Por el equipo de Kiwop · Agencia Digital especializada en Desarrollo de Software e Inteligencia Artificial aplicada · Publicado el 19 de abril de 2026 · Última actualización: 19 de abril de 2026
TL;DR — Quince meses desplegando agentes IA en Nexo, PA y clientes nos dejan 8 patrones y 4 antipatrones IA. Reglas clave: narrow scope gana a generalista, confirmación humana antes de acciones irreversibles y nunca lock-in con un único LLM. Si ya tienes un agente en producción o estás por desplegarlo, aquí está el marco completo.

Los agentes IA han dejado de ser demos de conferencia para convertirse en infraestructura que alguien tiene que reiniciar a las 3 de la madrugada cuando un step falla. En Kiwop llevamos desde enero de 2025 construyendo agentes que viven en producción: dentro de nuestro SaaS propio Nexo, como herramientas internas del equipo, y en proyectos de cliente.
Este artículo recoge las decisiones de arquitectura que han sobrevivido a esos quince meses. Cada patrón viene de un incidente concreto, un coste que no queríamos volver a pagar o una reclamación que nos obligó a replantear. Cada antipatrón es algo que hemos hecho mal al menos una vez. Si estás a punto de desplegar tu primer agente, o si ya tienes uno y el mantenimiento cuesta más que el desarrollo inicial, esta es la guía que nos habría gustado tener cuando empezamos.
Contexto: dónde hemos desplegado agentes IA en Kiwop
Antes de entrar en patrones, un mapa de dónde hablan los datos. Los agentes IA en producción de Kiwop se agrupan actualmente en tres categorías.
Agentes en Nexo, nuestro SaaS multi-tenant (HR, CRM, proyectos, facturación). Dentro de Nexo corren dos familias: Brain protocols, un motor de workflows multi-step por cliente y workspace, y el extractor de contratos por IA que procesa PDFs para automatizar la creación de contratos e hitos de facturación. Brain tiene varias decenas de protocolos activos distribuidos entre workspaces de clientes; el extractor procesa varios cientos de documentos mensuales.
PA, el asistente personal interno. Detallado en De OpenClaw a PA con Claude Code y MCP, conecta correo IMAP, Gmail, Slack, Telegram y Google Calendar con una sesión de Claude Code persistente. Lo usa a diario varios miembros del equipo y procesa en conjunto algo por encima de 1.000 interacciones diarias.
Integraciones de cliente. Agentes a medida: un agente de triaje de tickets para un cliente fintech, un agente de enriquecimiento de leads para un cliente e-commerce, y un agente de consulta de documentación legal para un cliente consultor. En conjunto rondan las 200-400 ejecuciones diarias.
