Agents IA en producció 2026: patrons i antipatrons després de desplegar a Nexo, PA i projectes de client
Per l'equip de Kiwop · Agència Digital especialitzada en Desenvolupament de Programari i Intel·ligència Artificial aplicada per a clients globals a Europa i els EUA · Publicat el 19 d'abril de 2026 · Última actualització: 19 d'abril de 2026
TL;DR — Quinze mesos desplegant agents IA a Nexo, PA i clients ens deixen 8 patrons i 4 antipatrons IA. Regles clau: narrow scope guanya a generalista, confirmació humana abans d'accions irreversibles i mai lock-in amb un únic LLM. Si ja tens un agent en producció o estàs a punt de desplegar-lo, aquí tens el marc complet.

L'any 2026 és el primer en què els agents IA deixen de ser demos de conferència i passen a ser infraestructura que algú ha de reiniciar a les 3 de la matinada quan un step falla. A Kiwop fa des del gener de 2025 que construïm agents que viuen en producció: dins del nostre SaaS propi Nexo, com a eines internes de l'equip, i en projectes de client.
Aquest article recull les decisions d'arquitectura que han sobreviscut a aquests quinze mesos. Cada patró ve d'un incident concret, un cost que no volíem tornar a pagar o una reclamació que ens va obligar a replantejar. Cada antipatró és alguna cosa que hem fet malament almenys una vegada. Si estàs a punt de desplegar el teu primer agent, o si ja en tens un i el manteniment costa més que el desenvolupament inicial, aquesta és la guia que ens hauria agradat tenir quan vam començar.
Context: on hem desplegat agents IA a Kiwop
Abans d'entrar en patrons, un mapa d'on parlen les dades. Els agents IA en producció de Kiwop a l'abril de 2026 s'agrupen en tres categories.
Agents a Nexo, el nostre SaaS multi-tenant (HR, CRM, projectes, facturació). Dins de Nexo corren dues famílies: Brain protocols, un motor de workflows multi-step per client i workspace, i l'extractor de contractes per IA que processa PDFs per automatitzar la creació de contractes i fites de facturació. Brain té diverses desenes de protocols actius distribuïts entre workspaces de clients; l'extractor processa diversos centenars de documents mensuals.
PA, l'assistent personal intern. Detallat a D'OpenClaw a PA amb Claude Code i MCP, connecta correu IMAP, Gmail, Slack, Telegram i Google Calendar amb una sessió de Claude Code persistent. El fan servir diàriament diversos membres de l'equip i processa en conjunt una mica per sobre d'1.000 interaccions diàries.
Integracions de client. Agents a mida: un agent de triatge de tickets per a un client fintech, un agent d'enriquiment de leads per a un client e-commerce, i un agent de consulta de documentació legal per a un client consultor. En conjunt ronden les 200-400 execucions diàries.
LLMs que fem servir. Combinem models d'Anthropic (Haiku 4.5, Sonnet 4.5, Opus 4.7) per a la majoria de càrregues conversacionals i de raonament, i models d'OpenAI (GPT-4o i GPT-4o-mini) per a extracció estructurada i workloads sensibles al cost. L'elecció es fa per feature i per workspace mitjançant un AiGateway que veurem més endavant.
Patró 1: Narrow scope sempre guanya a generalista
La primera temptació és fer un agent que "ho faci tot" — llegeix correu, consulta calendari, actualitza CRM, respon Slack, resumeix reunions. Un sol prompt enorme, un sol agent. En demo queda espectacular; en producció no sobreviu. Quan l'agent cobreix massa, el prompt s'omple d'instruccions contradictòries, el LLM perd precisió i quan alguna cosa falla és impossible saber en quina sub-tasca va fallar. Pitjor: modificar la instrucció de "com resumeixes un correu" pot alterar la de "com escrius un missatge de Slack".
