AI-agenten in productie 2026: patronen en antipatronen na deployment in Nexo, PA en klantprojecten
Door het team van Kiwop · Digital Agency gespecialiseerd in Softwareontwikkeling en toegepaste Kunstmatige Intelligentie voor wereldwijde klanten in Europa en de VS · Gepubliceerd op 19 april 2026 · Laatst bijgewerkt: 19 april 2026
TL;DR — Vijftien maanden AI-agenten deployen in Nexo, PA en klanten leveren ons 8 patronen en 4 antipatronen op. Sleutelregels: narrow scope wint van generalist, menselijke bevestiging vóór onomkeerbare acties en nooit lock-in met één enkel LLM. Als je al een agent in productie hebt of er een op het punt staat uit te rollen, hier is het volledige kader.

2026 is het eerste jaar waarin AI-agenten ophouden conferentie-demo's te zijn en infrastructuur worden die iemand om 3 uur 's nachts moet herstarten wanneer een step faalt. Bij Kiwop bouwen we sinds januari 2025 agenten die in productie leven: binnen onze eigen SaaS Nexo, als interne tools van het team en in klantprojecten.
Dit artikel bundelt de architectuurbeslissingen die die vijftien maanden hebben overleefd. Elk patroon komt voort uit een concreet incident, een kost die we niet nog eens wilden betalen of een klacht die ons dwong te heroverwegen. Elk antipatroon is iets wat we minstens één keer verkeerd hebben gedaan. Als je op het punt staat je eerste agent te deployen, of als je er al een hebt en het onderhoud meer kost dan de initiële ontwikkeling, is dit de gids die we zelf graag hadden gehad toen we begonnen.
Context: waar we AI-agenten hebben gedeployed bij Kiwop
Voordat we patronen induiken, een kaart van waar de data vandaan spreekt. De AI-agenten in productie van Kiwop per april 2026 vallen in drie categorieën uiteen.
Agenten in Nexo, onze multi-tenant SaaS (HR, CRM, projecten, facturatie). Binnen Nexo draaien twee families: Brain protocols, een multi-step workflow-engine per klant en workspace, en de contractenextractor met AI die PDF's verwerkt om contractaanmaak en facturatiemijlpalen te automatiseren. Brain heeft enkele tientallen actieve protocollen verdeeld over klantworkspaces; de extractor verwerkt enkele honderden documenten per maand.
PA, de interne persoonlijke assistent. Gedetailleerd in Van OpenClaw naar PA met Claude Code en MCP, verbindt IMAP-mail, Gmail, Slack, Telegram en Google Calendar met een persistente Claude Code-sessie. Hij wordt dagelijks gebruikt door meerdere teamleden en verwerkt in totaal iets meer dan 1.000 interacties per dag.
Klantintegraties. Agenten op maat: een ticket-triage-agent voor een fintech-klant, een lead-enrichment-agent voor een e-commerce-klant en een juridische-documentatie-consultatie-agent voor een consultancy-klant. Samen schommelen ze rond de 200-400 uitvoeringen per dag.
LLM's die we gebruiken. We combineren modellen van Anthropic (Haiku 4.5, Sonnet 4.5, Opus 4.7) voor de meeste conversationele en redeneertaken, en modellen van OpenAI (GPT-4o en GPT-4o-mini) voor gestructureerde extractie en kostgevoelige workloads. De keuze wordt per feature en per workspace gemaakt via een AiGateway die we verderop zullen zien.
Patroon 1: narrow scope wint altijd van generalist
De eerste verleiding is een agent bouwen die "alles doet" — mail lezen, agenda raadplegen, CRM bijwerken, Slack beantwoorden, vergaderingen samenvatten. Eén enkele enorme prompt, één enkele agent. In de demo ziet het er spectaculair uit; in productie overleeft het niet. Wanneer de agent te veel dekt, raakt de prompt vol tegenstrijdige instructies, verliest het LLM precisie en is het onmogelijk te achterhalen in welke sub-taak iets faalde wanneer er iets misgaat. Erger: de instructie "hoe je een mail samenvat" wijzigen kan die van "hoe je een Slack-bericht schrijft" veranderen.