LLMs que usamos. Combinamos modelos de Anthropic (Haiku 4.5, Sonnet 4.5, Opus 4.7) para la mayoría de cargas conversacionales y de razonamiento, y modelos de OpenAI (GPT-4o y GPT-4o-mini) para extracción estructurada y workloads sensibles al coste. La elección se hace por feature y por workspace mediante un AiGateway que veremos más adelante.
Patrón 1: Narrow scope siempre gana a generalista
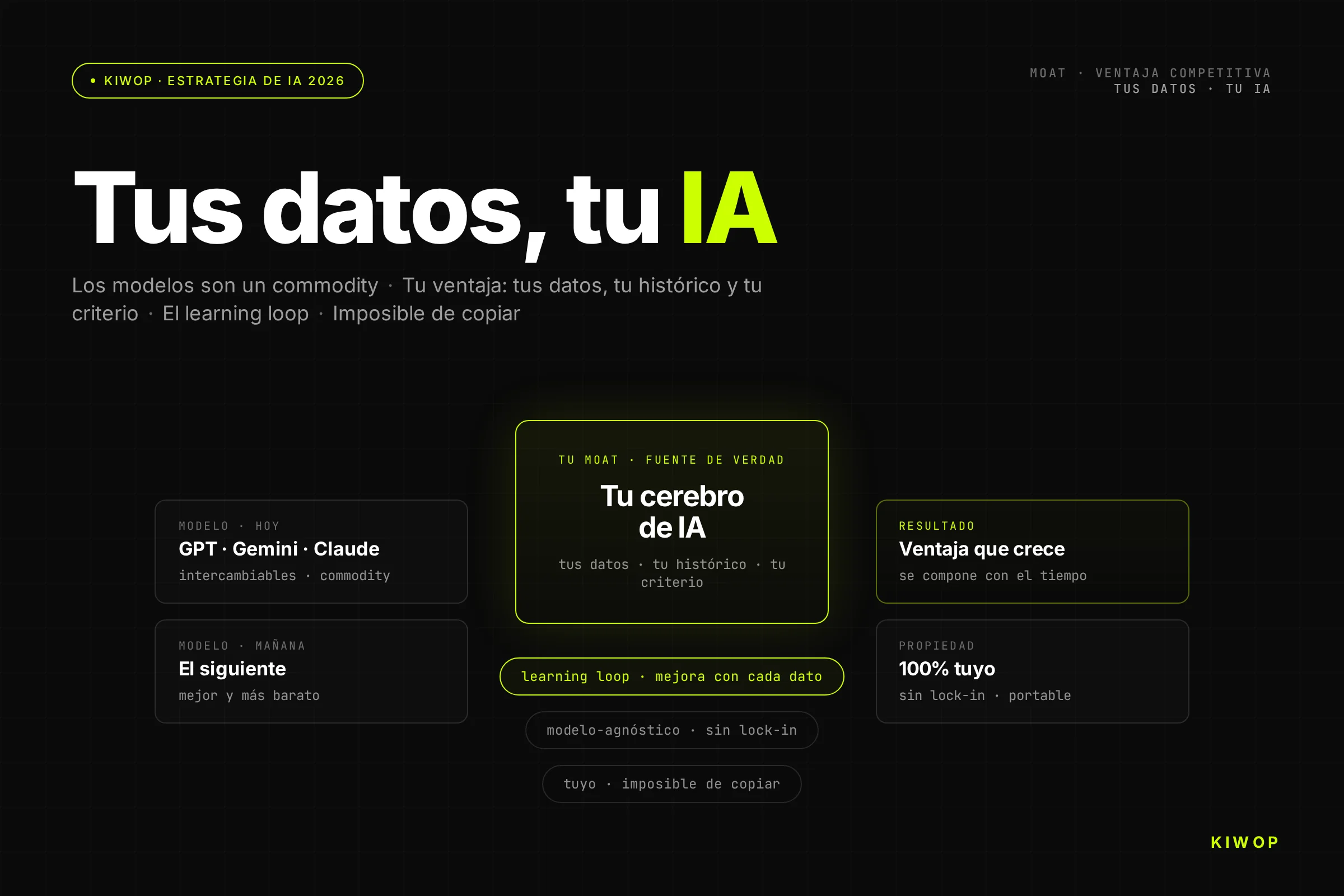
La primera tentación es hacer un agente que "haga todo" — lee correo, consulta calendario, actualiza CRM, responde Slack, resume reuniones. Un solo prompt enorme, un solo agente. En demo se ve espectacular; en producción no sobrevive. Cuando el agente cubre demasiado, el prompt se llena de instrucciones contradictorias, el LLM pierde precisión y cuando algo falla es imposible saber en qué sub-tarea falló. Peor: modificar la instrucción de "cómo resumes un correo" puede alterar la de "cómo escribes un mensaje de Slack".
En Brain, la regla es explícita: un protocolo = un workflow. Cada protocolo tiene un propósito único — lead_enrichment, contract_extraction_followup, project_health_check, weekly_billing_reminder. Si emerge un caso de uso nuevo, se crea un protocolo nuevo, no se amplía uno existente. Cuando un cliente pide "que enrichment también envíe un Slack", la respuesta correcta es crear un segundo protocolo encadenado, no hinchar el primero.
Esto se nota en el código del BrainProtocolEngine: cada protocolo tiene sus propios steps, su trigger_config, su project_id y su workspace_id. Si enrichment falla para un lead concreto, los demás protocolos del mismo workspace siguen corriendo sin enterarse.
El antipatrón opuesto — "el agente que hace todo" — aparece con frecuencia en propuestas de cliente: "un copilot para el equipo comercial que lea correo, consulte CRM, envíe propuestas, haga seguimiento, avise de renovaciones". Nuestra respuesta estándar es dibujar esa petición como cinco o seis agentes independientes orquestados con protocolos encadenados. La diferencia en coste total de propiedad a doce meses es fácilmente 3x o 4x. Si tu agente necesita un prompt de sistema de 2.000 palabras para funcionar, casi con seguridad tienes varios agentes pegados con cinta aislante. Sepáralos.
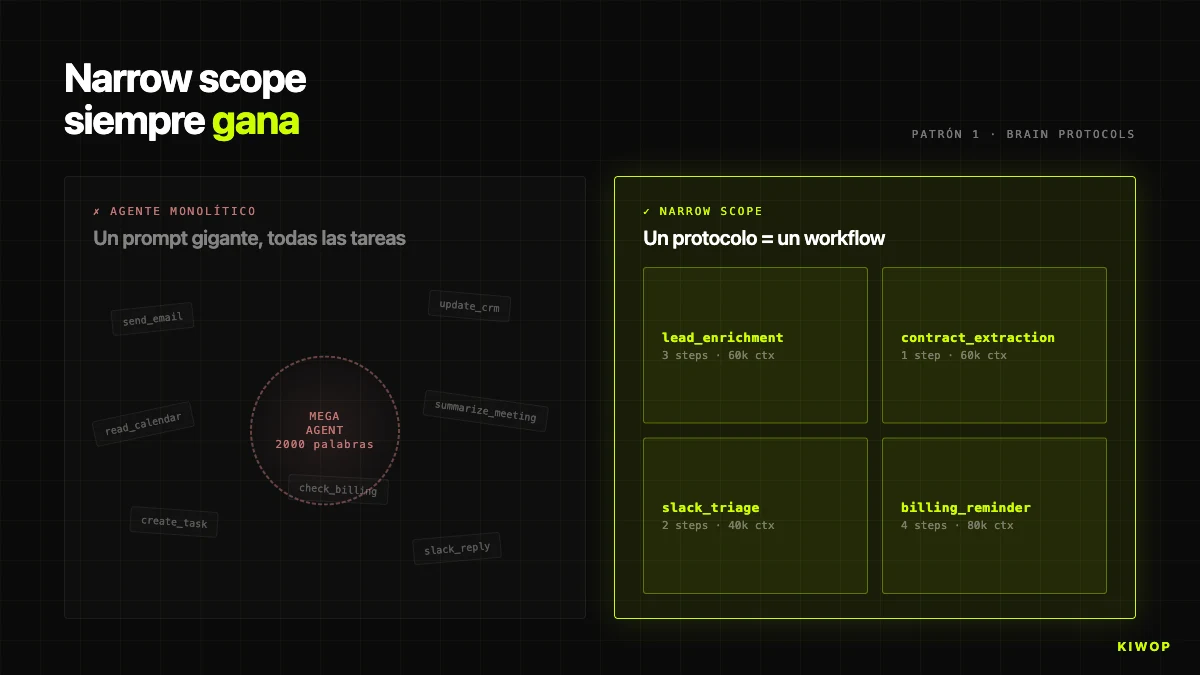
Patrón 2: Confirmación humana antes de acciones irreversibles
Los LLMs modernos se equivocan aproximadamente un 1% de las veces en tareas cerradas que se consideran "fáciles". No es un número medido por nosotros con rigor — es el orden de magnitud de benchmarks públicos y se corresponde con nuestra experiencia interna. Suena bajo hasta que haces la cuenta.
