Agentes IA em produção 2026: padrões e antipadrões após implementar em Nexo, PA e projetos de cliente
Pela equipa da Kiwop · Agência Digital especializada em Desenvolvimento de Software e Inteligência Artificial aplicada para clientes globais na Europa e EUA · Publicado a 19 de abril de 2026 · Última atualização: 19 de abril de 2026
TL;DR — Quinze meses a implementar agentes IA em Nexo, PA e clientes deixam-nos 8 padrões e 4 antipadrões IA. Regras chave: narrow scope ganha a generalista, confirmação humana antes de ações irreversíveis e nunca lock-in com um único LLM. Se já tens um agente em produção ou estás prestes a implementá-lo, aqui está o enquadramento completo.

O ano de 2026 é o primeiro em que os agentes IA deixam de ser demos de conferência e passam a ser infraestrutura que alguém tem de reiniciar às 3 da madrugada quando um step falha. Na Kiwop estamos desde janeiro de 2025 a construir agentes que vivem em produção: dentro do nosso SaaS próprio Nexo, como ferramentas internas da equipa, e em projetos de cliente.
Este artigo reúne as decisões de arquitetura que sobreviveram a esses quinze meses. Cada padrão vem de um incidente concreto, um custo que não queríamos voltar a pagar ou uma reclamação que nos obrigou a repensar. Cada antipadrão é algo que fizemos mal pelo menos uma vez. Se estás prestes a implementar o teu primeiro agente, ou se já tens um e a manutenção custa mais do que o desenvolvimento inicial, este é o guia que gostaríamos de ter tido quando começámos.
Contexto: onde implementámos agentes IA na Kiwop
Antes de entrar em padrões, um mapa de onde falam os dados. Os agentes IA em produção da Kiwop a abril de 2026 agrupam-se em três categorias.
Agentes em Nexo, o nosso SaaS multi-tenant (HR, CRM, projetos, faturação). Dentro de Nexo correm duas famílias: Brain protocols, um motor de workflows multi-step por cliente e workspace, e o extrator de contratos por IA que processa PDFs para automatizar a criação de contratos e hitos de faturação. Brain tem várias dezenas de protocolos ativos distribuídos entre workspaces de clientes; o extrator processa várias centenas de documentos mensais.
PA, o assistente pessoal interno. Detalhado em De OpenClaw a PA com Claude Code e MCP, liga correio IMAP, Gmail, Slack, Telegram e Google Calendar com uma sessão de Claude Code persistente. É usado diariamente por vários membros da equipa e processa no conjunto algo acima de 1.000 interações diárias.
Integrações de cliente. Agentes à medida: um agente de triagem de tickets para um cliente fintech, um agente de enriquecimento de leads para um cliente de e-commerce, e um agente de consulta de documentação legal para um cliente consultor. No conjunto rondam as 200-400 execuções diárias.
LLMs que usamos. Combinamos modelos da Anthropic (Haiku 4.5, Sonnet 4.5, Opus 4.7) para a maioria das cargas conversacionais e de raciocínio, e modelos da OpenAI (GPT-4o e GPT-4o-mini) para extração estruturada e workloads sensíveis ao custo. A escolha faz-se por feature e por workspace através de um AiGateway que veremos mais à frente.
Padrão 1: narrow scope ganha sempre a generalista
A primeira tentação é fazer um agente que "faça tudo" — lê correio, consulta calendário, atualiza CRM, responde a Slack, resume reuniões. Um único prompt enorme, um único agente. Em demo fica espetacular; em produção não sobrevive. Quando o agente cobre demasiado, o prompt enche-se de instruções contraditórias, o LLM perde precisão e quando algo falha é impossível saber em que subtarefa falhou. Pior: modificar a instrução de "como resumes um correio" pode alterar a de "como escreves uma mensagem de Slack".
