Agents IA en production 2026 : patrons et antipatrons après déploiement dans Nexo, PA et projets clients
Par l'équipe de Kiwop · Agence Digitale spécialisée en Développement Logiciel et Intelligence Artificielle appliquée pour clients mondiaux en Europe et aux États-Unis · Publié le 19 avril 2026 · Dernière mise à jour : 19 avril 2026
TL;DR — Quinze mois de déploiement d'agents IA dans Nexo, PA et chez des clients nous laissent 8 patrons et 4 antipatrons IA. Règles clés : narrow scope bat généraliste, confirmation humaine avant les actions irréversibles et jamais de lock-in avec un unique LLM. Si vous avez déjà un agent en production ou que vous êtes sur le point de le déployer, voici le cadre complet.

L'année 2026 est la première où les agents IA cessent d'être des démos de conférence et deviennent une infrastructure que quelqu'un doit redémarrer à 3 heures du matin quand un step échoue. Chez Kiwop nous construisons depuis janvier 2025 des agents qui vivent en production : à l'intérieur de notre SaaS propre Nexo, comme outils internes de l'équipe, et dans des projets clients.
Cet article rassemble les décisions d'architecture qui ont survécu à ces quinze mois. Chaque patron vient d'un incident concret, d'un coût que nous ne voulions pas repayer ou d'une réclamation qui nous a obligés à repenser. Chaque antipatron est quelque chose que nous avons mal fait au moins une fois. Si vous êtes sur le point de déployer votre premier agent, ou si vous en avez déjà un et que la maintenance coûte plus que le développement initial, voici le guide que nous aurions aimé avoir quand nous avons commencé.
Contexte : où nous avons déployé des agents IA chez Kiwop
Avant d'entrer dans les patrons, une carte de d'où parlent les données. Les agents IA en production de Kiwop à avril 2026 se regroupent en trois catégories.
Agents dans Nexo, notre SaaS multi-tenant (RH, CRM, projets, facturation). À l'intérieur de Nexo tournent deux familles : Brain protocols, un moteur de workflows multi-step par client et workspace, et l'extracteur de contrats par IA qui traite les PDF pour automatiser la création de contrats et jalons de facturation. Brain a plusieurs dizaines de protocoles actifs répartis entre workspaces de clients ; l'extracteur traite plusieurs centaines de documents mensuels.
PA, l'assistant personnel interne. Détaillé dans D'OpenClaw à PA avec Claude Code et MCP, il connecte courrier IMAP, Gmail, Slack, Telegram et Google Calendar avec une session Claude Code persistante. Plusieurs membres de l'équipe l'utilisent au quotidien et il traite au total un peu plus de 1 000 interactions par jour.
Intégrations de client. Agents sur mesure : un agent de triage de tickets pour un client fintech, un agent d'enrichissement de leads pour un client e-commerce, et un agent de consultation de documentation juridique pour un client consultant. Ensemble ils tournent autour de 200-400 exécutions par jour.
LLMs que nous utilisons. Nous combinons des modèles d'Anthropic (Haiku 4.5, Sonnet 4.5, Opus 4.7) pour la majorité des charges conversationnelles et de raisonnement, et des modèles d'OpenAI (GPT-4o et GPT-4o-mini) pour l'extraction structurée et les workloads sensibles au coût. Le choix se fait par feature et par workspace via un AiGateway que nous verrons plus loin.
Patron 1 : narrow scope bat toujours généraliste
La première tentation est de faire un agent qui « fait tout » — lit le courrier, consulte le calendrier, met à jour le CRM, répond sur Slack, résume les réunions. Un seul prompt énorme, un seul agent. En démo c'est spectaculaire ; en production cela ne survit pas. Quand l'agent couvre trop, le prompt se remplit d'instructions contradictoires, le LLM perd en précision et quand quelque chose échoue il est impossible de savoir dans quelle sous-tâche cela a échoué. Pire : modifier l'instruction de « comment résumer un courriel » peut altérer celle de « comment écrire un message Slack ».