Un agente que ejecuta 1.000 operaciones al día con un 1% de error produce 10 operaciones erróneas diarias. Si son lectura, el coste es cero. Si son escritura (enviar un correo, crear un evento, modificar un registro, borrar algo), el coste puede ser desde una molestia hasta un post mortem. Diez incidentes al día son insostenibles.
La regla sin excepciones: el agente nunca ejecuta acciones irreversibles sin confirmación humana explícita. En PA, descrito en el post del asistente personal, el agente puede leer el buzón entero pero no envía sin que el humano escriba "sí". En Brain, el equivalente es el flag auto_execute_actions en BrainProtocol: por defecto en false, cuando un step genera una action (crear tarea, propuesta, alerta), lo que se crea es una AgentProposal pendiente de aprobación, no la acción final.
Solo habilitamos auto_execute_actions = true cuando se cumplen tres condiciones: (1) la acción es idempotente y reversible, (2) tras varios cientos de runs verificados manualmente, la tasa de error observada se mantiene por debajo del 1%, aunque la medición no es metodológicamente rigurosa, y (3) el cliente firma la habilitación por escrito. Actualmente, menos de una cuarta parte de los protocolos corre en modo autónomo.
Una trampa: la confirmación no debe ser "¿estás seguro? [sí/no]" porque el usuario se acostumbra y hace clic sin leer. El handshake bien diseñado muestra exactamente qué va a pasar (destinatario, asunto, cuerpo del correo; entidad DB a modificar; importe exacto). Si el humano tiene que saber lo que confirma, se lee lo que confirma.
Este patrón conecta con consultoría IA: la conversación empieza por "¿qué acciones puede tomar el agente sin preguntar?" y casi siempre la respuesta inicial se queda corta. Ampliar permisos es fácil, retirarlos tras un incidente es caro.
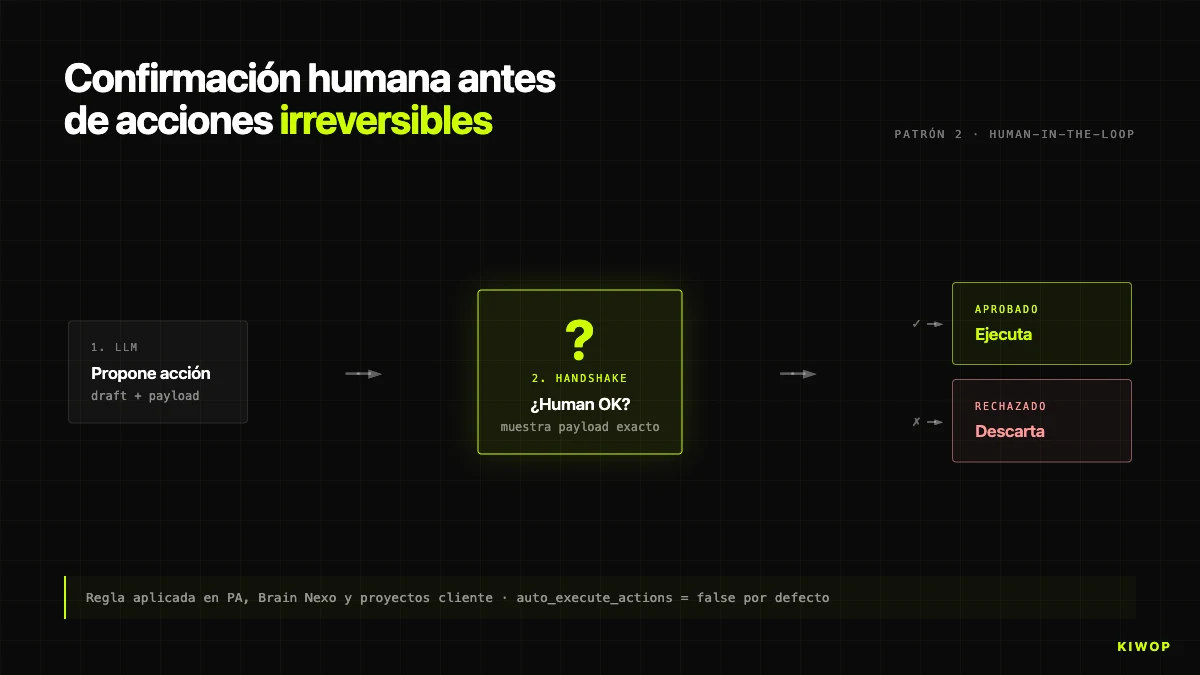
Patrón 3: Límites estrictos de context y steps
Los agentes multi-step son golosos. Cada step añade información al contexto, cada llamada puede devolver respuestas largas, y sin un techo explícito el contexto crece hasta que uno de tres problemas te golpea: coste desproporcionado, alucinación por contexto inflado o timeout del proveedor.