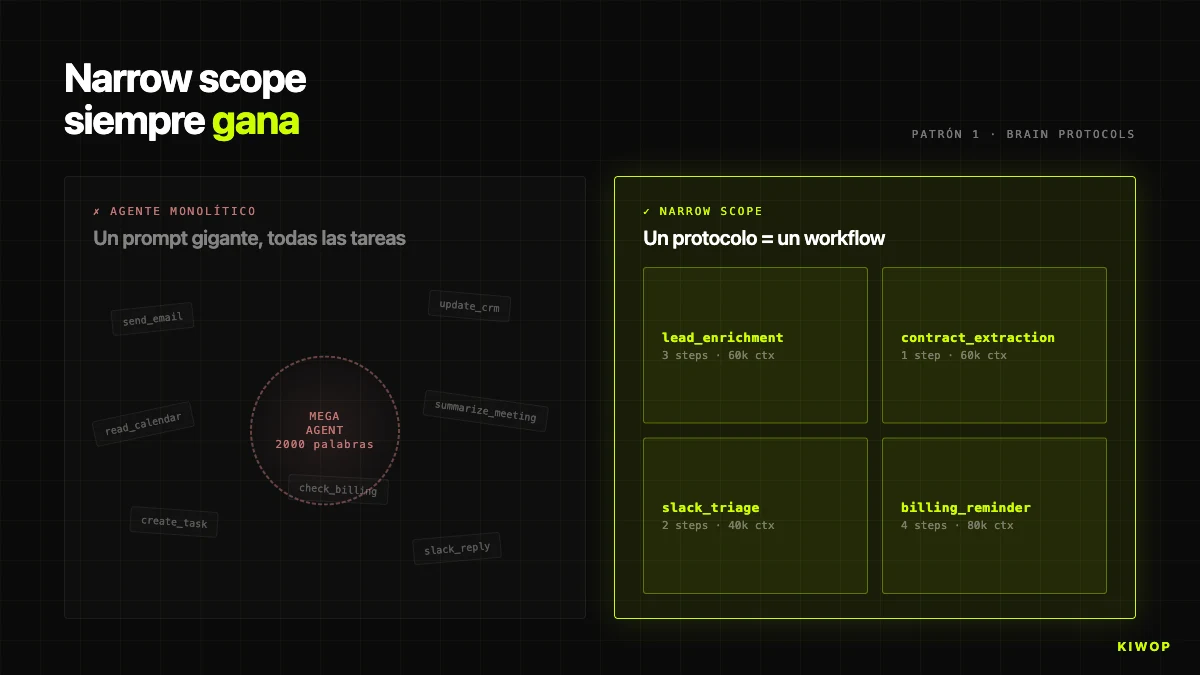
A Brain, la regla és explícita: un protocol = un workflow. Cada protocol té un propòsit únic — lead_enrichment, contract_extraction_followup, project_health_check, weekly_billing_reminder. Si emergeix un cas d'ús nou, es crea un protocol nou, no s'amplia un d'existent. Quan un client demana "que enrichment també enviï un Slack", la resposta correcta és crear un segon protocol encadenat, no inflar el primer.
Això es nota al codi del BrainProtocolEngine: cada protocol té els seus propis steps, el seu trigger_config, el seu project_id i el seu workspace_id. Si enrichment falla per a un lead concret, la resta de protocols del mateix workspace segueixen corrent sense enterar-se.
L'antipatró oposat — "l'agent que ho fa tot" — apareix amb freqüència en propostes de client: "un copilot per a l'equip comercial que llegeixi correu, consulti CRM, enviï propostes, faci seguiment, avisi de renovacions". La nostra resposta estàndard és dibuixar aquesta petició com a cinc o sis agents independents orquestrats amb protocols encadenats. La diferència en cost total de propietat a dotze mesos és fàcilment 3x o 4x. Si el teu agent necessita un prompt de sistema de 2.000 paraules per funcionar, gairebé amb seguretat tens diversos agents enganxats amb cinta aïllant. Separa'ls.
Patró 2: Confirmació humana abans d'accions irreversibles
Els LLMs moderns s'equivoquen aproximadament un 1% de les vegades en tasques tancades que es consideren "fàcils". No és un número mesurat per nosaltres amb rigor — és l'ordre de magnitud de benchmarks públics i es correspon amb la nostra experiència interna. Sona baix fins que fas el càlcul.
Un agent que executa 1.000 operacions al dia amb un 1% d'error produeix 10 operacions errònies diàries. Si són lectura, el cost és zero. Si són escriptura (enviar un correu, crear un esdeveniment, modificar un registre, esborrar alguna cosa), el cost pot anar des d'una molèstia fins a un post mortem. Deu incidents al dia són insostenibles.
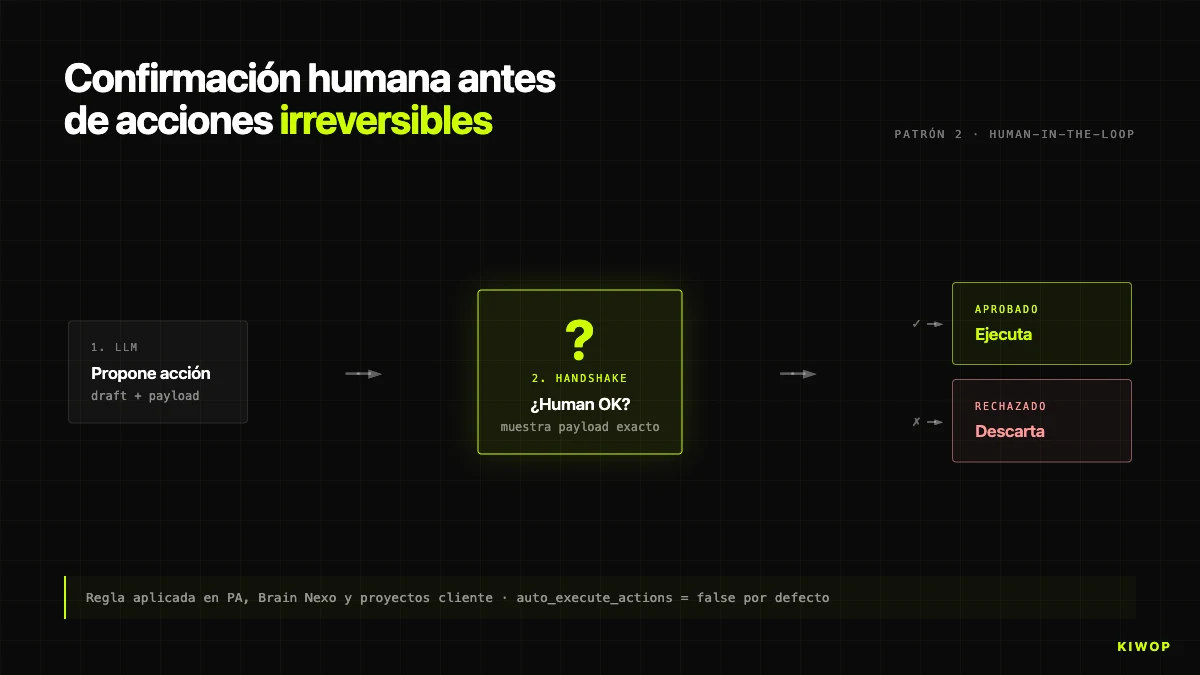
La regla sense excepcions: l'agent mai executa accions irreversibles sense confirmació humana explícita. A PA, descrit al post de l'assistent personal, l'agent pot llegir la bústia sencera però no envia sense que l'humà escrigui "sí". A Brain, l'equivalent és el flag auto_execute_actions a BrainProtocol: per defecte a false, quan un step genera una action (crear tasca, proposta, alerta), el que es crea és una AgentProposal pendent d'aprovació, no l'acció final.