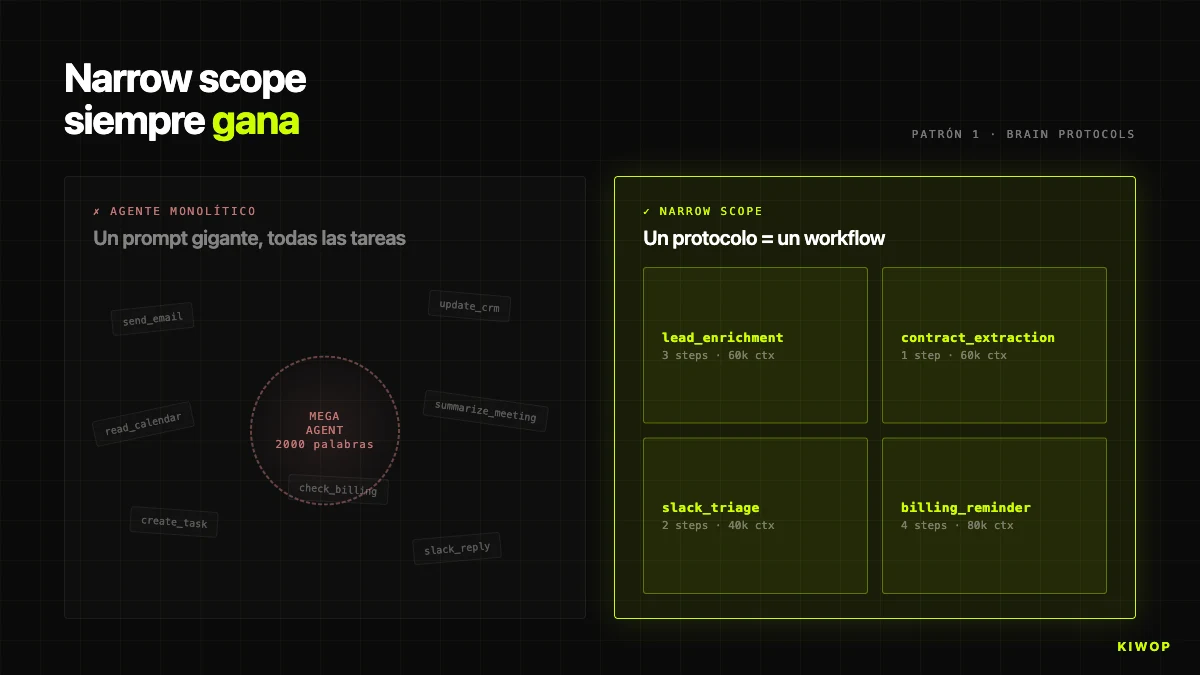
Dans Brain, la règle est explicite : un protocole = un workflow. Chaque protocole a un objectif unique — lead_enrichment, contract_extraction_followup, project_health_check, weekly_billing_reminder. Si un nouveau cas d'usage émerge, on crée un nouveau protocole, on n'étend pas un existant. Quand un client demande « qu'enrichment envoie aussi un Slack », la bonne réponse est de créer un second protocole enchaîné, pas de gonfler le premier.
Cela se remarque dans le code du BrainProtocolEngine : chaque protocole a ses propres steps, son trigger_config, son project_id et son workspace_id. Si enrichment échoue pour un lead concret, les autres protocoles du même workspace continuent de tourner sans s'en apercevoir.
L'antipatron opposé — « l'agent qui fait tout » — apparaît fréquemment dans les propositions client : « un copilot pour l'équipe commerciale qui lise le courrier, consulte le CRM, envoie des propositions, fasse le suivi, prévienne des renouvellements ». Notre réponse standard est de dessiner cette demande comme cinq ou six agents indépendants orchestrés avec des protocoles enchaînés. La différence de coût total de possession à douze mois est facilement 3x ou 4x. Si votre agent a besoin d'un prompt système de 2 000 mots pour fonctionner, vous avez presque certainement plusieurs agents collés au scotch. Séparez-les.
Patron 2 : confirmation humaine avant les actions irréversibles
Les LLMs modernes se trompent environ 1 % du temps sur des tâches fermées considérées « faciles ». Ce n'est pas un nombre mesuré par nous avec rigueur — c'est l'ordre de grandeur des benchmarks publics et cela correspond à notre expérience interne. Cela paraît faible jusqu'à ce que vous fassiez le calcul.
Un agent qui exécute 1 000 opérations par jour avec 1 % d'erreur produit 10 opérations erronées par jour. Si ce sont des lectures, le coût est nul. Si ce sont des écritures (envoyer un courriel, créer un événement, modifier un registre, supprimer quelque chose), le coût peut aller d'un inconfort à un post mortem. Dix incidents par jour sont insoutenables.
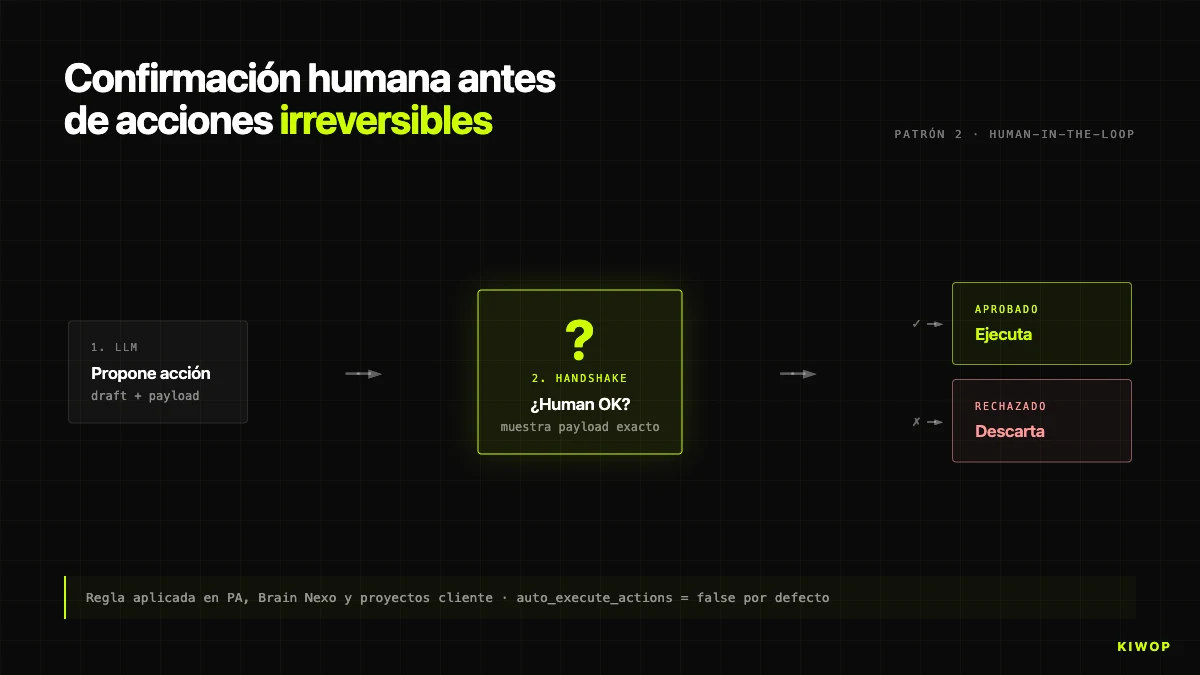
La règle sans exceptions : l'agent n'exécute jamais d'actions irréversibles sans confirmation humaine explicite. Dans PA, décrit dans le post de l'assistant personnel, l'agent peut lire toute la boîte mais n'envoie pas sans que l'humain écrive « oui ». Dans Brain, l'équivalent est le flag auto_execute_actions dans BrainProtocol : par défaut à false, quand un step génère une action (créer une tâche, une proposition, une alerte), ce qui est créé est une AgentProposal en attente d'approbation, pas l'action finale.