En BrainProtocolEngine tenemos dos constantes duras:
MAX_STEPS = 10 significa que un protocolo no puede ejecutar más de 10 steps por run, sin importar cuántos tenga definidos. Protocolos con más de 10 steps casi siempre son un diseño que habría sido mejor dividir en dos encadenados; el límite fuerza esa conversación.
MAX_CONTEXT_CHARS = 300000 aplica al contexto total acumulado. Si el JSON supera los 300.000 caracteres, se registra un warning y el prompt se trunca con un mensaje explícito al modelo: "CONTEXTO TRUNCADO POR LÍMITE DE TAMAÑO". El límite se calibra para caber cómodamente en una ventana de 200K tokens y alejarse del 1M de los modelos con contexto extendido — porque, como veremos después, contexto grande y contexto útil son cosas muy distintas.
Como referencia orientativa, estos son los presupuestos que usamos por defecto según el tipo de agente:
Estos valores no son universales — son los que han pasado la prueba de producción en nuestros workloads. Si estás arrancando, empieza conservador y sube solo cuando tengas datos que lo justifiquen.
Patrón 4: MCP como lenguaje común antes que integraciones ad hoc
Antes de 2025, cada integración entre un agente y un sistema externo era código a medida: un conector para Gmail, otro para Calendar, otro para Slack, cada uno con su autenticación y mantenimiento. La mayor parte del coste de construir un agente no venía del prompt ni del modelo, venía del glue code.
Model Context Protocol (MCP) cambió eso durante 2025 y ha consolidado su posición desde entonces. MCP es un estándar abierto para que cualquier modelo hable con cualquier herramienta usando una misma gramática de "tool calls". Publicado por Anthropic en 2024, fue adoptado por OpenAI, Google y los principales clientes de IA. Hoy, la mayoría de integraciones que construimos se apoyan en servidores MCP preexistentes en vez de escribir cliente nuevo.
El impacto en coste de desarrollo es brutal. Para un agente que necesite hablar con Gmail, Calendar, Drive, Slack, Linear y GitHub, la diferencia entre escribir seis conectores propios con sus OAuths y enchufar seis servidores MCP existentes es del orden de semanas frente a horas. Y el mantenimiento — cuando un servicio cambia un endpoint o rota credenciales — deja de ser tu problema.
Si no tienes claro qué es MCP, WebMCP: tu web preparada para agentes IA lo explica con ejemplos concretos. Para la comparativa con protocolos hermanos, MCP, WebMCP y A2A: los protocolos que definen los agentes IA entra en el detalle.
Regla operativa: antes de escribir un conector propio, comprueba si existe un MCP oficial o comunitario. Si existe y lo mantiene un equipo serio, úsalo. MCP no es panacea — tiene puntos ciegos (IMAP corporativo, Telegram, CRMs verticales). Para esos huecos escribimos scripts propios, pero con la forma de un MCP para que, si mañana alguien publica uno, el cambio sea indoloro.
Patrón 5: Anti-alucinación explícita en el prompt
Los LLMs alucinan. Es una característica arquitectural del transformer, no un bug que vaya a desaparecer con el siguiente modelo. Cualquier agente que trate datos reales tiene que convivir con esa realidad.
La estrategia que mejor nos ha funcionado es inscribir las reglas anti-alucinación directamente en el prompt de sistema, de forma literal y redundante. No "por favor, sé preciso". Reglas numeradas, en mayúsculas los términos críticos, con instrucciones operativas de qué hacer ante la duda.
El ejemplo más claro en producción es el extractor de contratos de Nexo. El prompt de sistema del OpenAiContractExtractor arranca con estas instrucciones:
CRITICAL RULES: 1. NEVER invent or hallucinate data. If a field is not clearly stated, return null. 2. Return ONLY valid JSON. No explanations outside the JSON. 3. For each field, provide: - value: The extracted value (or null if not found) - confidence: A score from 0.0 to 1.0 indicating how confident you are - evidence: A brief quote from the document supporting your extraction (or null) 4. Dates MUST be in YYYY-MM-DD format. If day/month is unclear, return null.