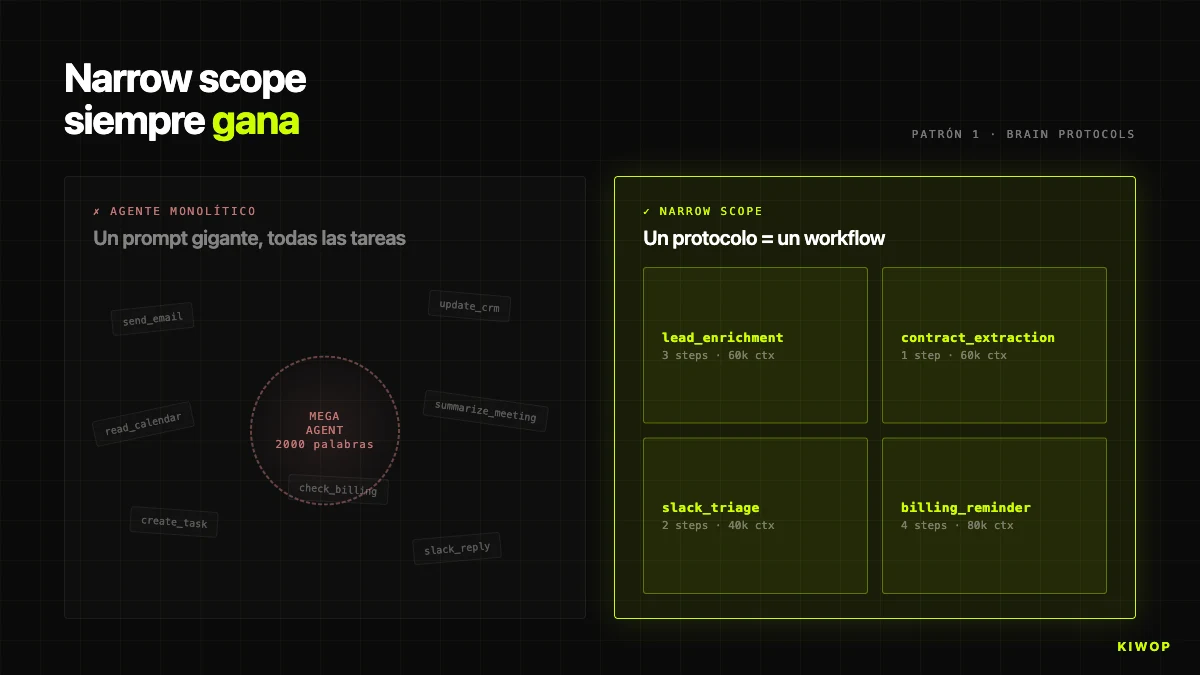
Em Brain, a regra é explícita: um protocolo = um workflow. Cada protocolo tem um propósito único — lead_enrichment, contract_extraction_followup, project_health_check, weekly_billing_reminder. Se emerge um caso de uso novo, cria-se um protocolo novo, não se amplia um existente. Quando um cliente pede "que enrichment também envie um Slack", a resposta correta é criar um segundo protocolo encadeado, não inflar o primeiro.
Isto nota-se no código do BrainProtocolEngine: cada protocolo tem os seus próprios steps, o seu trigger_config, o seu project_id e o seu workspace_id. Se enrichment falhar para um lead concreto, os restantes protocolos do mesmo workspace continuam a correr sem darem pela falha.
O antipadrão oposto — "o agente que faz tudo" — aparece com frequência em propostas de cliente: "um copilot para a equipa comercial que leia correio, consulte CRM, envie propostas, faça seguimento, avise de renovações". A nossa resposta padrão é desenhar esse pedido como cinco ou seis agentes independentes orquestrados com protocolos encadeados. A diferença no custo total de propriedade a doze meses é facilmente 3x ou 4x. Se o teu agente precisa de um prompt de sistema de 2.000 palavras para funcionar, quase de certeza tens vários agentes colados com fita adesiva. Separa-os.
Padrão 2: confirmação humana antes de ações irreversíveis
Os LLMs modernos erram aproximadamente 1% das vezes em tarefas fechadas que se consideram "fáceis". Não é um número medido por nós com rigor — é a ordem de grandeza de benchmarks públicos e corresponde à nossa experiência interna. Soa baixo até fazeres as contas.
Um agente que executa 1.000 operações por dia com 1% de erro produz 10 operações erradas diárias. Se são de leitura, o custo é zero. Se são de escrita (enviar um correio, criar um evento, modificar um registo, apagar algo), o custo pode ir desde um incómodo a um post mortem. Dez incidentes por dia são insustentáveis.