Només habilitem auto_execute_actions = true quan es compleixen tres condicions: (1) l'acció és idempotent i reversible, (2) després de diversos centenars de runs verificats manualment, la taxa d'error observada es manté per sota de l'1%, encara que el mesurament no és metodològicament rigorós, i (3) el client firma l'habilitació per escrit. A l'abril de 2026, menys d'una quarta part dels protocols corre en mode autònom.
Una trampa: la confirmació no ha de ser "estàs segur? [sí/no]" perquè l'usuari s'hi acostuma i fa clic sense llegir. L'handshake ben dissenyat mostra exactament què passarà (destinatari, assumpte, cos del correu; entitat DB a modificar; import exacte). Si l'humà ha de saber el que confirma, es llegeix el que confirma.
Aquest patró connecta amb consultoria IA: la conversa comença per "quines accions pot prendre l'agent sense preguntar?" i gairebé sempre la resposta inicial es queda curta. Ampliar permisos és fàcil, retirar-los després d'un incident és car.
Patró 3: Límits estrictes de context i steps
Els agents multi-step són golafres. Cada step afegeix informació al context, cada crida pot tornar respostes llargues, i sense un sostre explícit el context creix fins que un de tres problemes et colpeja: cost desproporcionat, al·lucinació per context inflat o timeout del proveïdor.
A BrainProtocolEngine tenim dues constants dures:
MAX_STEPS = 10 significa que un protocol no pot executar més de 10 steps per run, sense importar quants en tingui definits. Protocols amb més de 10 steps gairebé sempre són un disseny que hauria estat millor dividir en dos encadenats; el límit força aquesta conversa.
MAX_CONTEXT_CHARS = 300000 aplica al context total acumulat. Si el JSON supera els 300.000 caràcters, es registra un warning i el prompt es trunca amb un missatge explícit al model: "CONTEXT TRUNCAT PER LÍMIT DE MIDA". El límit es calibra per cabre còmodament en una finestra de 200K tokens i allunyar-se del 1M dels models amb context estès — perquè, com veurem després, context gran i context útil són coses molt diferents.
