: Triage von E-Mails oder Tickets, Lead-Enrichment, Dokumentenextraktion, Meeting-Zusammenfassung, Nachrichtenklassifizierung. Nicht sinnvoll für Aufgaben mit sehr hohen Fehlerkosten ohne Aufsicht, noch für Aufgaben, die mit einer deterministischen Regel ohne LLM lösbar sind.
Welches LLM-Modell für einen Agenten im Jahr 2026 wählen?
Hängt vom Feature ab. Für Chat und Multi-Step mit Kostenpriorität Haiku 4.5 oder GPT-4o-mini. Für komplexes Reasoning und Qualitätsextraktion Sonnet 4.5, Opus 4.7 oder GPT-4o. Für strenges JSON GPT-4o wegen seines nativen Modus. Beginne mit dem günstigsten Modell, das Deine eigenen Evaluierungen besteht, und steige nur auf, wenn die Daten es rechtfertigen.
Was kostet es, einen KI-Agenten in Produktion zu deployen?
Entwicklung zwischen 6.000 und 15.000 Euro für einen Narrow-Scope-Agenten mit existierenden MCPs (steigt mit maßgeschneiderten Integrationen). Betriebskosten: ein Agent von ~500 täglichen Interaktionen auf Haiku 4.5 kann sich bei 50-150 Euro monatlich in Tokens bewegen; auf Opus 4.7 kann sich die Rechnung um das 10-fache oder mehr vervielfachen. Konzipiere für niedrige Kosten und steigere nur, wo es sichtbaren Wert hinzufügt.
Ist ein KI-Agent sicher, der Kundendaten berührt?
Er kann es sein: (1) sensible Daten vor dem Prompt überprüft; (2) irreversible Aktionen mit menschlicher Bestätigung; (3) jeder Run auditiert mit Nachverfolgbarkeit. Für regulierte Inhalte (Gesundheit, Recht, Finanzen mit Berufsgeheimnis) On-Premise- oder regionale Modelle mit spezifischen Trainingsausschluss-Vereinbarungen bewerten. Ein Enterprise RAG-Projekt mit kontrollierter Infrastruktur ist oft die richtige Option.
Wie verhindere ich, dass mein Agent Daten halluziniert?
Mehrere Schichten: (1) Prompt mit wörtlichen Anti-Halluzinations-Regeln ("wenn Du den Datenpunkt nicht hast, gib null zurück"); (2) Vertrauen und Beweis pro Feld für auditierbaren Output; (3) strukturierte Formate mit geschlossenen Enums; (4) deterministische Validierung vor kritischen Systemen; (5) menschliche Bestätigung bei irreversiblen Operationen. Keine allein reicht; die fünf zusammen reduzieren Halluzination auf tolerierbare Niveaus.
Was ist ein Brain-Protokoll in Nexo?
Ein deklarativer Workflow mit typisierten Steps (connector_fetch, data_filter, ai_call, db_query, action, condition), die sequenziell mit mutablem Kontext ausgeführt werden. Im Gegensatz zu einem "Alleskönner"-Agenten, der entscheidet, welches Tool er aufruft, ist ein Protokoll in der Sequenz deterministisch, aber flexibel innerhalb jedes Steps. Harte Limits (MAX_STEPS = 10, MAX_CONTEXT_CHARS = 300000) und jeder Run in BrainProtocolRun auditiert mit Tokens, Latenz pro Step, Trigger Source und Ergebnis.
Was mache ich, wenn mein LLM-Anbieter Preise oder eine Zugriffsmodalität ändert?
Wenn Du entkoppelt bist (Muster 8), ist Rotieren Konfiguration: Verifiziere, dass die Prompts mit dem neuen Modell funktionieren, und bewerte Kosten neu. Wenn Du es nicht warst, führe zuerst die Abstraktionsschicht ein, trenne Credentials in Config und teste die Prompts bei mindestens zwei Anbietern. Die Arbeit amortisiert sich sehr schnell das erste Mal, wenn sie einen Vorfall verhindert.
Kann ich mit einem autonomen Agenten beginnen und Bestätigung später hinzufügen?
Umgekehrt: Beginne mit menschlicher Bestätigung bei allen irreversiblen Aktionen und aktiviere autonom nur, wenn Du Daten niedriger Fehlerrate hast. Bestätigung nach einem Vorfall hinzuzufügen ist teurer, als sie zu entfernen, wenn der Agent Zuverlässigkeit beweist, vor allem in sensiblen Bereichen (Geld, Kunden-E-Mails, CRM).
Fazit: Die Muster skalieren, die Antimuster auch
2026 ist das erste Jahr, in dem KI-Agenten zu Infrastruktur geworden sind: nicht das Neue, das wir ausprobieren, sondern das, was wir hatten und brauchen, dass es weiterläuft. Dieser Statuswechsel bringt aus der klassischen Ingenieurskunst geliehene Disziplinen mit sich — Observability, explizite Limits, Trennung der Verantwortlichkeiten, Entkopplung vom Anbieter — die der Hype von 2024 in den Hintergrund gedrängt hatte.
Die acht Muster und vier Antimuster dieses Artikels sind das, was in unserer Erfahrung einen Agenten, der zwölf Monate in Produktion überlebt, von einem trennt, der nach drei neu gebaut werden muss. Die teuersten Antimuster für KI sind nicht die technischen Fehler, sondern die Designentscheidungen: Autonomie ohne Aufsicht geben, dem unendlichen Kontext vertrauen, Lesen und Schreiben mischen oder sich an einen einzigen Anbieter binden. Der Wert liegt nicht im Modell oder im Prompt — er liegt in der Infrastruktur, die den Prompt umgibt und ihn am Tag 365 korrekt, auditierbar, günstig und ersetzbar macht.
Wenn Du Deinen ersten Agenten startest oder bereits einen hast und vermutest, dass er Dich mehr kostet in der Wartung, als er Dir hilft, machen wir bei Kiwop — Digitalagentur spezialisiert auf Softwareentwicklung und angewandte Künstliche Intelligenz für globale Kunden in Europa und den USA — Entwicklung von KI-Agenten, KI-Beratung, LLM-Integration und LLMOps als koordinierte Teile eines einzigen Prozesses.