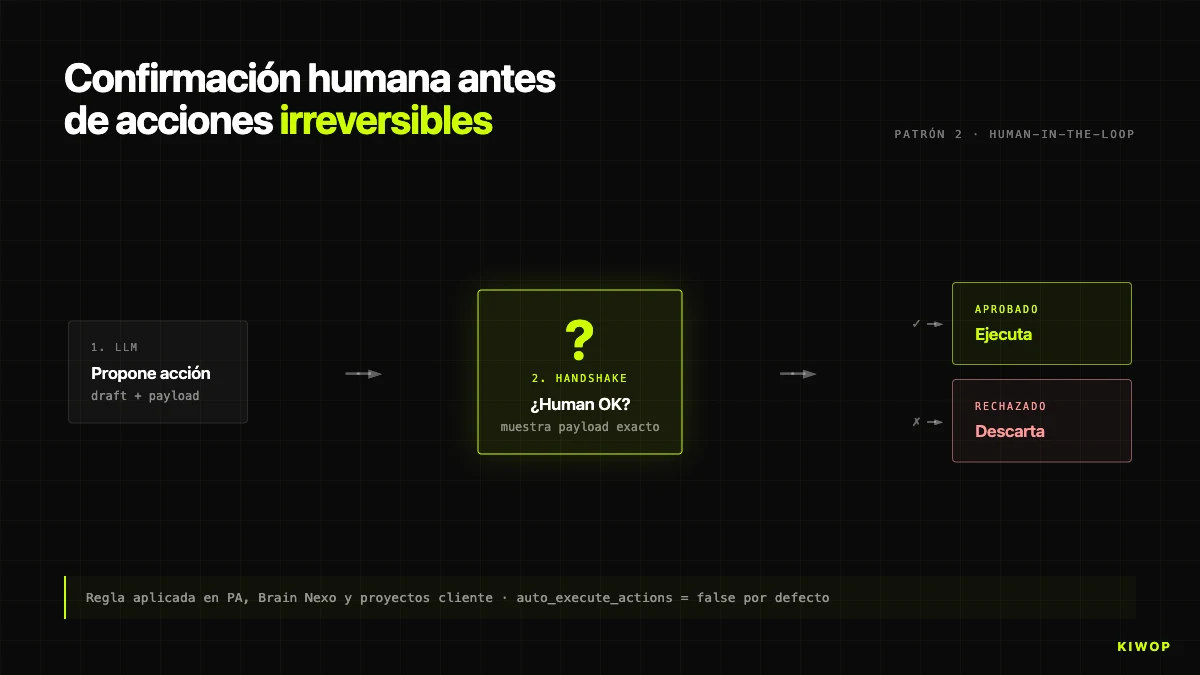
A regra sem exceções: o agente nunca executa ações irreversíveis sem confirmação humana explícita. Em PA, descrito no post do assistente pessoal, o agente pode ler a caixa inteira mas não envia sem que o humano escreva "sim". Em Brain, o equivalente é a flag auto_execute_actions em BrainProtocol: por defeito em false, quando um step gera uma action (criar tarefa, proposta, alerta), o que se cria é uma AgentProposal pendente de aprovação, não a ação final.
Apenas habilitamos auto_execute_actions = true quando se cumprem três condições: (1) a ação é idempotente e reversível, (2) após várias centenas de runs verificados manualmente, a taxa de erro observada mantém-se abaixo de 1%, ainda que a medição não seja metodologicamente rigorosa, e (3) o cliente assina a habilitação por escrito. A abril de 2026, menos de um quarto dos protocolos corre em modo autónomo.
Uma armadilha: a confirmação não deve ser "tens a certeza? [sim/não]" porque o utilizador habitua-se e faz clique sem ler. O handshake bem desenhado mostra exatamente o que vai acontecer (destinatário, assunto, corpo do correio; entidade DB a modificar; montante exato). Se o humano tem de saber o que confirma, lê o que confirma.
Este padrão liga com consultoria IA: a conversa começa por "que ações pode tomar o agente sem perguntar?" e quase sempre a resposta inicial fica aquém. Ampliar permissões é fácil, retirá-los após um incidente é caro.
Padrão 3: limites estritos de contexto e steps
Os agentes multi-step são gulosos. Cada step adiciona informação ao contexto, cada chamada pode devolver respostas longas, e sem um teto explícito o contexto cresce até que um de três problemas te bate: custo desproporcionado, alucinação por contexto inflado ou timeout do fornecedor.
Em BrainProtocolEngine temos duas constantes duras:
MAX_STEPS = 10 significa que um protocolo não pode executar mais de 10 steps por run, sem importar quantos tenha definidos. Protocolos com mais de 10 steps são quase sempre um desenho que teria sido melhor dividir em dois encadeados; o limite força essa conversa.
MAX_CONTEXT_CHARS = 300000 aplica-se ao contexto total acumulado. Se o JSON ultrapassa os 300.000 caracteres, regista-se um warning e o prompt é truncado com uma mensagem explícita ao modelo: "CONTEXTO TRUNCADO POR LIMITE DE TAMANHO". O limite é calibrado para caber confortavelmente numa janela de 200K tokens e afastar-se do 1M dos modelos com contexto estendido — porque, como veremos depois, contexto grande e contexto útil são coisas muito distintas.