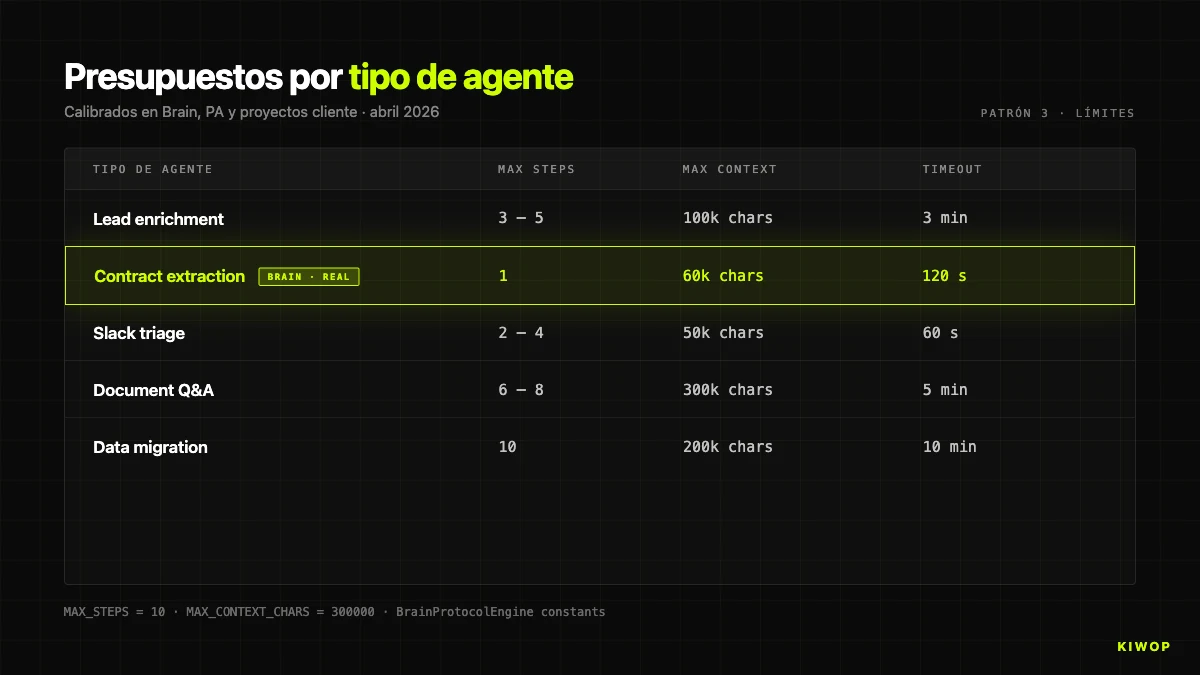
Com a referència orientativa, aquests són els pressupostos que fem servir per defecte segons el tipus d'agent:
Aquests valors no són universals — són els que han passat la prova de producció als nostres workloads. Si estàs arrencant, comença conservador i puja només quan tinguis dades que ho justifiquin.
Patró 4: MCP com a llenguatge comú abans que integracions ad hoc
Abans de 2025, cada integració entre un agent i un sistema extern era codi a mida: un connector per a Gmail, un altre per a Calendar, un altre per a Slack, cadascun amb la seva autenticació i manteniment. La major part del cost de construir un agent no venia del prompt ni del model, venia del glue code.
Model Context Protocol (MCP) va canviar això durant 2025 i ha consolidat la seva posició el 2026. MCP és un estàndard obert perquè qualsevol model parli amb qualsevol eina fent servir una mateixa gramàtica de "tool calls". Publicat per Anthropic el 2024, va ser adoptat per OpenAI, Google i els principals clients d'IA. Avui, la majoria d'integracions que construïm es recolzen en servidors MCP preexistents en comptes d'escriure client nou.
L'impacte en cost de desenvolupament és brutal. Per a un agent que necessiti parlar amb Gmail, Calendar, Drive, Slack, Linear i GitHub, la diferència entre escriure sis connectors propis amb els seus OAuths i endollar sis servidors MCP existents és de l'ordre de setmanes davant d'hores. I el manteniment — quan un servei canvia un endpoint o rota credencials — deixa de ser el teu problema.
Si no tens clar què és MCP, WebMCP: la teva web preparada per a agents IA ho explica amb exemples concrets. Per a la comparativa amb protocols germans, MCP, WebMCP i A2A: els protocols que defineixen els agents IA el 2026 entra en el detall.
Regla operativa: abans d'escriure un connector propi, comprova si existeix un MCP oficial o comunitari. Si existeix i el manté un equip seriós, fes-lo servir. MCP no és panacea — té punts cecs (IMAP corporatiu, Telegram, CRMs verticals). Per a aquests buits escrivim scripts propis, però amb la forma d'un MCP perquè, si demà algú en publica un, el canvi sigui indolor.
Patró 5: Anti-al·lucinació explícita al prompt
Els LLMs al·lucinen. És una característica arquitectural del transformer, no un bug que desaparegui amb el següent model. Qualsevol agent que tracti dades reals ha de conviure amb aquesta realitat.
L'estratègia que millor ens ha funcionat és inscriure les regles anti-al·lucinació directament al prompt de sistema, de forma literal i redundant. No "si us plau, sigues precís". Regles numerades, en majúscules els termes crítics, amb instruccions operatives de què fer davant del dubte.
L'exemple més clar en producció és l'extractor de contractes de Nexo. El prompt de sistema del OpenAiContractExtractor arrenca amb aquestes instruccions:
CRITICAL RULES: 1. NEVER invent or hallucinate data. If a field is not clearly stated, return null. 2. Return ONLY valid JSON. No explanations outside the JSON. 3. For each field, provide: - value: The extracted value (or null if not found) - confidence: A score from 0.0 to 1.0 indicating how confident you are - evidence: A brief quote from the document supporting your extraction (or null) 4. Dates MUST be in YYYY-MM-DD format. If day/month is unclear, return null.
Tres mecanismes entren en joc:
Permetre al model dir "no ho sé". Tornar null quan un dada no és clara és un resultat vàlid; inventar-lo, no. Molta gent escriu prompts sense sortida explícita a "dada no disponible" i el model, forçat, emplena amb el més plausible que troba.
Demanar confiança i evidència per camp. El confidence obliga el model a meta-raonar sobre la seva certesa. L'evidence — cita literal del document — és verificable: si la cita no apareix, es descarta el camp. L'output passa a ser auditable en comptes de caixa negra.