Nous n'activons auto_execute_actions = true que lorsque trois conditions sont remplies : (1) l'action est idempotente et réversible, (2) après plusieurs centaines de runs vérifiés manuellement, le taux d'erreur observé reste sous 1 %, bien que la mesure ne soit pas méthodologiquement rigoureuse, et (3) le client signe l'habilitation par écrit. À avril 2026, moins d'un quart des protocoles tourne en mode autonome.
Un piège : la confirmation ne doit pas être « êtes-vous sûr ? [oui/non] » car l'utilisateur s'habitue et clique sans lire. Le handshake bien conçu montre exactement ce qui va se passer (destinataire, objet, corps du courriel ; entité DB à modifier ; montant exact). Si l'humain doit savoir ce qu'il confirme, il lit ce qu'il confirme.
Ce patron se connecte avec le conseil en IA : la conversation commence par « quelles actions l'agent peut-il prendre sans demander ? » et presque toujours la réponse initiale est insuffisante. Élargir les permissions est facile, les retirer après un incident coûte cher.
Patron 3 : limites strictes de contexte et de steps
Les agents multi-step sont gourmands. Chaque step ajoute de l'information au contexte, chaque appel peut retourner de longues réponses, et sans plafond explicite le contexte grandit jusqu'à ce qu'un des trois problèmes vous frappe : coût disproportionné, hallucination par contexte gonflé ou timeout du fournisseur.
Dans BrainProtocolEngine nous avons deux constantes dures :
MAX_STEPS = 10 signifie qu'un protocole ne peut pas exécuter plus de 10 steps par run, peu importe combien il en a de définis. Les protocoles avec plus de 10 steps sont presque toujours un design qu'il aurait été préférable de diviser en deux enchaînés ; la limite force cette conversation.
MAX_CONTEXT_CHARS = 300000 s'applique au contexte total accumulé. Si le JSON dépasse 300 000 caractères, un warning est enregistré et le prompt est tronqué avec un message explicite au modèle : « CONTEXTO TRUNCADO POR LÍMITE DE TAMAÑO ». La limite est calibrée pour tenir confortablement dans une fenêtre de 200K tokens et s'éloigner du 1M des modèles à contexte étendu — parce que, comme nous le verrons plus loin, grand contexte et contexte utile sont des choses très différentes.
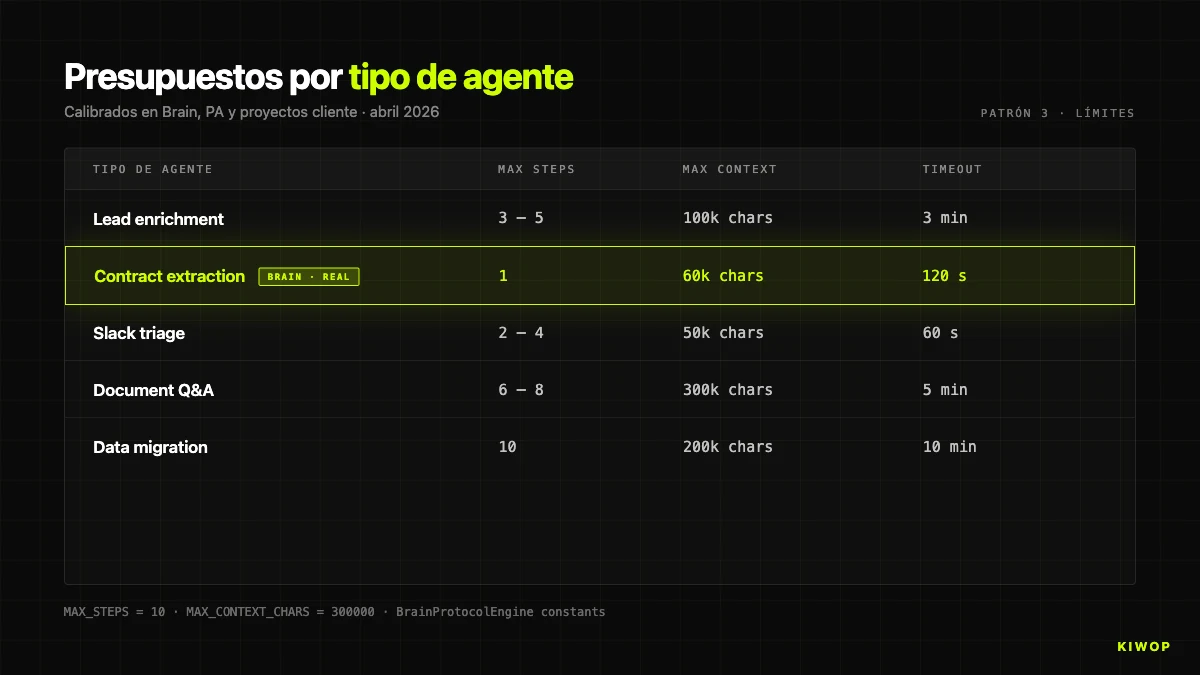
À titre de référence indicative, voici les budgets que nous utilisons par défaut selon le type d'agent :
Ces valeurs ne sont pas universelles — ce sont celles qui ont passé l'épreuve de la production dans nos workloads. Si vous démarrez, commencez conservateur et ne montez que lorsque vous avez des données qui le justifient.