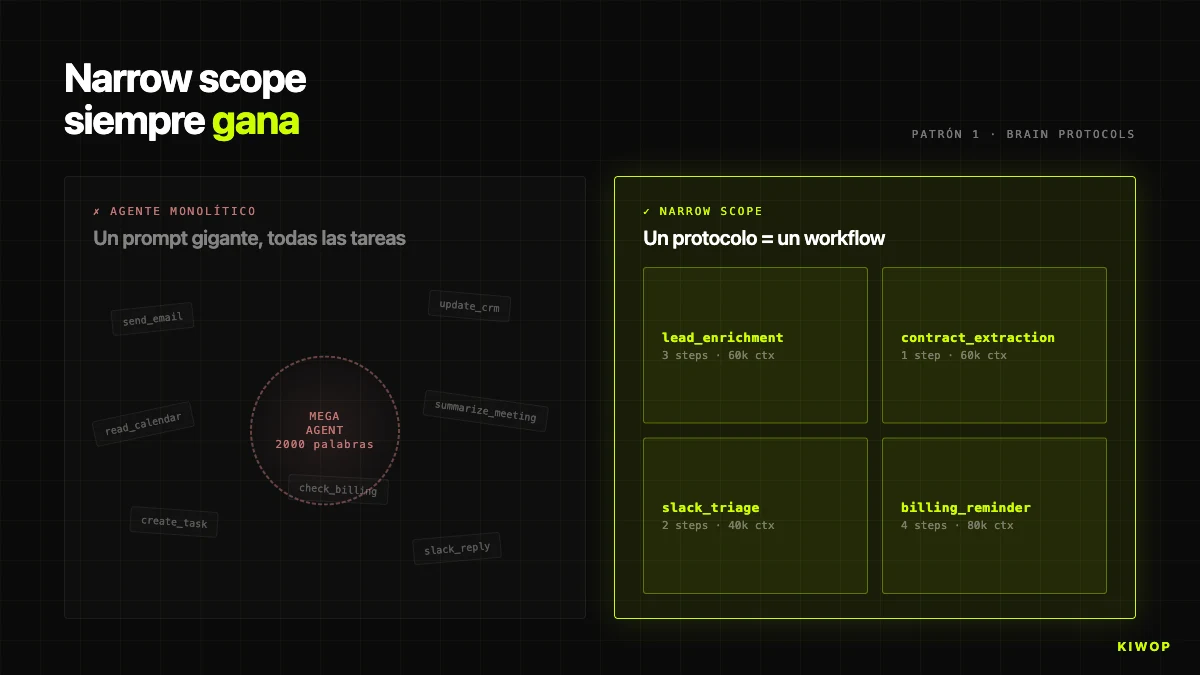
In Brain is de regel expliciet: één protocol = één workflow. Elk protocol heeft één uniek doel — lead_enrichment, contract_extraction_followup, project_health_check, weekly_billing_reminder. Als er een nieuw gebruiksscenario opkomt, wordt een nieuw protocol aangemaakt, geen bestaand uitgebreid. Wanneer een klant vraagt "dat enrichment ook een Slack stuurt", is het juiste antwoord een tweede gekoppeld protocol aan te maken, niet de eerste op te blazen.
Dat is merkbaar in de code van de BrainProtocolEngine: elk protocol heeft zijn eigen steps, zijn trigger_config, zijn project_id en zijn workspace_id. Als enrichment faalt voor een specifieke lead, blijven de andere protocollen van dezelfde workspace doorlopen zonder iets te merken.
Het tegengestelde antipatroon — "de agent die alles doet" — komt vaak voor in klantvoorstellen: "een copilot voor het commerciële team die mail leest, CRM raadpleegt, voorstellen stuurt, opvolgt, waarschuwt bij verlengingen". Ons standaardantwoord is dat verzoek te tekenen als vijf of zes onafhankelijke agenten georkestreerd met gekoppelde protocollen. Het verschil in total cost of ownership over twaalf maanden is gemakkelijk 3x of 4x. Als je agent een systeem-prompt van 2.000 woorden nodig heeft om te werken, heb je vrijwel zeker meerdere agenten aan elkaar geplakt met ducttape. Scheid ze.
Patroon 2: menselijke bevestiging vóór onomkeerbare acties
Moderne LLM's maken ongeveer 1% van de tijd fouten in gesloten taken die als "makkelijk" worden beschouwd. Het is geen door ons met rigueur gemeten getal — het is de orde van grootte van publieke benchmarks en komt overeen met onze interne ervaring. Klinkt laag totdat je de rekensom maakt.
Een agent die 1.000 operaties per dag uitvoert met 1% fout produceert 10 foutieve operaties per dag. Als het lees-operaties zijn, is de kost nul. Als het schrijf-operaties zijn (een mail sturen, een evenement aanmaken, een record wijzigen, iets verwijderen), kan de kost oplopen van een ongemak tot een post mortem. Tien incidenten per dag zijn onhoudbaar.
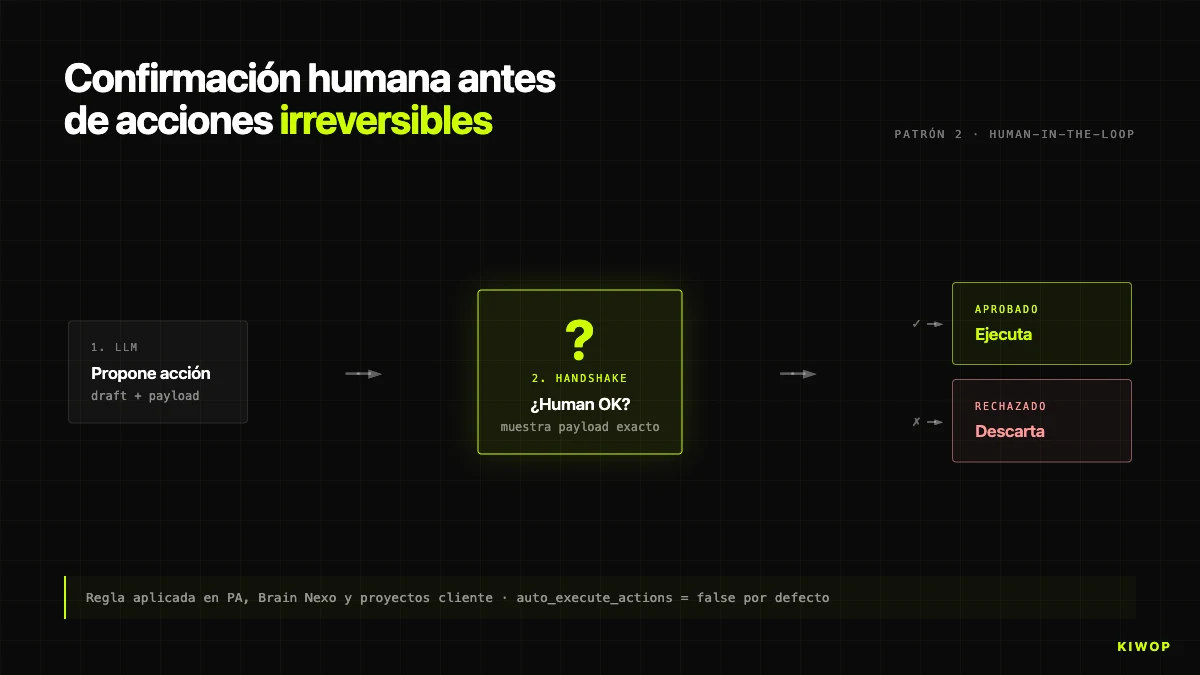
De regel zonder uitzonderingen: de agent voert nooit onomkeerbare acties uit zonder expliciete menselijke bevestiging. In PA, beschreven in de post over de persoonlijke assistent, kan de agent de volledige mailbox lezen maar verstuurt hij niets zonder dat de mens "ja" schrijft. In Brain is het equivalent de flag auto_execute_actions in BrainProtocol: standaard op false, wanneer een step een action genereert (taak, voorstel, alert aanmaken), is wat wordt aangemaakt een AgentProposal in afwachting van goedkeuring, niet de uiteindelijke actie.