Tres mecanismos entran en juego:
Permitir al modelo decir "no lo sé". Devolver null cuando un dato no está claro es un resultado válido; inventarlo, no. Mucha gente escribe prompts sin salida explícita a "dato no disponible" y el modelo, forzado, rellena con lo más plausible que encuentra.
Pedir confianza y evidencia por campo. La confidence obliga al modelo a meta-razonar sobre su certeza. La evidence — cita literal del documento — es verificable: si la cita no aparece, se descarta el campo. El output pasa a ser auditable en vez de caja negra.
Formatos estructurados estrictos. Fechas en YYYY-MM-DD, números como tipos numéricos, enumeraciones cerradas ("fixed" | "hourly" | "monthly"). Cuanto más cerrado es el formato, menos espacio para alucinación creativa.
Esta estrategia no elimina la alucinación pero la reduce a niveles tolerables con confirmación humana. En nuestros datos internos, pasar de prompts laxos a prompts con reglas anti-alucinación literales redujo los campos falsamente rellenados en aproximadamente un factor de cinco, sin cambiar el modelo.
Patrón 6: Observabilidad obligatoria
La primera vez que un cliente pregunta "¿por qué el agente hizo eso?" y no tienes datos para contestar, aprendes que la observabilidad no es opcional. Cada ejecución tiene que dejar un rastro auditable: tokens, latencia, steps ejecutados, inputs, outputs, quién disparó y desde dónde.
En Brain, esto se implementa con BrainProtocolRun. Cada ejecución crea un registro con:
status:running | completed | failed | cancelledstep_results: array con un objeto por step ejecutado (nombre, tipo, duración en ms, estado, resultado o error)context: el contexto acumulado, truncado a 50.000 caracteres para almacenamientocurrent_step: en qué step iba cuando se completó o fallótokens_used: tokens totales consumidos (suma input + output de todos losai_call)started_at/completed_attriggered_by_user_id/trigger_source: quién y desde qué canal disparó el runerror: si falló, el mensaje completo
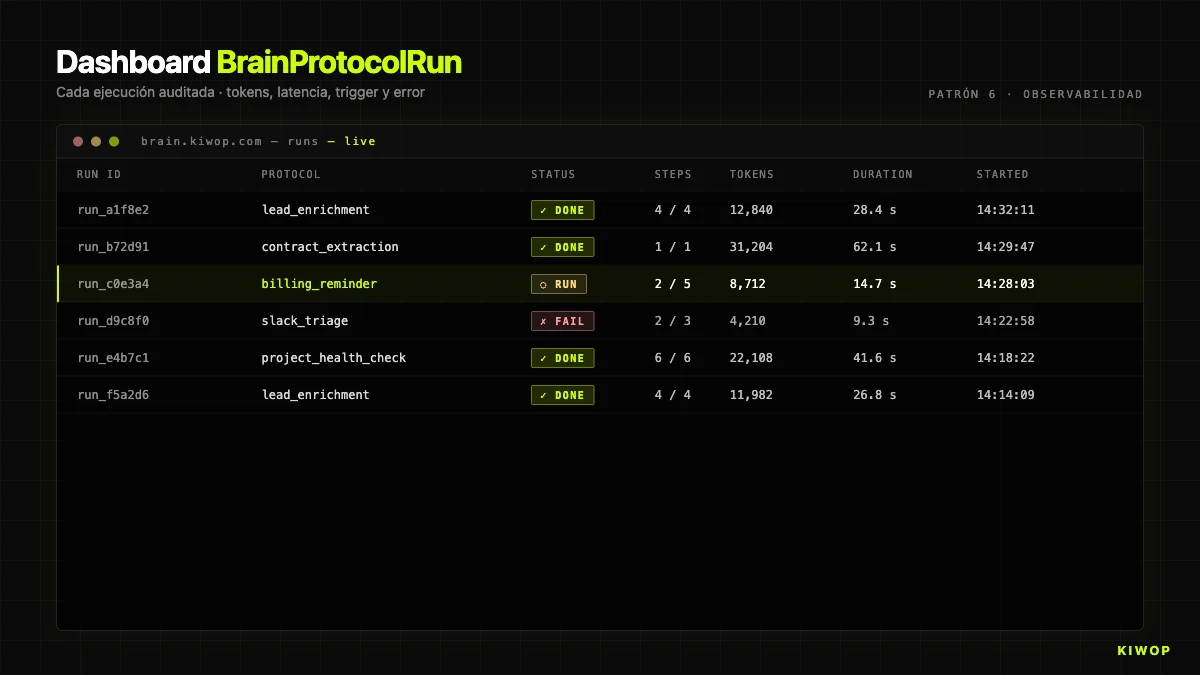
Esa estructura responde las tres preguntas que siempre se acaban haciendo: ¿cuánto cuesta? (suma de tokens_used × precio por token), ¿por qué falló? (error + step_results hasta el step que falló), ¿por qué tardó tanto? (duration_ms por step).
Dos reglas adicionales aprendidas por la vía dolorosa:
Logs consultables en caliente. No sirven archivos que nadie mira. La DB aplicativa está bien para volumen bajo-medio; para volumen alto, un stack dedicado (Datadog, Grafana, Honeycomb) paga el coste antes del primer incidente grave.