Patron 4 : MCP comme langage commun plutôt qu'intégrations ad hoc
Avant 2025, chaque intégration entre un agent et un système externe était du code sur mesure : un connecteur pour Gmail, un autre pour Calendar, un autre pour Slack, chacun avec son authentification et sa maintenance. La majeure partie du coût de construction d'un agent ne venait pas du prompt ni du modèle, elle venait du glue code.
Model Context Protocol (MCP) a changé cela durant 2025 et a consolidé sa position en 2026. MCP est un standard ouvert pour que n'importe quel modèle parle avec n'importe quel outil en utilisant une même grammaire de « tool calls ». Publié par Anthropic en 2024, il a été adopté par OpenAI, Google et les principaux clients IA. Aujourd'hui, la majorité des intégrations que nous construisons s'appuient sur des serveurs MCP préexistants au lieu d'écrire un nouveau client.
L'impact sur le coût de développement est brutal. Pour un agent qui doit parler à Gmail, Calendar, Drive, Slack, Linear et GitHub, la différence entre écrire six connecteurs propres avec leurs OAuth et brancher six serveurs MCP existants est de l'ordre de semaines contre heures. Et la maintenance — quand un service change un endpoint ou fait tourner les credentials — cesse d'être votre problème.
Si vous n'êtes pas sûr de ce qu'est MCP, WebMCP : votre site web préparé pour les agents IA l'explique avec des exemples concrets. Pour la comparaison avec les protocoles frères, MCP, WebMCP et A2A : les protocoles qui définissent les agents IA en 2026 entre dans le détail.
Règle opérationnelle : avant d'écrire un connecteur propre, vérifiez s'il existe un MCP officiel ou communautaire. S'il existe et est maintenu par une équipe sérieuse, utilisez-le. MCP n'est pas une panacée — il a des angles morts (IMAP corporate, Telegram, CRMs verticaux). Pour ces trous nous écrivons des scripts propres, mais avec la forme d'un MCP pour que, si demain quelqu'un en publie un, le changement soit indolore.
Patron 5 : anti-hallucination explicite dans le prompt
Les LLMs hallucinent. C'est une caractéristique architecturale du transformer, pas un bug qui va disparaître avec le prochain modèle. Tout agent qui traite des données réelles doit cohabiter avec cette réalité.
La stratégie qui a le mieux fonctionné pour nous est d'inscrire les règles anti-hallucination directement dans le prompt système, de manière littérale et redondante. Pas « s'il vous plaît, soyez précis ». Des règles numérotées, avec les termes critiques en majuscules, avec des instructions opérationnelles sur que faire en cas de doute.
L'exemple le plus clair en production est l'extracteur de contrats de Nexo. Le prompt système de l'OpenAiContractExtractor démarre avec ces instructions :
CRITICAL RULES: 1. NEVER invent or hallucinate data. If a field is not clearly stated, return null. 2. Return ONLY valid JSON. No explanations outside the JSON. 3. For each field, provide: - value: The extracted value (or null if not found) - confidence: A score from 0.0 to 1.0 indicating how confident you are - evidence: A brief quote from the document supporting your extraction (or null) 4. Dates MUST be in YYYY-MM-DD format. If day/month is unclear, return null.
Trois mécanismes entrent en jeu :
Permettre au modèle de dire « je ne sais pas ». Retourner null quand une donnée n'est pas claire est un résultat valide ; l'inventer, non. Beaucoup de gens écrivent des prompts sans sortie explicite vers « donnée non disponible » et le modèle, forcé, remplit avec le plus plausible qu'il trouve.
Demander confiance et preuve par champ. Le confidence oblige le modèle à méta-raisonner sur sa certitude. L'evidence — citation littérale du document — est vérifiable : si la citation n'apparaît pas, le champ est écarté. L'output devient auditable au lieu d'être une boîte noire.
Formats structurés stricts. Dates en YYYY-MM-DD, nombres comme types numériques, énumérations fermées ("fixed" | "hourly" | "monthly"). Plus le format est fermé, moins il y a d'espace pour une hallucination créative.