Formats estructurats estrictes. Dates en YYYY-MM-DD, números com a tipus numèrics, enumeracions tancades ("fixed" | "hourly" | "monthly"). Com més tancat és el format, menys espai per a al·lucinació creativa.
Aquesta estratègia no elimina l'al·lucinació però la redueix a nivells tolerables amb confirmació humana. A les nostres dades internes, passar de prompts laxos a prompts amb regles anti-al·lucinació literals va reduir els camps falsament emplenats en aproximadament un factor de cinc, sense canviar el model.
Patró 6: Observabilitat obligatòria
La primera vegada que un client pregunta "per què l'agent va fer això?" i no tens dades per contestar, aprens que l'observabilitat no és opcional. Cada execució ha de deixar un rastre auditable: tokens, latència, steps executats, inputs, outputs, qui va disparar i des d'on.
A Brain, això s'implementa amb BrainProtocolRun. Cada execució crea un registre amb:
status:running | completed | failed | cancelledstep_results: array amb un objecte per step executat (nom, tipus, duració en ms, estat, resultat o error)context: el context acumulat, truncat a 50.000 caràcters per a emmagatzematgecurrent_step: en quin step anava quan es va completar o fallartokens_used: tokens totals consumits (suma input + output de tots elsai_call)started_at/completed_attriggered_by_user_id/trigger_source: qui i des de quin canal va disparar el runerror: si va fallar, el missatge complet
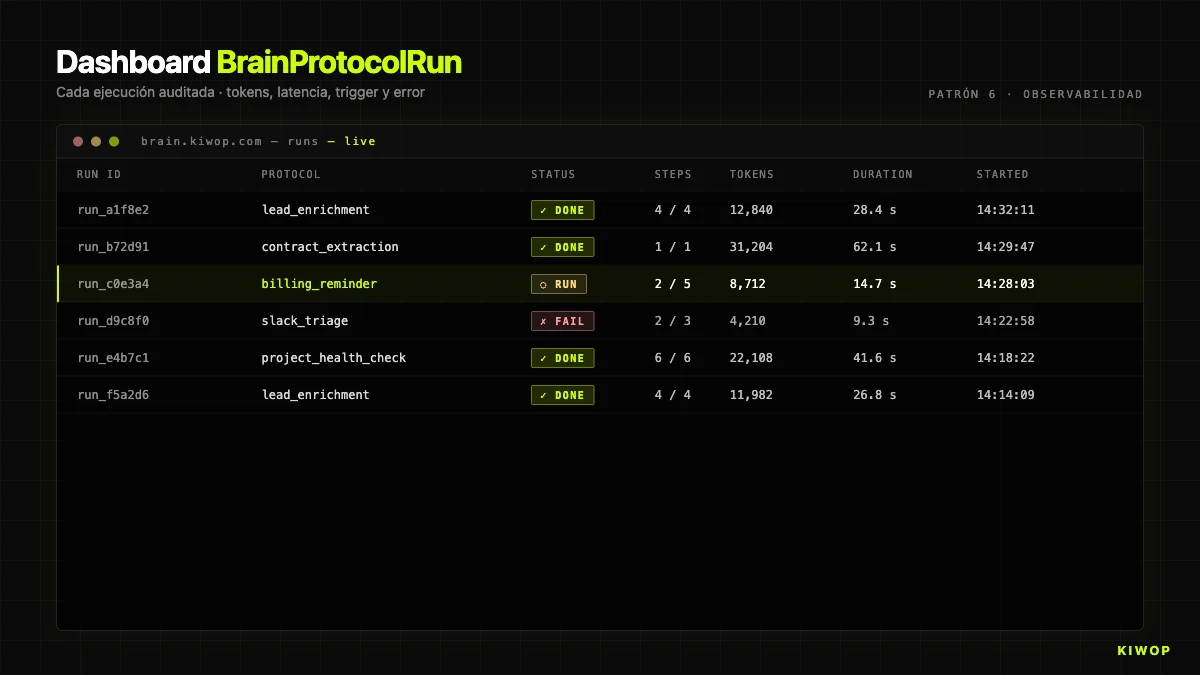
Aquesta estructura respon les tres preguntes que sempre s'acaben fent: quant costa? (suma de tokens_used × preu per token), per què va fallar? (error + step_results fins al step que va fallar), per què va trigar tant? (duration_ms per step).
Dues regles addicionals apreses per la via dolorosa:
Logs consultables en calent. No serveixen arxius que ningú mira. La DB aplicativa està bé per a volum baix-mitjà; per a volum alt, un stack dedicat (Datadog, Grafana, Honeycomb) paga el cost abans del primer incident greu.
Desa sempre `trigger_source` i `triggered_by_user_id`. Quan alguna cosa surt malament, la primera pregunta és forense: ho va disparar el scheduler, un usuari, una integració externa, un webhook? Sense aquesta traçabilitat, cada incident és una investigació arqueològica.