Guarda siempre `trigger_source` y `triggered_by_user_id`. Cuando algo sale mal, la primera pregunta es forense: ¿lo disparó el scheduler, un usuario, una integración externa, un webhook? Sin esa trazabilidad, cada incidente es una investigación arqueológica.
Este patrón está en el corazón de nuestra oferta de LLMOps: gestionar modelos en producción no es gestionar los modelos — es gestionar la telemetría, el coste, la calidad y la seguridad de los agentes que los usan.
Patrón 7: Agentic timeouts con retry exponencial
Los LLMs externos fallan — picos de demanda, cortes de red, sesiones colgadas. Un agente que no maneja timeouts explícitos es un agente que se cuelga, y un agente colgado es peor que uno que falla: el humano no sabe qué pasa.
Tres componentes en nuestra política:
Timeouts explícitos por step. En Brain cada ai_call define su max_tokens y timeout efectivo. Default del cliente: 120 segundos. Si un step lo supera, el engine lo marca como failed en vez de dejar el run colgado.
Retry exponencial con límite. Para errores transitorios (rate limit, 5xx, timeouts de red) reintentamos con backoff: delay = base * 2^attempt + jitter, base = 500ms, máximo 3 reintentos, tope 30 segundos. Absorbe blips sin martillear al proveedor.
Fallo rápido en errores no recuperables. Los 4xx (input inválido, credenciales caducadas, cuota agotada) no se reintentan — el siguiente intento va a fallar igual. Si el step está marcado critical: true, aborta el protocolo entero.
Nota para agentes MCP: los servidores MCP también se cuelgan, y el cliente no siempre propaga bien el timeout. En PA hemos envuelto algunas llamadas MCP con timeout a nivel de proceso. La lección: no confíes en timeouts de una sola capa, apila varios.
Patrón 8: Diseño agnóstico al proveedor de LLM
El 4 de abril de 2026 aprendimos en primera persona el valor de tener la infraestructura desacoplada del proveedor. Ese día Anthropic cortó los tokens OAuth que permitían usar suscripciones Claude Max y Pro con terceros harnesses, y varios agentes del ecosistema se quedaron sin backend. Contamos la historia en De OpenClaw a PA con Claude Code y MCP y dedicamos un post específico a la construcción paso a paso de PA con Claude Code y MCP.
La infraestructura de Nexo no se vio afectada porque estaba diseñada para ser agnóstica al proveedor. El componente clave es AiGateway, una abstracción que centraliza las llamadas a LLM y decide en runtime qué cliente usar según la conexión del workspace y la feature.
Detrás de chat(), AiGateway resuelve una WorkspaceAiConnection, construye el cliente (AnthropicClient, OpenAiClient o ClaudeCliClient para console-auth) y emite con el modelo correcto. Cambiar un workspace de Anthropic a OpenAI es un cambio de configuración, no de código.
Tres efectos concretos:
Resiliencia. Si Anthropic tiene una incidencia, rotamos a OpenAI en minutos sin tocar código de protocolo. El 4 de abril no tuvimos que hacerlo porque el corte afectó a OAuth de Claude Code, no a la API que usa Nexo, pero la capacidad estaba probada.
Elección por feature. Chat usa Haiku 4.5 por coste; resúmenes de reunión usan Opus 4.7 por calidad; extracción de contratos usa GPT-4o por su modo JSON estructurado. La abstracción permite optimizar cada feature por separado.
Optimización por workspace. Workspaces pequeños sobre modelos baratos, workspaces premium sobre modelos premium. Decisión en workspaces_ai_connections, no en código.
La regla: nunca llames a la API del proveedor directamente desde tu código de negocio. Pasa siempre por una capa intermedia propia. Cuando el proveedor cambie algo — y va a cambiar — el impacto se queda en esa capa.
Comparativa de proveedores LLM a abril 2026
Esta tabla resume cómo vemos hoy los tres grandes proveedores tier-top desde la perspectiva de un agente en producción. No es un ranking absoluto — es una guía de cuándo tiene sentido apoyarse en cada uno dentro de una arquitectura multi-proveedor como la del patrón anterior.
Comparativa a abril 2026; modelos y precios evolucionan rápido.
A continuación desgranamos cuatro antipatrones IA de agentes que hemos visto descarrilar proyectos — tanto nuestros como de clientes — cuando alguna de las disciplinas anteriores no se aplica.
Antipatrón 1: Agente autónomo que actúa sin supervisión
El relato del "agente autónomo que decide solo" suena bien en slides y acaba mal en incidentes. La razón no es filosófica, es estadística: cualquier proceso estocástico (y los LLMs lo son) cometerá errores, y errores sin supervisión humana se convierten en daños acumulados.
Modos típicos de fallo:
Bucle infinito. Un agente que "decide qué hacer a continuación" puede invocar la misma tool 50 veces seguidas. Sin un tope como MAX_STEPS = 10, la ejecución consume tokens sin valor.
Cascada de efectos. Una factura errónea dispara un webhook que envía correo al cliente, que abre ticket en CRM, que notifica al equipo comercial. Deshacer la cadena cuesta más que el error original.