Cette stratégie n'élimine pas l'hallucination mais la réduit à des niveaux tolérables avec confirmation humaine. Dans nos données internes, passer de prompts laxistes à des prompts avec règles anti-hallucination littérales a réduit les champs faussement remplis d'environ un facteur cinq, sans changer le modèle.
Patron 6 : observabilité obligatoire
La première fois qu'un client demande « pourquoi l'agent a fait cela ? » et que vous n'avez pas de données pour répondre, vous apprenez que l'observabilité n'est pas optionnelle. Chaque exécution doit laisser une trace auditable : tokens, latence, steps exécutés, inputs, outputs, qui a déclenché et d'où.
Dans Brain, cela s'implémente avec BrainProtocolRun. Chaque exécution crée un enregistrement avec :
status:running | completed | failed | cancelledstep_results: tableau avec un objet par step exécuté (nom, type, durée en ms, état, résultat ou erreur)context: le contexte accumulé, tronqué à 50 000 caractères pour le stockagecurrent_step: à quel step on en était quand il s'est terminé ou a échouétokens_used: tokens totaux consommés (somme input + output de tous lesai_call)started_at/completed_attriggered_by_user_id/trigger_source: qui et depuis quel canal a déclenché le runerror: s'il a échoué, le message complet
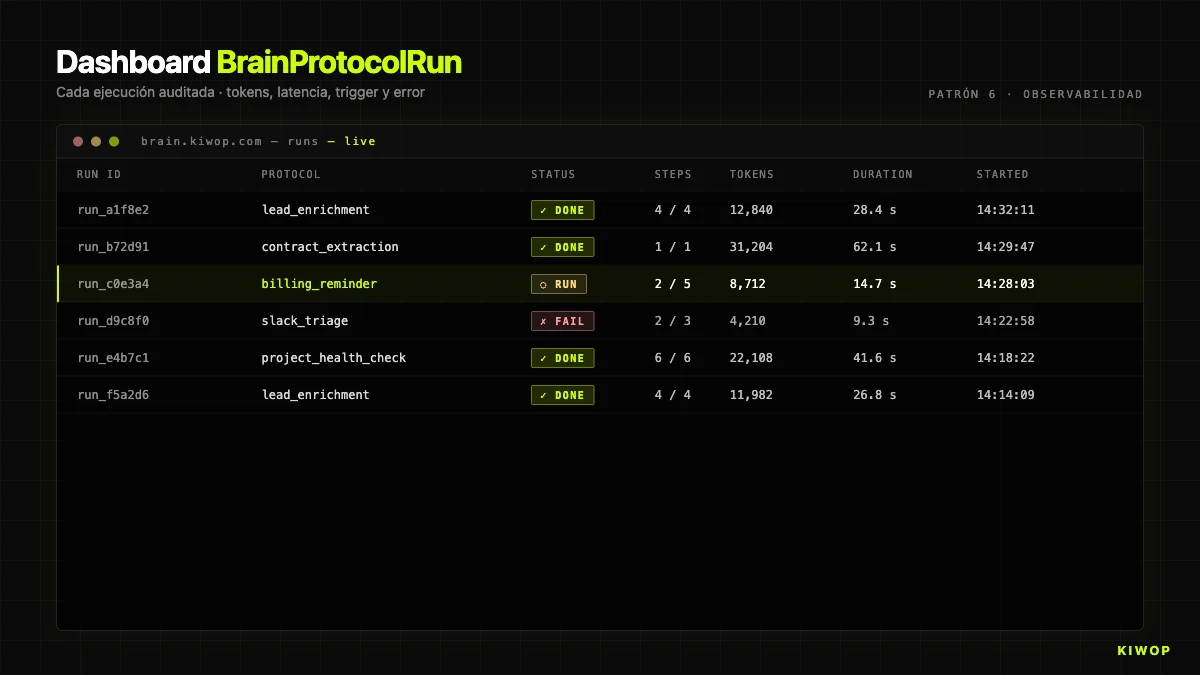
Cette structure répond aux trois questions que l'on finit toujours par poser : combien ça coûte ? (somme de tokens_used × prix par token), pourquoi a-t-il échoué ? (error + step_results jusqu'au step qui a échoué), pourquoi a-t-il tant tardé ? (duration_ms par step).
Deux règles additionnelles apprises à la dure :
Logs consultables à chaud. Les fichiers que personne ne regarde ne servent à rien. La DB applicative convient pour volume bas-moyen ; pour volume élevé, un stack dédié (Datadog, Grafana, Honeycomb) paie le coût avant le premier incident grave.
Enregistrez toujours `trigger_source` et `triggered_by_user_id`. Quand quelque chose tourne mal, la première question est médico-légale : est-ce le scheduler, un utilisateur, une intégration externe, un webhook qui l'a déclenché ? Sans cette traçabilité, chaque incident est une enquête archéologique.
Ce patron est au cœur de notre offre de LLMOps : gérer des modèles en production n'est pas gérer les modèles — c'est gérer la télémétrie, le coût, la qualité et la sécurité des agents qui les utilisent.
Patron 7 : agentic timeouts avec retry exponentiel
Les LLMs externes échouent — pics de demande, coupures réseau, sessions suspendues. Un agent qui ne gère pas les timeouts explicites est un agent qui se suspend, et un agent suspendu est pire qu'un qui échoue : l'humain ne sait pas ce qui se passe.