Aquest patró és al cor de la nostra oferta de LLMOps: gestionar models en producció no és gestionar els models — és gestionar la telemetria, el cost, la qualitat i la seguretat dels agents que els fan servir.
Patró 7: Agentic timeouts amb retry exponencial
Els LLMs externs fallen — pics de demanda, talls de xarxa, sessions penjades. Un agent que no gestiona timeouts explícits és un agent que es penja, i un agent penjat és pitjor que un que falla: l'humà no sap què passa.
Tres components a la nostra política:
Timeouts explícits per step. A Brain cada ai_call defineix el seu max_tokens i timeout efectiu. Default del client: 120 segons. Si un step el supera, l'engine el marca com a failed en comptes de deixar el run penjat.
Retry exponencial amb límit. Per a errors transitoris (rate limit, 5xx, timeouts de xarxa) reintentem amb backoff: delay = base * 2^attempt + jitter, base = 500ms, màxim 3 reintents, topall 30 segons. Absorbeix blips sense martellejar el proveïdor.
Fallada ràpida en errors no recuperables. Els 4xx (input invàlid, credencials caducades, quota esgotada) no es reintenten — el següent intent fallarà igual. Si l'step està marcat critical: true, avorta el protocol sencer.
Nota per a agents MCP: els servidors MCP també es pengen, i el client no sempre propaga bé el timeout. A PA hem embolicat algunes crides MCP amb timeout a nivell de procés. La lliçó: no confiïs en timeouts d'una sola capa, apila'n diverses.
Patró 8: Disseny agnòstic al proveïdor de LLM
El 4 d'abril de 2026 vam aprendre en primera persona el valor de tenir la infraestructura desacoblada del proveïdor. Aquell dia Anthropic va tallar els tokens OAuth que permetien fer servir subscripcions Claude Max i Pro amb tercers harnesses, i diversos agents de l'ecosistema es van quedar sense backend. Expliquem la història a D'OpenClaw a PA amb Claude Code i MCP i dediquem un post específic a la construcció pas a pas de PA amb Claude Code i MCP.
La infraestructura de Nexo no es va veure afectada perquè estava dissenyada per ser agnòstica al proveïdor. El component clau és AiGateway, una abstracció que centralitza les crides a LLM i decideix en runtime quin client fer servir segons la connexió del workspace i la feature.
Darrere de chat(), AiGateway resol una WorkspaceAiConnection, construeix el client (AnthropicClient, OpenAiClient o ClaudeCliClient per a console-auth) i emet amb el model correcte. Canviar un workspace d'Anthropic a OpenAI és un canvi de configuració, no de codi.
Tres efectes concrets:
Resiliència. Si Anthropic té una incidència, rotem a OpenAI en minuts sense tocar codi de protocol. El 4 d'abril no ho vam haver de fer perquè el tall va afectar OAuth de Claude Code, no l'API que fa servir Nexo, però la capacitat estava provada.
Elecció per feature. Xat fa servir Haiku 4.5 per cost; resums de reunió fan servir Opus 4.7 per qualitat; extracció de contractes fa servir GPT-4o pel seu mode JSON estructurat. L'abstracció permet optimitzar cada feature per separat.
Optimització per workspace. Workspaces petits sobre models barats, workspaces premium sobre models premium. Decisió a workspaces_ai_connections, no al codi.
La regla: mai cridis l'API del proveïdor directament des del teu codi de negoci. Passa sempre per una capa intermèdia pròpia. Quan el proveïdor canviï alguna cosa — i canviarà — l'impacte es queda en aquesta capa.
Comparativa de proveïdors LLM a abril de 2026
Aquesta taula resumeix com veiem avui els tres grans proveïdors tier-top des de la perspectiva d'un agent en producció. No és un rànquing absolut — és una guia de quan té sentit recolzar-se en cadascun dins d'una arquitectura multi-proveïdor com la del patró anterior.
Comparativa a abril de 2026; models i preus evolucionen ràpid.
A continuació desgranem quatre antipatrons IA d'agents que hem vist descarrilar projectes — tant nostres com de clients — quan alguna de les disciplines anteriors no s'aplica.
Antipatró 1: Agent autònom que actua sense supervisió
El relat de "l'agent autònom que decideix sol" sona bé en slides i acaba malament en incidents. La raó no és filosòfica, és estadística: qualsevol procés estocàstic (i els LLMs ho són) cometrà errors, i errors sense supervisió humana es converteixen en danys acumulats.
Modes típics de fallada:
Bucle infinit. Un agent que "decideix què fer a continuació" pot invocar la mateixa tool 50 vegades seguides. Sense un topall com MAX_STEPS = 10, l'execució consumeix tokens sense valor.
Cascada d'efectes. Una factura errònia dispara un webhook que envia correu al client, que obre ticket a CRM, que notifica l'equip comercial. Desfer la cadena costa més que l'error original.
Corrupció d'estat. Un agent amb permisos d'escriptura que malinterpreta una instrucció pot modificar registres impossibles de reconstruir sense backup previ.