We schakelen auto_execute_actions = true alleen in wanneer aan drie voorwaarden is voldaan: (1) de actie is idempotent en omkeerbaar, (2) na enkele honderden handmatig geverifieerde runs blijft de waargenomen foutratio onder 1%, hoewel de meting methodologisch niet rigoureus is, en (3) de klant tekent de activering schriftelijk. Per april 2026 draait minder dan een kwart van de protocollen in autonome modus.
Een valkuil: de bevestiging mag niet zijn "weet je het zeker? [ja/nee]" want de gebruiker went eraan en klikt zonder te lezen. De goed ontworpen handshake toont exact wat er gaat gebeuren (ontvanger, onderwerp, body van de mail; te wijzigen DB-entiteit; exact bedrag). Als de mens moet weten wat hij bevestigt, wordt gelezen wat wordt bevestigd.
Dit patroon sluit aan bij AI-consultancy: het gesprek begint bij "welke acties mag de agent ondernemen zonder te vragen?" en bijna altijd schiet het initiële antwoord tekort. Permissies uitbreiden is makkelijk, ze intrekken na een incident is duur.
Patroon 3: strikte limieten op context en steps
Multi-step agenten zijn gulzig. Elke step voegt informatie toe aan de context, elke oproep kan lange antwoorden teruggeven, en zonder een expliciet plafond groeit de context tot een van drie problemen je treft: disproportionele kosten, hallucinatie door opgeblazen context of timeout van de provider.
In BrainProtocolEngine hebben we twee harde constanten:
MAX_STEPS = 10 betekent dat een protocol niet meer dan 10 steps per run kan uitvoeren, ongeacht hoeveel er gedefinieerd zijn. Protocollen met meer dan 10 steps zijn bijna altijd een ontwerp dat beter opgesplitst had kunnen worden in twee gekoppelde; de limiet dwingt dat gesprek af.
MAX_CONTEXT_CHARS = 300000 geldt voor de totale opgebouwde context. Als de JSON de 300.000 karakters overschrijdt, wordt er een warning gelogd en wordt de prompt afgekapt met een expliciete boodschap aan het model: "CONTEXTO TRUNCADO POR LÍMITE DE TAMAÑO". De limiet is gekalibreerd om comfortabel in een venster van 200K tokens te passen en weg te blijven van de 1M van modellen met uitgebreide context — omdat, zoals we later zullen zien, grote context en nuttige context heel verschillende dingen zijn.
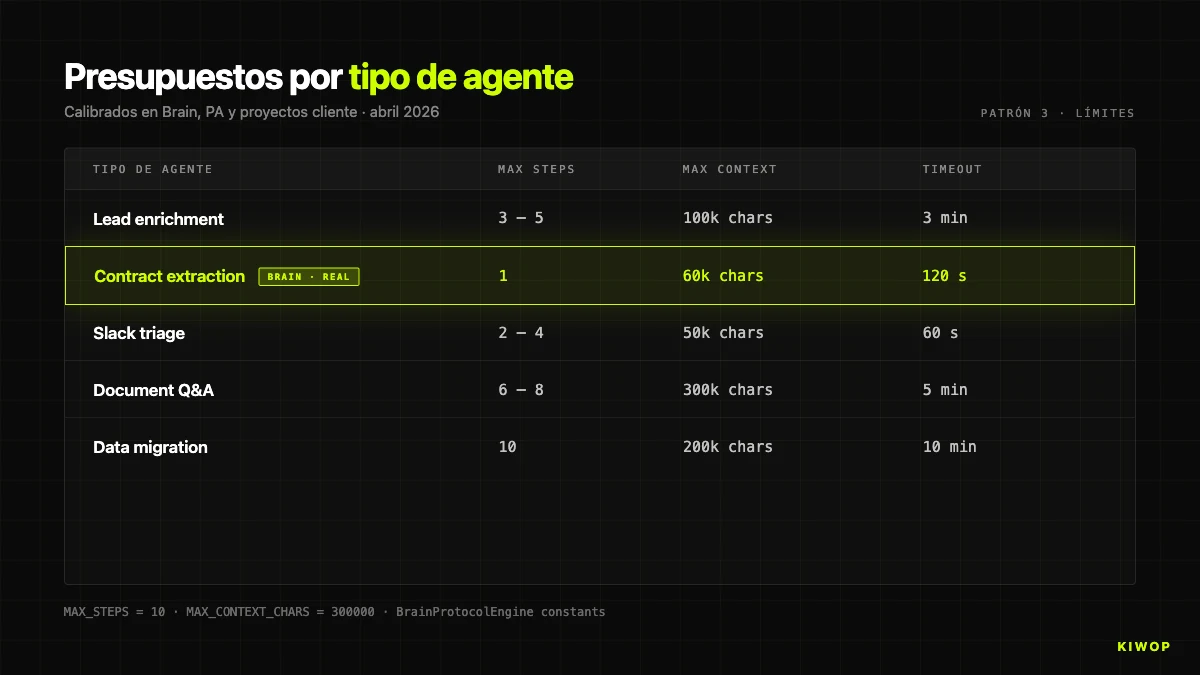
Als oriënterende referentie, dit zijn de standaardbudgetten die we gebruiken per agenttype:
Deze waarden zijn niet universeel — het zijn de waarden die de productietest in onze workloads hebben doorstaan. Als je begint, start conservatief en verhoog alleen wanneer je data hebt die het rechtvaardigen.