Trois composants dans notre politique :
Timeouts explicites par step. Dans Brain chaque ai_call définit son max_tokens et son timeout effectif. Défaut du client : 120 secondes. Si un step le dépasse, le moteur le marque comme failed au lieu de laisser le run suspendu.
Retry exponentiel avec limite. Pour les erreurs transitoires (rate limit, 5xx, timeouts réseau) nous réessayons avec backoff : delay = base * 2^attempt + jitter, base = 500ms, maximum 3 réessais, plafond 30 secondes. Absorbe les blips sans marteler le fournisseur.
Échec rapide sur erreurs non récupérables. Les 4xx (input invalide, credentials expirés, quota épuisé) ne sont pas réessayés — la tentative suivante va échouer pareil. Si le step est marqué critical: true, il annule tout le protocole.
Note pour les agents MCP : les serveurs MCP se suspendent aussi, et le client ne propage pas toujours bien le timeout. Dans PA nous avons enveloppé certains appels MCP avec timeout au niveau du processus. La leçon : ne faites pas confiance aux timeouts d'une seule couche, empilez-en plusieurs.
Patron 8 : design agnostique au fournisseur de LLM
Le 4 avril 2026 nous avons appris en première personne la valeur d'avoir l'infrastructure découplée du fournisseur. Ce jour-là Anthropic a coupé les tokens OAuth qui permettaient d'utiliser les abonnements Claude Max et Pro avec des harnesses tiers, et plusieurs agents de l'écosystème se sont retrouvés sans backend. Nous racontons l'histoire dans D'OpenClaw à PA avec Claude Code et MCP et dédions un post spécifique à la construction étape par étape de PA avec Claude Code et MCP.
L'infrastructure de Nexo n'a pas été affectée parce qu'elle était conçue pour être agnostique au fournisseur. Le composant clé est AiGateway, une abstraction qui centralise les appels au LLM et décide en runtime quel client utiliser selon la connexion du workspace et la feature.
Derrière chat(), AiGateway résout une WorkspaceAiConnection, construit le client (AnthropicClient, OpenAiClient ou ClaudeCliClient pour console-auth) et émet avec le bon modèle. Faire passer un workspace d'Anthropic à OpenAI est un changement de configuration, pas de code.
Trois effets concrets :
Résilience. Si Anthropic a un incident, nous basculons vers OpenAI en minutes sans toucher au code du protocole. Le 4 avril nous n'avons pas eu à le faire parce que la coupure affectait OAuth de Claude Code, pas l'API que Nexo utilise, mais la capacité était prouvée.
Choix par feature. Chat utilise Haiku 4.5 pour le coût ; résumés de réunion utilisent Opus 4.7 pour la qualité ; extraction de contrats utilise GPT-4o pour son mode JSON structuré. L'abstraction permet d'optimiser chaque feature séparément.
Optimisation par workspace. Workspaces petits sur modèles bon marché, workspaces premium sur modèles premium. Décision dans workspaces_ai_connections, pas dans le code.
La règle : n'appelez jamais l'API du fournisseur directement depuis votre code métier. Passez toujours par une couche intermédiaire propre. Quand le fournisseur change quelque chose — et il va changer — l'impact reste dans cette couche.
Comparaison des fournisseurs LLM à avril 2026
Ce tableau résume comment nous voyons aujourd'hui les trois grands fournisseurs tier-top du point de vue d'un agent en production. Ce n'est pas un classement absolu — c'est un guide sur quand il a du sens de s'appuyer sur chacun dans une architecture multi-fournisseur comme celle du patron précédent.
Comparaison à avril 2026 ; modèles et prix évoluent rapidement.
Ensuite nous déroulons quatre antipatrons IA d'agents que nous avons vus faire dérailler des projets — tant les nôtres que ceux de clients — quand une des disciplines précédentes n'est pas appliquée.
Antipatron 1 : agent autonome qui agit sans supervision
Le récit de « l'agent autonome qui décide seul » sonne bien dans les slides et finit mal dans les incidents. La raison n'est pas philosophique, elle est statistique : tout processus stochastique (et les LLMs le sont) commettra des erreurs, et les erreurs sans supervision humaine se transforment en dommages accumulés.
Modes typiques de défaillance :
Boucle infinie. Un agent qui « décide quoi faire ensuite » peut invoquer la même tool 50 fois de suite. Sans un plafond comme MAX_STEPS = 10, l'exécution consomme des tokens sans valeur.
Cascade d'effets. Une facture erronée déclenche un webhook qui envoie un courriel au client, qui ouvre un ticket dans le CRM, qui notifie l'équipe commerciale. Défaire la chaîne coûte plus que l'erreur originale.
Corruption d'état. Un agent avec des permissions d'écriture qui interprète mal une instruction peut modifier des enregistrements impossibles à reconstruire sans backup préalable.
Règle pratique : aucun agent ne devrait avoir de permissions d'écriture irréversibles sans human-in-the-loop au début. Activer le mode autonome pour des actions spécifiques est possible après des centaines de runs vérifiés et un taux d'erreur sous le seuil du domaine. Jamais avant. Jamais par défaut.