Regla pràctica: cap agent no hauria de tenir permisos d'escriptura irreversibles sense human-in-the-loop a l'inici. Habilitar mode autònom per a accions específiques és possible després de centenars de runs verificats i taxa d'error per sota de l'umbral del domini. Mai abans. Mai per defecte.
Antipatró 2: Confiar en el context "infinit" del model
Els models de 2026 presumeixen finestres de 200K, 500K i fins a 1M tokens. El missatge que ha calat és que "ara pots ficar-hi el que vulguis". Això no és cert en producció.
Tres raons per no confiar en la finestra completa:
Degradació de qualitat amb context inflat. Els benchmarks públics i les nostres avaluacions internes mostren que la precisió de recuperació (needle-in-a-haystack) es degrada en acostar-se al límit. Un model que troba una dada al 99% a 50K tokens pot baixar al 80% o menys a 500K tokens.
Cost proporcional a l'input. Un context de 300K tokens costa sis vegades més que un de 50K. Amb 100 crides diàries, la diferència mensual entre "hi cap tot" i "només el necessari" es compta en centenars o milers d'euros.
Latència del first-token. Un prompt de 300K tokens pot trigar diversos segons a ser processat abans que el model comenci a respondre, fins i tot amb prompt caching. Per a experiència conversacional, mata la percepció de rapidesa.
Disciplina: el context ha de ser el mínim necessari, no el màxim possible. A Brain, els data_filter existeixen precisament per reduir el context entre steps: un connector_fetch pot portar 500 correus; el filtre els redueix als 20 que compleixen criteris; el ai_call posterior només veu aquests 20. El patró RAG neix de la mateixa disciplina — per a bases documentals grans, RAG empresarial és l'arquitectura correcta, no un context gegant.
Antipatró 3: Sense separació de lectura i escriptura
Els agents que llegeixen i escriuen al mateix step són bomba de rellotgeria. Si la crida falla a mitges, no saps si l'escriptura es va executar. Si es reintenta, pots duplicar. Si hi ha error d'interpretació, no tens snapshot de l'estat que va veure l'agent.
Regla: separa lectura i escriptura en passos diferents amb materialització explícita entre tots dos. A Brain, la tipologia de steps ho reflecteix: connector_fetch i db_query són read-only; action és l'única que escriu. Un protocol ben dissenyat té forma "N steps de lectura, 0 o 1 d'escriptura al final". Si necessites escriure més d'un cop, parteixes el protocol en dos.
En integracions de client apliquem el mateix patró: l'agent genera una proposta (objecte a DB amb l'esborrany o el canvi), i un segon pas — amb confirmació humana — executa l'acció. Permet auditoria, retry segur, rollback i human-in-the-loop sense redissenyar el flux. Excepció legítima: operacions idempotents amb clau natural. Per a la resta, separa.
Antipatró 4: Un únic proveïdor de LLM crític
Ja ho hem tocat al patró 8, però mereix subratllar-se: un agent crític que depèn d'un únic proveïdor és un agent fràgil. No perquè el proveïdor sigui dolent, sinó perquè qualsevol decisió unilateral — canvi de preu, política, sunset de model, caiguda del servei, tall d'OAuth — pot deixar-te sense backend.
El 4 d'abril de 2026 Anthropic va tallar OAuth de Claude Max per a tercers. OpenAI ajusta preus d'API periòdicament. Google canvia quotes de Gemini. No són moviments maliciosos — són decisions de negoci — però tots tenen el mateix efecte sobre qui va construir assumint que res canviaria.
Tres capes mínimes de desacoblament:
Abstracció pròpia tipus AiGateway. El teu codi parla amb la teva abstracció, no amb el SDK del proveïdor.
Credencials i config a DB. Canviar de model o proveïdor no hauria de requerir deploy, sinó un UPDATE.
Prompts portables. Si el teu prompt només funciona amb un model específic, tens un prompt fràgil. Els prompts ben escrits (regles explícites, format estructurat) funcionen acceptablement als models tier-top dels tres grans. Si les diferències són grans, el problema és al prompt, no al model.
Amb aquestes tres capes, quan el proveïdor A canvia alguna cosa el teu cost de migració és hores, no setmanes.
Com apliquem aquests patrons als serveis de Kiwop

Aquests vuit patrons i quatre antipatrons són el marc amb què entreguem projectes d'IA a Kiwop. Quan un client arriba amb "vull un agent per a X", la conversa segueix aquest ordre:
Primer, consultoria IA per delimitar el scope real. Gairebé sempre el que demana el client són tres o quatre agents lligats al mateix; el treball consultiu és separar-los i decidir què és autònom i què requereix handshake humà.
Segon, desenvolupament d'agents IA amb arquitectura que aplica els patrons 3 al 8 per defecte: límits, MCPs, anti-al·lucinació, observabilitat, timeouts, abstracció del proveïdor.
Tercer, integració de LLMs sobre MCP quan existeix i sobre connectors propis quan no.
Quart, un cop en producció, LLMOps per gestionar cicle de vida: observabilitat, costos per workspace, rotació de models, resposta davant incidents.