Patroon 4: MCP als gemeenschappelijke taal vóór ad-hoc-integraties
Vóór 2025 was elke integratie tussen een agent en een extern systeem code op maat: een connector voor Gmail, een andere voor Calendar, een andere voor Slack, elk met zijn eigen authenticatie en onderhoud. Het grootste deel van de kost van een agent bouwen kwam niet van de prompt of het model, maar van glue code.
Model Context Protocol (MCP) veranderde dat in 2025 en heeft zijn positie geconsolideerd in 2026. MCP is een open standaard waardoor elk model met elke tool kan praten met dezelfde grammatica van "tool calls". Gepubliceerd door Anthropic in 2024, geadopteerd door OpenAI, Google en de belangrijkste AI-clients. Tegenwoordig steunt de meerderheid van integraties die we bouwen op bestaande MCP-servers in plaats van nieuwe clients te schrijven.
De impact op ontwikkelkosten is brutaal. Voor een agent die met Gmail, Calendar, Drive, Slack, Linear en GitHub moet praten, is het verschil tussen zes eigen connectoren met hun OAuth's schrijven en zes bestaande MCP-servers aansluiten in de orde van weken versus uren. En het onderhoud — wanneer een service een endpoint wijzigt of credentials roteert — houdt op jouw probleem te zijn.
Als je niet duidelijk hebt wat MCP is, legt WebMCP: jouw website klaar voor AI-agenten het uit met concrete voorbeelden. Voor de vergelijking met zusterprotocollen gaat MCP, WebMCP en A2A: de protocollen die AI-agenten in 2026 definiëren in op de details.
Operationele regel: voordat je een eigen connector schrijft, controleer of er een officiële of community-MCP bestaat. Als hij bestaat en door een serieus team wordt onderhouden, gebruik hem. MCP is geen wondermiddel — het heeft blinde vlekken (zakelijke IMAP, Telegram, verticale CRM's). Voor die gaten schrijven we eigen scripts, maar in de vorm van een MCP zodat, als iemand er morgen een publiceert, de overstap pijnloos is.
Patroon 5: expliciete anti-hallucinatie in de prompt
LLM's hallucineren. Het is een architecturaal kenmerk van de transformer, geen bug die met het volgende model zal verdwijnen. Elke agent die echte data behandelt moet met die realiteit leven.
De strategie die het beste heeft gewerkt voor ons is de anti-hallucinatie-regels direct in de systeem-prompt inschrijven, letterlijk en redundant. Niet "wees alstublieft precies". Genummerde regels, met kritieke termen in hoofdletters, met operationele instructies over wat te doen bij twijfel.
Het duidelijkste voorbeeld in productie is de contractenextractor van Nexo. De systeem-prompt van de OpenAiContractExtractor start met deze instructies:
CRITICAL RULES: 1. NEVER invent or hallucinate data. If a field is not clearly stated, return null. 2. Return ONLY valid JSON. No explanations outside the JSON. 3. For each field, provide: - value: The extracted value (or null if not found) - confidence: A score from 0.0 to 1.0 indicating how confident you are - evidence: A brief quote from the document supporting your extraction (or null) 4. Dates MUST be in YYYY-MM-DD format. If day/month is unclear, return null.
Drie mechanismen komen in het spel:
Het model toestaan "ik weet het niet" te zeggen. null teruggeven wanneer een gegeven onduidelijk is, is een geldig resultaat; het verzinnen niet. Veel mensen schrijven prompts zonder expliciete uitgang naar "gegeven niet beschikbaar" en het model, gedwongen, vult het in met het meest plausibele dat het vindt.
Confidence en evidence per veld vragen. De confidence dwingt het model tot meta-redenering over zijn zekerheid. De evidence — letterlijk citaat uit het document — is verifieerbaar: als het citaat niet voorkomt, wordt het veld verworpen. De output wordt auditeerbaar in plaats van black box.
Strikt gestructureerde formaten. Datums in YYYY-MM-DD, getallen als numerieke types, gesloten enumeraties ("fixed" | "hourly" | "monthly"). Hoe geslotener het formaat, hoe minder ruimte voor creatieve hallucinatie.