Corrupción de estado. Un agente con permisos de escritura que malinterpreta una instrucción puede modificar registros imposibles de reconstruir sin backup previo.
Regla práctica: ningún agente debería tener permisos de escritura irreversibles sin human-in-the-loop al inicio. Habilitar modo autónomo para acciones específicas es posible tras cientos de runs verificados y tasa de error por debajo del umbral del dominio. Nunca antes. Nunca por defecto.
Antipatrón 2: Confiar en el contexto "infinito" del modelo
Los modelos actuales presumen ventanas de 200K, 500K y hasta 1M tokens. El mensaje que ha calado es que "ahora puedes meter lo que quieras". Eso no es cierto en producción.
Tres razones para no confiar en la ventana completa:
Degradación de calidad con contexto inflado. Los benchmarks públicos y nuestras evaluaciones internas muestran que la precisión de recuperación (needle-in-a-haystack) se degrada al acercarse al límite. Un modelo que encuentra un dato al 99% a 50K tokens puede bajar al 80% o menos a 500K tokens.
Coste proporcional al input. Un contexto de 300K tokens cuesta seis veces más que uno de 50K. Con 100 llamadas diarias, la diferencia mensual entre "cabe todo" y "solo lo necesario" se cuenta en cientos o miles de euros.
Latencia del first-token. Un prompt de 300K tokens puede tardar varios segundos en ser procesado antes de que el modelo empiece a responder, incluso con prompt caching. Para experiencia conversacional, mata la percepción de rapidez.
Disciplina: el contexto debe ser lo mínimo necesario, no lo máximo posible. En Brain, los data_filter existen precisamente para reducir el contexto entre steps: un connector_fetch puede traer 500 correos; el filtro los reduce a los 20 que cumplen criterios; el ai_call posterior solo ve esos 20. El patrón RAG nace de la misma disciplina — para bases documentales grandes, RAG empresarial es la arquitectura correcta, no un contexto gigante.
Antipatrón 3: Sin separación de lectura y escritura
Los agentes que leen y escriben en el mismo step son bomba de relojería. Si la llamada falla a mitad, no sabes si la escritura se ejecutó. Si se reintenta, puedes duplicar. Si hay error de interpretación, no tienes snapshot del estado que vio el agente.
Regla: separa lectura y escritura en pasos distintos con materialización explícita entre ambos. En Brain, la tipología de steps lo refleja: connector_fetch y db_query son read-only; action es la única que escribe. Un protocolo bien diseñado tiene forma "N steps de lectura, 0 o 1 de escritura al final". Si necesitas escribir más de una vez, partes el protocolo en dos.
En integraciones de cliente aplicamos el mismo patrón: el agente genera una propuesta (objeto en DB con el borrador o el cambio), y un segundo paso — con confirmación humana — ejecuta la acción. Permite auditoría, retry seguro, rollback y human-in-the-loop sin rediseñar el flujo. Excepción legítima: operaciones idempotentes con clave natural. Para el resto, separa.
Antipatrón 4: Un único proveedor de LLM crítico
Ya lo hemos tocado en el patrón 8, pero merece subrayarse: un agente crítico que depende de un único proveedor es un agente frágil. No porque el proveedor sea malo, sino porque cualquier decisión unilateral — cambio de precio, política, sunset de modelo, caída del servicio, corte de OAuth — puede dejarte sin backend.
El 4 de abril de 2026 Anthropic cortó OAuth de Claude Max para terceros. OpenAI ajusta precios de API periódicamente. Google cambia cuotas de Gemini. No son movimientos maliciosos — son decisiones de negocio — pero todos tienen el mismo efecto sobre quien construyó asumiendo que nada cambiaría.
Tres capas mínimas de desacoplamiento:
Abstracción propia tipo AiGateway. Tu código habla con tu abstracción, no con el SDK del proveedor.
Credenciales y config en DB. Cambiar de modelo o proveedor no debería requerir deploy, sino un UPDATE.
Prompts portables. Si tu prompt solo funciona con un modelo específico, tienes un prompt frágil. Los prompts bien escritos (reglas explícitas, formato estructurado) funcionan aceptablemente en los modelos tier-top de los tres grandes. Si las diferencias son grandes, el problema está en el prompt, no en el modelo.
Con estas tres capas, cuando el proveedor A cambia algo tu coste de migración es horas, no semanas.
Cómo aplicamos estos patrones en los servicios de Kiwop

Estos ocho patrones y cuatro antipatrones son el marco con el que entregamos proyectos de IA en Kiwop. Cuando un cliente llega con "quiero un agente para X", la conversación sigue este orden:
Primero, consultoría IA para delimitar el scope real. Casi siempre lo que pide el cliente son tres o cuatro agentes atados a lo mismo; el trabajo consultivo es separarlos y decidir qué es autónomo y qué requiere handshake humano.
Segundo, desarrollo de agentes IA con arquitectura que aplica los patrones 3 al 8 por defecto: límites, MCPs, anti-alucinación, observabilidad, timeouts, abstracción del proveedor.
Tercero, integración de LLMs sobre MCP cuando existe y sobre conectores propios cuando no.
Cuarto, una vez en producción, LLMOps para gestionar ciclo de vida: observabilidad, costes por workspace, rotación de modelos, respuesta ante incidentes.