Antipatron 2 : faire confiance au contexte « infini » du modèle
Les modèles de 2026 se vantent de fenêtres de 200K, 500K et jusqu'à 1M tokens. Le message qui a pris est que « maintenant vous pouvez mettre ce que vous voulez ». Ce n'est pas vrai en production.
Trois raisons de ne pas faire confiance à la fenêtre complète :
Dégradation de qualité avec contexte gonflé. Les benchmarks publics et nos évaluations internes montrent que la précision de récupération (needle-in-a-haystack) se dégrade en s'approchant de la limite. Un modèle qui trouve une donnée à 99 % à 50K tokens peut descendre à 80 % ou moins à 500K tokens.
Coût proportionnel à l'input. Un contexte de 300K tokens coûte six fois plus qu'un de 50K. Avec 100 appels par jour, la différence mensuelle entre « tout tient » et « seulement ce qui est nécessaire » se compte en centaines ou milliers d'euros.
Latence du first-token. Un prompt de 300K tokens peut prendre plusieurs secondes à être traité avant que le modèle ne commence à répondre, même avec prompt caching. Pour l'expérience conversationnelle, cela tue la perception de rapidité.
Discipline : le contexte doit être le minimum nécessaire, pas le maximum possible. Dans Brain, les data_filter existent précisément pour réduire le contexte entre les steps : un connector_fetch peut amener 500 courriels ; le filtre les réduit aux 20 qui remplissent les critères ; l'ai_call suivant ne voit que ceux-là. Le patron RAG naît de la même discipline — pour de grandes bases documentaires, le RAG d'entreprise est l'architecture correcte, pas un contexte géant.
Antipatron 3 : sans séparation de lecture et écriture
Les agents qui lisent et écrivent dans le même step sont des bombes à retardement. Si l'appel échoue à mi-chemin, vous ne savez pas si l'écriture s'est exécutée. S'il réessaie, vous pouvez dupliquer. S'il y a une erreur d'interprétation, vous n'avez pas de snapshot de l'état que l'agent a vu.
Règle : séparez lecture et écriture en étapes distinctes avec matérialisation explicite entre les deux. Dans Brain, la typologie de steps le reflète : connector_fetch et db_query sont read-only ; action est la seule qui écrit. Un protocole bien conçu a la forme « N steps de lecture, 0 ou 1 d'écriture à la fin ». Si vous devez écrire plus d'une fois, vous partagez le protocole en deux.
Dans les intégrations client nous appliquons le même patron : l'agent génère une proposition (objet en DB avec le brouillon ou le changement), et un second pas — avec confirmation humaine — exécute l'action. Permet audit, retry sûr, rollback et human-in-the-loop sans redessiner le flux. Exception légitime : opérations idempotentes avec clé naturelle. Pour le reste, séparez.
Antipatron 4 : un unique fournisseur de LLM critique
Nous l'avons déjà abordé dans le patron 8, mais il mérite d'être souligné : un agent critique qui dépend d'un unique fournisseur est un agent fragile. Pas parce que le fournisseur est mauvais, mais parce que toute décision unilatérale — changement de prix, de politique, sunset d'un modèle, chute du service, coupure OAuth — peut vous laisser sans backend.
Le 4 avril 2026 Anthropic a coupé OAuth de Claude Max pour les tiers. OpenAI ajuste les prix d'API périodiquement. Google change les quotas de Gemini. Ce ne sont pas des mouvements malicieux — ce sont des décisions business — mais tous ont le même effet sur celui qui a construit en supposant que rien ne changerait.
Trois couches minimales de découplage :
Abstraction propre type AiGateway. Votre code parle à votre abstraction, pas au SDK du fournisseur.
Credentials et config en DB. Changer de modèle ou de fournisseur ne devrait pas exiger un déploiement, mais un UPDATE.
Prompts portables. Si votre prompt ne fonctionne qu'avec un modèle spécifique, vous avez un prompt fragile. Les prompts bien écrits (règles explicites, format structuré) fonctionnent convenablement sur les modèles tier-top des trois grands. Si les différences sont grandes, le problème est dans le prompt, pas dans le modèle.
Avec ces trois couches, quand le fournisseur A change quelque chose votre coût de migration est de quelques heures, pas de semaines.
Comment nous appliquons ces patrons dans les services de Kiwop

Ces huit patrons et quatre antipatrons sont le cadre avec lequel nous livrons des projets d'IA chez Kiwop. Quand un client arrive avec « je veux un agent pour X », la conversation suit cet ordre :
Premièrement, conseil en IA pour délimiter le scope réel. Presque toujours ce que demande le client sont trois ou quatre agents liés à la même chose ; le travail de conseil est de les séparer et de décider ce qui est autonome et ce qui requiert un handshake humain.
Deuxièmement, développement d'agents IA avec une architecture qui applique les patrons 3 à 8 par défaut : limites, MCPs, anti-hallucination, observabilité, timeouts, abstraction du fournisseur.
Troisièmement, intégration de LLMs sur MCP quand il existe et sur des connecteurs propres quand il n'existe pas.
Quatrièmement, une fois en production, LLMOps pour gérer le cycle de vie : observabilité, coûts par workspace, rotation de modèles, réponse aux incidents.
L'objectif : que l'agent que nous livrons le jour 1 continue à fonctionner le jour 365 avec un coût prévisible.
Questions fréquentes
Quand cela a-t-il du sens de construire un agent IA en production ?