Deze strategie elimineert hallucinatie niet, maar reduceert het tot tolerabele niveaus met menselijke bevestiging. In onze interne data verlaagde de overgang van losse prompts naar prompts met letterlijke anti-hallucinatie-regels de vals ingevulde velden met ongeveer een factor vijf, zonder het model te veranderen.
Patroon 6: verplichte observability
De eerste keer dat een klant vraagt "waarom deed de agent dat?" en je geen data hebt om te antwoorden, leer je dat observability niet optioneel is. Elke uitvoering moet een auditeerbaar spoor achterlaten: tokens, latency, uitgevoerde steps, inputs, outputs, wie triggerde en van waar.
In Brain wordt dit geïmplementeerd met BrainProtocolRun. Elke uitvoering creëert een record met:
status:running | completed | failed | cancelledstep_results: array met een object per uitgevoerde step (naam, type, duur in ms, status, resultaat of fout)context: de opgebouwde context, afgekapt tot 50.000 karakters voor opslagcurrent_step: in welke step hij was toen hij voltooide of faaldetokens_used: totaal verbruikte tokens (som input + output van alleai_call)started_at/completed_attriggered_by_user_id/trigger_source: wie en vanaf welk kanaal triggerde de runerror: als hij faalde, het volledige bericht
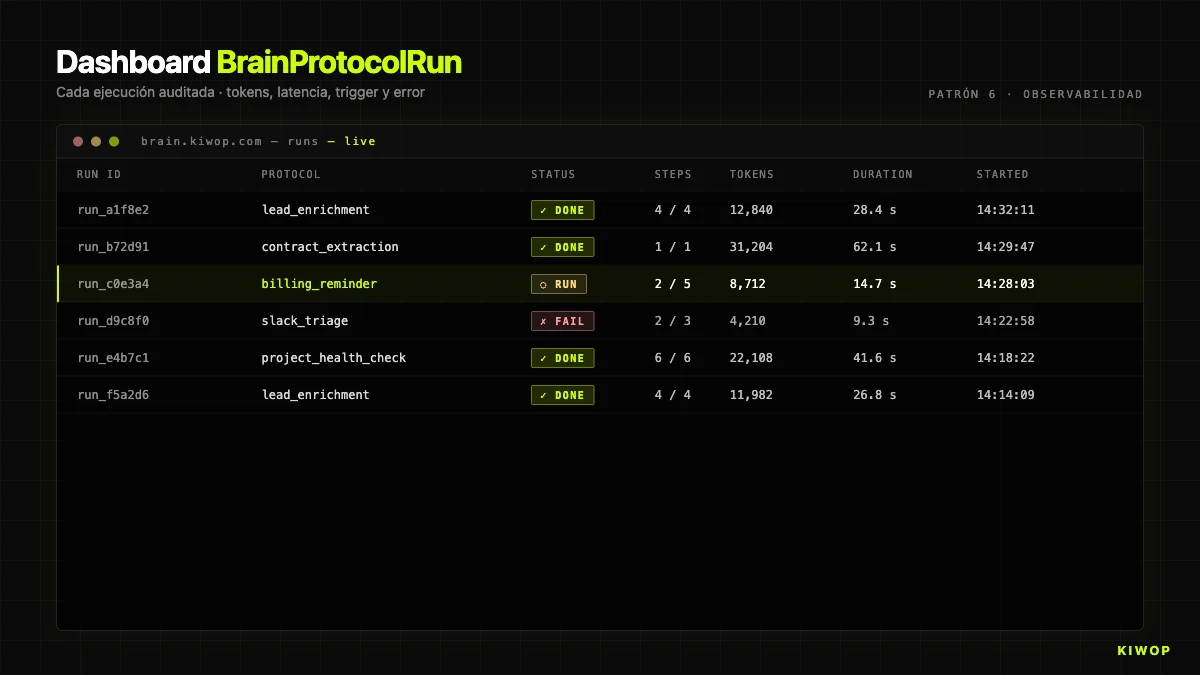
Die structuur beantwoordt de drie vragen die altijd gesteld worden: hoeveel kost het? (som van tokens_used × prijs per token), waarom faalde het? (error + step_results tot de falende step), waarom duurde het zo lang? (duration_ms per step).
Twee extra regels geleerd via de pijnlijke weg:
Logs die heet te raadplegen zijn. Bestanden die niemand bekijkt zijn nutteloos. De applicatieve DB is oké voor laag-middelmatig volume; voor hoog volume betaalt een toegewijde stack (Datadog, Grafana, Honeycomb) de kost terug vóór het eerste grote incident.
Bewaar altijd `trigger_source` en `triggered_by_user_id`. Wanneer er iets misgaat, is de eerste vraag forensisch: heeft de scheduler, een gebruiker, een externe integratie, een webhook het getriggerd? Zonder die traceerbaarheid is elk incident een archeologisch onderzoek.
Dit patroon staat centraal in ons LLMOps-aanbod: modellen in productie beheren is niet de modellen beheren — het is de telemetrie, de kosten, de kwaliteit en de beveiliging van de agenten die ze gebruiken beheren.
Patroon 7: agentic timeouts met exponentiële retry
Externe LLM's falen — piekvraag, netwerkonderbrekingen, vastgelopen sessies. Een agent die geen expliciete timeouts afhandelt is een agent die blijft hangen, en een hangende agent is erger dan een falende: de mens weet niet wat er gebeurt.