El objetivo: que el agente que entregamos el día 1 siga funcionando el día 365 con coste predecible.
Preguntas frecuentes
¿Cuándo tiene sentido construir un agente IA en producción?
Cuando hay una tarea repetitiva semi-estructurada, con criterios claros de éxito y que permite tolerar un pequeño porcentaje de errores gracias a confirmación humana. Ejemplos: triaje de correo o tickets, enriquecimiento de leads, extracción de documentos, resumen de reuniones, clasificación de mensajes. No tiene sentido para tareas con coste de error muy alto sin supervisión, ni para tareas resolubles con una regla determinista sin LLM.
¿Qué modelo de LLM elegir para un agente IA?
Depende de la feature. Para chat y multi-step con prioridad en coste, Haiku 4.5 o GPT-4o-mini. Para razonamiento complejo y extracción de calidad, Sonnet 4.5, Opus 4.7 o GPT-4o. Para JSON estricto, GPT-4o por su modo nativo. Empieza con el modelo más barato que pasa tus evaluaciones propias y sube de tier solo cuando los datos lo justifiquen.
¿Cuánto cuesta desplegar un agente IA en producción?
Desarrollo entre 6.000 y 15.000 euros para un agente narrow scope con MCPs existentes (sube con integraciones a medida). Coste operativo: un agente de ~500 interacciones diarias sobre Haiku 4.5 puede moverse en 50-150 euros mensuales en tokens; sobre Opus 4.7 la factura puede multiplicarse por 10 o más. Diseña para coste bajo y sube solo donde añada valor visible.
¿Es seguro un agente IA que toca datos de clientes?
Puede serlo: (1) datos sensibles revisados antes del prompt; (2) acciones irreversibles con confirmación humana; (3) cada run auditado con trazabilidad. Para contenido regulado (sanitario, legal, financiero con secreto profesional), valora modelos on-premise o regionales con acuerdos específicos de no entrenamiento. Un proyecto de RAG empresarial con infraestructura controlada suele ser la opción correcta.
¿Cómo evito que mi agente alucine datos?
Varias capas: (1) prompt con reglas anti-alucinación literales ("si no tienes el dato, devuelve null"); (2) confianza y evidencia por campo para output auditable; (3) formatos estructurados con enum cerrados; (4) validación determinista antes de sistemas críticos; (5) confirmación humana en operaciones irreversibles. Ninguna sola basta; las cinco juntas reducen la alucinación a niveles tolerables.
¿Qué es un Brain protocol en Nexo?
Un workflow declarativo con steps tipados (connector_fetch, data_filter, ai_call, db_query, action, condition) ejecutados secuencialmente con contexto mutable. A diferencia de un agente "todoterreno" que decide qué tool llamar, un protocolo es determinista en la secuencia pero flexible dentro de cada step. Límites duros (MAX_STEPS = 10, MAX_CONTEXT_CHARS = 300000) y cada run auditado en BrainProtocolRun con tokens, latencia por step, trigger source y resultado.
¿Qué hago si mi proveedor de LLM cambia precios o cierra una modalidad de acceso?
Si estás desacoplado (patrón 8), rotar es configuración: verifica que los prompts funcionen con el modelo nuevo y reevalúa coste. Si no lo estabas, primero introduce la capa de abstracción, separa credenciales en config y prueba los prompts en al menos dos proveedores. El trabajo amortiza muy rápido la primera vez que evita un incidente.
¿Puedo empezar con un agente autónomo y añadir confirmación después?
Al revés: empieza con confirmación humana en todas las acciones irreversibles y habilita autónomo solo cuando tengas datos de tasa de error baja. Añadir confirmación tras un incidente es más caro que retirarla cuando el agente demuestra solvencia, sobre todo en dominios sensibles (dinero, correos a clientes, CRM).
Conclusión: los patrones escalan, los antipatrones también
Los agentes IA se han vuelto infraestructura: no la cosa nueva que probamos, sino la cosa que teníamos y necesitamos que siga funcionando. Ese cambio de estatus trae disciplinas prestadas de ingeniería clásica — observabilidad, límites explícitos, separación de responsabilidades, desacoplamiento del proveedor — que el hype de los primeros años había dejado en segundo plano.
Los ocho patrones y cuatro antipatrones de este artículo son lo que, en nuestra experiencia, separa un agente que sobrevive doce meses en producción de uno que hay que reconstruir a los tres. Los antipatrones IA más caros no son los fallos técnicos sino las decisiones de diseño: dar autonomía sin supervisión, confiar en el contexto infinito, mezclar lectura y escritura, o atarse a un único proveedor. El valor no está en el modelo ni en el prompt — está en la infraestructura que envuelve al prompt y lo hace correcto, auditable, barato y reemplazable el día 365.
Si estás arrancando tu primer agente, o ya tienes uno y sospechas que te cuesta mantenerlo más de lo que te ayuda, en Kiwop — Agencia Digital especializada en Desarrollo de Software e Inteligencia Artificial aplicada para clientes globales en Europa y USA — hacemos desarrollo de agentes IA, consultoría IA, integración de LLMs y LLMOps como piezas coordinadas de un mismo proceso.