Quand il y a une tâche répétitive semi-structurée, avec des critères clairs de succès et qui permet de tolérer un petit pourcentage d'erreurs grâce à la confirmation humaine. Exemples : triage de courrier ou tickets, enrichissement de leads, extraction de documents, résumé de réunions, classification de messages. Cela n'a pas de sens pour des tâches avec coût d'erreur très élevé sans supervision, ni pour des tâches résolubles avec une règle déterministe sans LLM.
Quel modèle de LLM choisir pour un agent en 2026 ?
Dépend de la feature. Pour chat et multi-step avec priorité au coût, Haiku 4.5 ou GPT-4o-mini. Pour raisonnement complexe et extraction de qualité, Sonnet 4.5, Opus 4.7 ou GPT-4o. Pour JSON strict, GPT-4o pour son mode natif. Commencez avec le modèle le moins cher qui passe vos évaluations propres et montez de tier seulement quand les données le justifient.
Combien coûte le déploiement d'un agent IA en production ?
Développement entre 6 000 et 15 000 euros pour un agent narrow scope avec des MCPs existants (monte avec des intégrations sur mesure). Coût opérationnel : un agent de ~500 interactions par jour sur Haiku 4.5 peut évoluer dans 50-150 euros mensuels en tokens ; sur Opus 4.7 la facture peut se multiplier par 10 ou plus. Concevez pour un coût bas et ne montez que là où cela ajoute une valeur visible.
Est-il sûr, un agent IA qui touche des données clients ?
Il peut l'être : (1) données sensibles revues avant le prompt ; (2) actions irréversibles avec confirmation humaine ; (3) chaque run audité avec traçabilité. Pour du contenu régulé (santé, juridique, financier avec secret professionnel), évaluez des modèles on-premise ou régionaux avec des accords spécifiques de non-entraînement. Un projet de RAG d'entreprise avec infrastructure contrôlée est généralement la bonne option.
Comment éviter que mon agent hallucine des données ?
Plusieurs couches : (1) prompt avec règles anti-hallucination littérales (« si vous n'avez pas la donnée, renvoyez null ») ; (2) confiance et preuve par champ pour un output auditable ; (3) formats structurés avec enum fermés ; (4) validation déterministe avant les systèmes critiques ; (5) confirmation humaine pour les opérations irréversibles. Aucune ne suffit seule ; les cinq ensemble réduisent l'hallucination à des niveaux tolérables.
Qu'est-ce qu'un Brain protocol dans Nexo ?
Un workflow déclaratif avec des steps typés (connector_fetch, data_filter, ai_call, db_query, action, condition) exécutés séquentiellement avec contexte mutable. Contrairement à un agent « tout-terrain » qui décide quelle tool appeler, un protocole est déterministe dans la séquence mais flexible à l'intérieur de chaque step. Limites dures (MAX_STEPS = 10, MAX_CONTEXT_CHARS = 300000) et chaque run audité dans BrainProtocolRun avec tokens, latence par step, trigger source et résultat.
Que faire si mon fournisseur de LLM change les prix ou ferme une modalité d'accès ?
Si vous êtes découplé (patron 8), la rotation est de la configuration : vérifiez que les prompts fonctionnent avec le nouveau modèle et réévaluez le coût. Si vous ne l'étiez pas, introduisez d'abord la couche d'abstraction, séparez les credentials dans la config et testez les prompts sur au moins deux fournisseurs. Le travail s'amortit très vite la première fois qu'il évite un incident.
Puis-je commencer avec un agent autonome et ajouter la confirmation ensuite ?
À l'inverse : commencez avec confirmation humaine sur toutes les actions irréversibles et activez le mode autonome seulement quand vous avez des données de taux d'erreur faible. Ajouter la confirmation après un incident est plus cher que la retirer quand l'agent démontre sa solvabilité, surtout dans les domaines sensibles (argent, courriels à clients, CRM).
Conclusion : les patrons scalent, les antipatrons aussi
2026 est la première année où les agents IA sont devenus infrastructure : non plus la nouvelle chose que nous testons, mais la chose que nous avions et dont nous avons besoin qu'elle continue à fonctionner. Ce changement de statut apporte des disciplines empruntées à l'ingénierie classique — observabilité, limites explicites, séparation des responsabilités, découplage du fournisseur — que le hype de 2024 avait laissées au second plan.
Les huit patrons et quatre antipatrons de cet article sont ce qui, selon notre expérience, sépare un agent qui survit douze mois en production d'un qu'il faut reconstruire après trois. Les antipatrons IA les plus coûteux ne sont pas les défaillances techniques mais les décisions de design : donner de l'autonomie sans supervision, faire confiance au contexte infini, mélanger lecture et écriture, ou se lier à un unique fournisseur. La valeur n'est pas dans le modèle ni dans le prompt — elle est dans l'infrastructure qui enveloppe le prompt et le rend correct, auditable, bon marché et remplaçable le jour 365.
Si vous démarrez votre premier agent, ou que vous en avez déjà un et suspectez qu'il vous coûte à maintenir plus qu'il ne vous aide, chez Kiwop — Agence Digitale spécialisée en Développement Logiciel et Intelligence Artificielle appliquée pour clients mondiaux en Europe et aux États-Unis — nous faisons développement d'agents IA, conseil en IA, intégration de LLMs et LLMOps comme pièces coordonnées d'un même processus.