Drie componenten in ons beleid:
Expliciete timeouts per step. In Brain definieert elke ai_call zijn max_tokens en effectieve timeout. Clientdefault: 120 seconden. Als een step die overschrijdt, markeert de engine hem als failed in plaats van de run te laten hangen.
Exponentiële retry met limiet. Voor transiënte fouten (rate limit, 5xx, netwerk-timeouts) retryen we met backoff: delay = base * 2^attempt + jitter, base = 500ms, maximaal 3 retries, plafond 30 seconden. Absorbeert blips zonder de provider te hameren.
Snel falen bij niet-herstelbare fouten. De 4xx (ongeldige input, verlopen credentials, quota uitgeput) worden niet opnieuw geprobeerd — de volgende poging faalt hoe dan ook. Als de step critical: true is gemarkeerd, wordt het volledige protocol afgebroken.
Opmerking voor MCP-agenten: MCP-servers hangen ook, en de client propageert de timeout niet altijd goed. In PA hebben we enkele MCP-oproepen gewikkeld met een timeout op procesniveau. De les: vertrouw niet op timeouts van één enkele laag, stapel er meerdere.
Patroon 8: LLM-provider-agnostisch ontwerp
Op 4 april 2026 leerden we uit eerste hand de waarde van infrastructuur die ontkoppeld is van de provider. Die dag sneed Anthropic de OAuth-tokens af waarmee Claude Max- en Pro-abonnementen konden worden gebruikt met third-party harnesses, en verschillende agenten in het ecosysteem stonden zonder backend. We vertellen het verhaal in Van OpenClaw naar PA met Claude Code en MCP en wijdden een specifieke post aan de stap-voor-stap-bouw van PA met Claude Code en MCP.
De infrastructuur van Nexo werd niet getroffen omdat ze ontworpen was om provider-agnostisch te zijn. Het sleutelcomponent is AiGateway, een abstractie die de LLM-oproepen centraliseert en runtime beslist welke client te gebruiken afhankelijk van de workspace-verbinding en de feature.
Achter chat(), lost AiGateway een WorkspaceAiConnection op, bouwt de client (AnthropicClient, OpenAiClient of ClaudeCliClient voor console-auth) en emit met het juiste model. Een workspace van Anthropic naar OpenAI wisselen is een configuratiewijziging, geen code.
Drie concrete effecten:
Veerkracht. Als Anthropic een incident heeft, roteren we binnen minuten naar OpenAI zonder protocolcode aan te raken. Op 4 april hoefden we het niet te doen omdat de onderbreking de OAuth van Claude Code betrof, niet de API die Nexo gebruikt, maar de capaciteit was getest.
Keuze per feature. Chat gebruikt Haiku 4.5 vanwege kosten; vergadersamenvattingen gebruiken Opus 4.7 vanwege kwaliteit; contractenextractie gebruikt GPT-4o vanwege de gestructureerde JSON-modus. De abstractie maakt het mogelijk elke feature afzonderlijk te optimaliseren.
Optimalisatie per workspace. Kleine workspaces op goedkope modellen, premium workspaces op premium modellen. Beslissing in workspaces_ai_connections, niet in code.
De regel: roep nooit de API van de provider rechtstreeks aan vanuit je business-code. Ga altijd door een eigen tussenlaag. Wanneer de provider iets verandert — en hij gaat veranderen — blijft de impact in die laag.
Vergelijking van LLM-providers per april 2026
Deze tabel vat samen hoe we vandaag de drie grote tier-top providers zien vanuit het perspectief van een agent in productie. Het is geen absolute ranking — het is een gids voor wanneer het zinvol is op elk te steunen binnen een multi-provider-architectuur zoals in het vorige patroon.
Vergelijking per april 2026; modellen en prijzen evolueren snel.
Hieronder behandelen we vier AI-antipatronen van agenten die we projecten hebben zien laten ontsporen — zowel onze als die van klanten — wanneer een van de voorgaande disciplines niet wordt toegepast.
Antipatroon 1: autonome agent die zonder toezicht handelt
Het verhaal van de "autonome agent die alleen beslist" klinkt goed in slides en eindigt slecht in incidenten. De reden is niet filosofisch, ze is statistisch: elk stochastisch proces (en LLM's zijn dat) zal fouten maken, en fouten zonder menselijk toezicht worden geaccumuleerde schade.
Typische faalmodi:
Oneindige lus. Een agent die "beslist wat hij vervolgens zal doen" kan dezelfde tool 50 keer achter elkaar aanroepen. Zonder een plafond als MAX_STEPS = 10 verbruikt de uitvoering tokens zonder waarde.
Cascade van effecten. Een foute factuur triggert een webhook die mail stuurt naar de klant, die een ticket opent in CRM, die het commerciële team waarschuwt. De keten terugdraaien kost meer dan de oorspronkelijke fout.
Statuscorruptie. Een agent met schrijfrechten die een instructie verkeerd interpreteert kan records wijzigen die onmogelijk te reconstrueren zijn zonder eerdere back-up.
Praktische regel: geen enkele agent zou onomkeerbare schrijfrechten mogen hebben zonder human-in-the-loop aan het begin. Autonome modus inschakelen voor specifieke acties is mogelijk na honderden geverifieerde runs en een foutratio onder de domeindrempel. Nooit eerder. Nooit standaard.
Antipatroon 2: vertrouwen op de "oneindige" context van het model
De modellen van 2026 pronken met vensters van 200K, 500K en zelfs 1M tokens. De boodschap die is doorgedrongen is dat "je er nu in kunt zetten wat je wilt". Dat is niet waar in productie.