L'objectiu: que l'agent que entreguem el dia 1 segueixi funcionant el dia 365 amb cost predictible.
Preguntes freqüents
Quan té sentit construir un agent IA en producció?
Quan hi ha una tasca repetitiva semi-estructurada, amb criteris clars d'èxit i que permet tolerar un petit percentatge d'errors gràcies a confirmació humana. Exemples: triatge de correu o tickets, enriquiment de leads, extracció de documents, resum de reunions, classificació de missatges. No té sentit per a tasques amb cost d'error molt alt sense supervisió, ni per a tasques resolubles amb una regla determinista sense LLM.
Quin model de LLM triar per a un agent el 2026?
Depèn de la feature. Per a xat i multi-step amb prioritat en cost, Haiku 4.5 o GPT-4o-mini. Per a raonament complex i extracció de qualitat, Sonnet 4.5, Opus 4.7 o GPT-4o. Per a JSON estricte, GPT-4o pel seu mode natiu. Comença amb el model més barat que passa les teves avaluacions pròpies i puja de tier només quan les dades ho justifiquin.
Quant costa desplegar un agent IA en producció?
Desenvolupament entre 6.000 i 15.000 euros per a un agent narrow scope amb MCPs existents (puja amb integracions a mida). Cost operatiu: un agent de ~500 interaccions diàries sobre Haiku 4.5 pot moure's en 50-150 euros mensuals en tokens; sobre Opus 4.7 la factura pot multiplicar-se per 10 o més. Dissenya per a cost baix i puja només on aporti valor visible.
És segur un agent IA que toca dades de clients?
Pot ser-ho: (1) dades sensibles revisades abans del prompt; (2) accions irreversibles amb confirmació humana; (3) cada run auditat amb traçabilitat. Per a contingut regulat (sanitari, legal, financer amb secret professional), valora models on-premise o regionals amb acords específics de no entrenament. Un projecte de RAG empresarial amb infraestructura controlada sol ser l'opció correcta.
Com evito que el meu agent al·lucini dades?
Diverses capes: (1) prompt amb regles anti-al·lucinació literals ("si no tens la dada, torna null"); (2) confiança i evidència per camp per a output auditable; (3) formats estructurats amb enum tancats; (4) validació determinista abans de sistemes crítics; (5) confirmació humana en operacions irreversibles. Cap sola basta; les cinc juntes redueixen l'al·lucinació a nivells tolerables.
Què és un Brain protocol a Nexo?
Un workflow declaratiu amb steps tipats (connector_fetch, data_filter, ai_call, db_query, action, condition) executats seqüencialment amb context mutable. A diferència d'un agent "tot terreny" que decideix quina tool cridar, un protocol és determinista en la seqüència però flexible dins de cada step. Límits durs (MAX_STEPS = 10, MAX_CONTEXT_CHARS = 300000) i cada run auditat a BrainProtocolRun amb tokens, latència per step, trigger source i resultat.
Què faig si el meu proveïdor de LLM canvia preus o tanca una modalitat d'accés?
Si estàs desacoblat (patró 8), rotar és configuració: verifica que els prompts funcionin amb el model nou i reavalua cost. Si no ho estaves, primer introdueix la capa d'abstracció, separa credencials a config i prova els prompts en almenys dos proveïdors. El treball amortitza molt ràpid la primera vegada que evita un incident.
Puc començar amb un agent autònom i afegir confirmació després?
Al revés: comença amb confirmació humana en totes les accions irreversibles i habilita autònom només quan tinguis dades de taxa d'error baixa. Afegir confirmació després d'un incident és més car que retirar-la quan l'agent demostra solvència, sobretot en dominis sensibles (diners, correus a clients, CRM).
Conclusió: els patrons escalen, els antipatrons també
El 2026 és el primer any en què els agents IA s'han tornat infraestructura: no la cosa nova que provem, sinó la cosa que teníem i necessitem que segueixi funcionant. Aquest canvi d'estatus porta disciplines manllevades d'enginyeria clàssica — observabilitat, límits explícits, separació de responsabilitats, desacoblament del proveïdor — que el hype de 2024 havia deixat en segon pla.
Els vuit patrons i quatre antipatrons d'aquest article són el que, en la nostra experiència, separa un agent que sobreviu dotze mesos en producció d'un que s'ha de reconstruir als tres. Els antipatrons IA més cars no són les fallades tècniques sinó les decisions de disseny: donar autonomia sense supervisió, confiar en el context infinit, barrejar lectura i escriptura, o lligar-se a un únic proveïdor. El valor no és al model ni al prompt — és a la infraestructura que embolcalla el prompt i el fa correcte, auditable, barat i reemplaçable el dia 365.
Si estàs arrencant el teu primer agent, o ja en tens un i sospites que et costa mantenir-lo més del que t'ajuda, a Kiwop — Agència Digital especialitzada en Desenvolupament de Programari i Intel·ligència Artificial aplicada per a clients globals a Europa i els EUA — fem desenvolupament d'agents IA, consultoria IA, integració de LLMs i LLMOps com a peces coordinades d'un mateix procés.