Drie redenen om niet op het volledige venster te vertrouwen:
Kwaliteitsdegradatie met opgeblazen context. Publieke benchmarks en onze interne evaluaties tonen dat retrieval-precisie (needle-in-a-haystack) degradeert bij het naderen van de limiet. Een model dat een gegeven met 99% vindt bij 50K tokens kan zakken tot 80% of minder bij 500K tokens.
Kosten evenredig aan input. Een context van 300K tokens kost zes keer meer dan een van 50K. Met 100 dagelijkse oproepen telt het maandelijkse verschil tussen "alles past" en "alleen het nodige" in honderden of duizenden euro's.
Latency van de first-token. Een prompt van 300K tokens kan meerdere seconden duren om verwerkt te worden voordat het model begint te antwoorden, zelfs met prompt caching. Voor conversationele ervaring doodt dit de perceptie van snelheid.
Discipline: de context moet het minimum zijn dat nodig is, niet het maximum dat mogelijk is. In Brain bestaan de data_filter precies om de context tussen steps te reduceren: een connector_fetch kan 500 mails ophalen; het filter reduceert ze tot de 20 die voldoen aan de criteria; de volgende ai_call ziet alleen die 20. Het RAG-patroon komt voort uit dezelfde discipline — voor grote documentbases is enterprise RAG de juiste architectuur, geen gigantische context.
Antipatroon 3: geen scheiding van lezen en schrijven
Agenten die in dezelfde step lezen en schrijven zijn een tijdbom. Als de oproep halverwege faalt, weet je niet of het schrijven is uitgevoerd. Als je het opnieuw probeert, kun je dupliceren. Als er een interpretatiefout is, heb je geen snapshot van de staat die de agent zag.
Regel: scheid lezen en schrijven in verschillende stappen met expliciete materialisatie ertussen. In Brain weerspiegelt de step-typologie dit: connector_fetch en db_query zijn read-only; action is de enige die schrijft. Een goed ontworpen protocol heeft de vorm "N leesstappen, 0 of 1 schrijfstap aan het eind". Als je meer dan één keer moet schrijven, splits je het protocol in tweeën.
In klantintegraties passen we hetzelfde patroon toe: de agent genereert een voorstel (object in DB met het concept of de wijziging), en een tweede stap — met menselijke bevestiging — voert de actie uit. Maakt audit, veilige retry, rollback en human-in-the-loop mogelijk zonder de flow opnieuw te ontwerpen. Legitieme uitzondering: idempotente operaties met natuurlijke sleutel. Voor de rest, scheid.
Antipatroon 4: één enkele kritieke LLM-provider
We hebben het al aangeraakt in patroon 8, maar het verdient onderstreping: een kritieke agent die van één enkele provider afhangt is een kwetsbare agent. Niet omdat de provider slecht is, maar omdat elke unilaterale beslissing — prijswijziging, beleid, modelsunset, servicestoring, OAuth-onderbreking — je zonder backend kan laten.
Op 4 april 2026 onderbrak Anthropic OAuth van Claude Max voor derden. OpenAI past API-prijzen periodiek aan. Google wijzigt Gemini-quota's. Het zijn geen kwaadwillige bewegingen — het zijn bedrijfsbeslissingen — maar ze hebben allemaal hetzelfde effect op wie bouwde veronderstellend dat niets zou veranderen.
Drie minimale ontkoppelingslagen:
Eigen abstractie à la AiGateway. Je code praat met jouw abstractie, niet met de SDK van de provider.
Credentials en config in DB. Een model of provider wisselen zou geen deploy moeten vereisen, maar een UPDATE.
Portable prompts. Als je prompt alleen werkt met een specifiek model, heb je een kwetsbare prompt. Goed geschreven prompts (expliciete regels, gestructureerd formaat) werken acceptabel in de tier-top modellen van de drie groten. Als de verschillen groot zijn, zit het probleem in de prompt, niet in het model.
Met deze drie lagen kost de migratie, wanneer provider A iets verandert, uren, geen weken.
Hoe we deze patronen toepassen in de diensten van Kiwop

Deze acht patronen en vier antipatronen vormen het kader waarmee we AI-projecten bij Kiwop leveren. Wanneer een klant komt met "ik wil een agent voor X", volgt het gesprek deze volgorde:
Eerst, AI-consultancy om de werkelijke scope af te bakenen. Bijna altijd wat de klant vraagt zijn drie of vier agenten aan hetzelfde vastgeklonken; het consultancy-werk is ze te scheiden en te beslissen wat autonoom is en wat menselijke handshake vereist.
Ten tweede, ontwikkeling van AI-agenten met een architectuur die standaard de patronen 3 tot 8 toepast: limieten, MCP's, anti-hallucinatie, observability, timeouts, provider-abstractie.
Ten derde, LLM-integratie op MCP wanneer die bestaat en op eigen connectoren wanneer niet.
Ten vierde, eenmaal in productie, LLMOps om de levenscyclus te beheren: observability, kosten per workspace, modelrotatie, incidentrespons.
Het doel: dat de agent die we op dag 1 opleveren op dag 365 nog steeds werkt met voorspelbare kosten.
Veelgestelde vragen
Wanneer is het zinvol een AI-agent in productie te bouwen?
Wanneer er een semi-gestructureerde repetitieve taak is, met duidelijke succescriteria en die een klein foutpercentage toelaat dankzij menselijke bevestiging. Voorbeelden: mail- of ticket-triage, lead-enrichment, documentextractie, vergadersamenvattingen, berichtclassificatie. Niet zinvol voor taken met zeer hoge foutkost zonder toezicht, noch voor taken die oplosbaar zijn met een deterministische regel zonder LLM.
Welk LLM-model te kiezen voor een agent in 2026?
Het hangt af van de feature. Voor chat en multi-step met kostprioriteit, Haiku 4.5 of GPT-4o-mini. Voor complexe redenering en kwaliteitsextractie, Sonnet 4.5, Opus 4.7 of GPT-4o. Voor strikte JSON, GPT-4o vanwege zijn native modus. Begin met het goedkoopste model dat jouw eigen evaluaties doorstaat en stijg alleen naar een hogere tier wanneer de data het rechtvaardigen.
Hoeveel kost het om een AI-agent in productie te deployen?
Ontwikkeling tussen 6.000 en 15.000 euro voor een narrow-scope-agent met bestaande MCP's (hoger met integraties op maat). Operationele kosten: een agent van ~500 dagelijkse interacties op Haiku 4.5 kan schommelen rond 50-150 euro per maand aan tokens; op Opus 4.7 kan de rekening met 10 of meer vermenigvuldigd worden. Ontwerp voor lage kosten en stijg alleen waar het zichtbare waarde toevoegt.
Is een AI-agent die klantdata raakt veilig?
Kan veilig zijn: (1) gevoelige data gereviewd vóór de prompt; (2) onomkeerbare acties met menselijke bevestiging; (3) elke run geaudit met traceerbaarheid. Voor gereguleerde inhoud (gezondheidszorg, juridisch, financieel met beroepsgeheim), overweeg on-premise of regionale modellen met specifieke niet-trainen-afspraken. Een project van enterprise RAG met gecontroleerde infrastructuur is vaak de juiste optie.
Hoe voorkom ik dat mijn agent data hallucineert?
Meerdere lagen: (1) prompt met letterlijke anti-hallucinatie-regels ("als je het gegeven niet hebt, return null"); (2) confidence en evidence per veld voor auditeerbare output; (3) gestructureerde formaten met gesloten enum; (4) deterministische validatie vóór kritieke systemen; (5) menselijke bevestiging bij onomkeerbare operaties. Geen enkele volstaat alleen; de vijf samen reduceren hallucinatie tot tolerabele niveaus.
Wat is een Brain-protocol in Nexo?
Een declaratieve workflow met getypeerde steps (connector_fetch, data_filter, ai_call, db_query, action, condition) die sequentieel worden uitgevoerd met muteerbare context. In tegenstelling tot een "alleskunner"-agent die beslist welke tool aan te roepen, is een protocol deterministisch in de sequentie maar flexibel binnen elke step. Harde limieten (MAX_STEPS = 10, MAX_CONTEXT_CHARS = 300000) en elke run geaudit in BrainProtocolRun met tokens, latency per step, trigger source en resultaat.
Wat te doen als mijn LLM-provider prijzen verandert of een toegangsmodus sluit?
Als je ontkoppeld bent (patroon 8), is roteren configuratie: verifieer dat de prompts werken met het nieuwe model en herevalueer de kosten. Zo niet, introduceer eerst de abstractielaag, scheid credentials in config en test de prompts op minstens twee providers. Het werk betaalt zich zeer snel terug de eerste keer dat het een incident voorkomt.
Kan ik beginnen met een autonome agent en later bevestiging toevoegen?
Andersom: begin met menselijke bevestiging voor alle onomkeerbare acties en schakel autonoom pas in wanneer je data hebt over lage foutratio. Bevestiging toevoegen na een incident is duurder dan ze intrekken wanneer de agent betrouwbaarheid bewijst, vooral in gevoelige domeinen (geld, mails naar klanten, CRM).
Conclusie: patronen schalen, antipatronen ook
2026 is het eerste jaar waarin AI-agenten infrastructuur zijn geworden: niet het nieuwe ding dat we uitproberen, maar het ding dat we hadden en dat we nodig hebben dat blijft werken. Die statuswijziging brengt disciplines mee die uit klassieke engineering zijn geleend — observability, expliciete limieten, scheiding van verantwoordelijkheden, ontkoppeling van de provider — die de hype van 2024 op de achtergrond had geplaatst.
De acht patronen en vier antipatronen van dit artikel zijn wat, in onze ervaring, een agent die twaalf maanden in productie overleeft scheidt van een die na drie maanden moet worden herbouwd. De duurste AI-antipatronen zijn niet de technische mislukkingen maar de ontwerpbeslissingen: autonomie geven zonder toezicht, vertrouwen op oneindige context, lezen en schrijven mengen, of jezelf vastklampen aan één enkele provider. De waarde zit niet in het model of de prompt — ze zit in de infrastructuur die de prompt omhult en correct, auditeerbaar, goedkoop en vervangbaar maakt op dag 365.
Als je aan je eerste agent begint, of als je er al een hebt en vermoedt dat het onderhoud je meer kost dan het je oplevert, bij Kiwop — Digital Agency gespecialiseerd in Softwareontwikkeling en toegepaste Kunstmatige Intelligentie voor wereldwijde klanten in Europa en de VS — doen we ontwikkeling van AI-agenten, AI-consultancy, LLM-integratie en LLMOps als gecoördineerde onderdelen van hetzelfde proces.