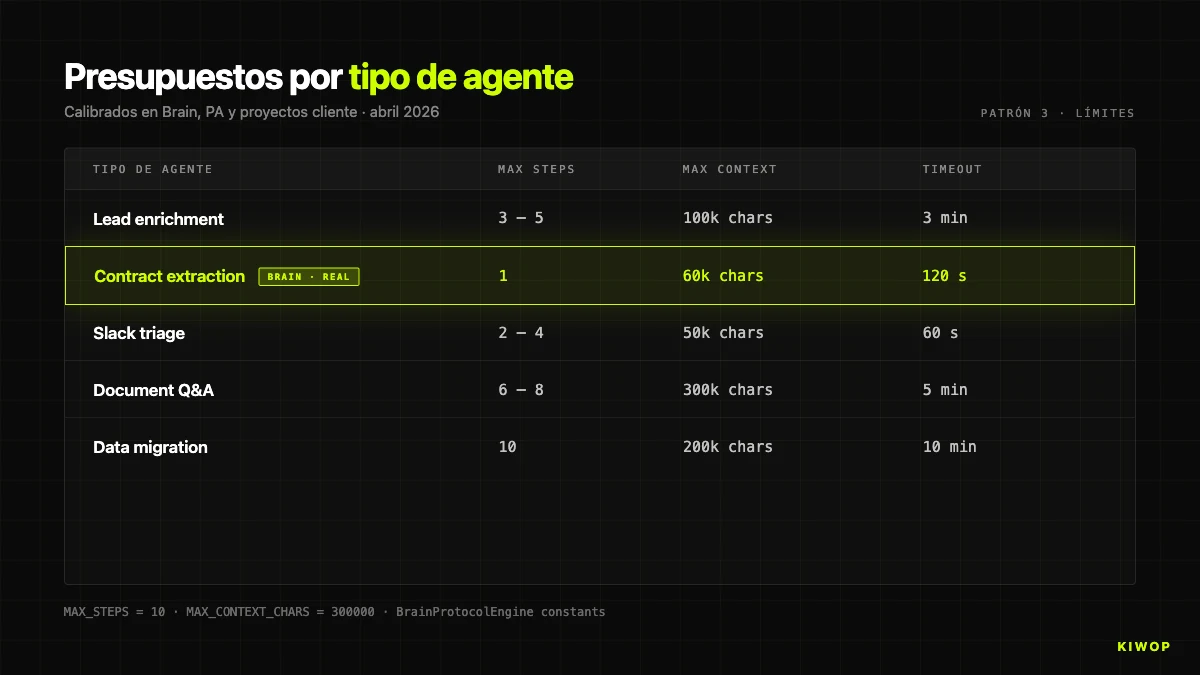
Como referência orientativa, estes são os orçamentos que usamos por defeito consoante o tipo de agente:
Estes valores não são universais — são os que passaram o teste de produção nos nossos workloads. Se estás a arrancar, começa conservador e sobe só quando tiveres dados que o justifiquem.
Padrão 4: MCP como linguagem comum antes que integrações ad hoc
Antes de 2025, cada integração entre um agente e um sistema externo era código à medida: um conector para Gmail, outro para Calendar, outro para Slack, cada um com a sua autenticação e manutenção. A maior parte do custo de construir um agente não vinha do prompt nem do modelo, vinha do glue code.
Model Context Protocol (MCP) mudou isso durante 2025 e consolidou a sua posição em 2026. MCP é um padrão aberto para que qualquer modelo fale com qualquer ferramenta usando uma mesma gramática de "tool calls". Publicado pela Anthropic em 2024, foi adotado por OpenAI, Google e pelos principais clientes de IA. Hoje, a maioria de integrações que construímos apoia-se em servidores MCP preexistentes em vez de escrever cliente novo.
O impacto no custo de desenvolvimento é brutal. Para um agente que precise de falar com Gmail, Calendar, Drive, Slack, Linear e GitHub, a diferença entre escrever seis conectores próprios com os seus OAuths e ligar seis servidores MCP existentes é da ordem de semanas face a horas. E a manutenção — quando um serviço muda um endpoint ou roda credenciais — deixa de ser problema teu.
Se não tens claro o que é MCP, WebMCP: o teu site preparado para agentes IA explica-o com exemplos concretos. Para a comparação com protocolos irmãos, MCP, WebMCP e A2A: os protocolos que definem os agentes IA em 2026 entra no detalhe.
Regra operativa: antes de escrever um conector próprio, verifica se existe um MCP oficial ou comunitário. Se existir e for mantido por uma equipa séria, usa-o. MCP não é panaceia — tem pontos cegos (IMAP corporativo, Telegram, CRMs verticais). Para esses buracos escrevemos scripts próprios, mas com a forma de um MCP para que, se amanhã alguém publicar um, a mudança seja indolor.
Padrão 5: anti-alucinação explícita no prompt
Os LLMs alucinam. É uma característica arquitetural do transformer, não um bug que vá desaparecer com o próximo modelo. Qualquer agente que trate dados reais tem de conviver com essa realidade.
A estratégia que melhor nos funcionou é inscrever as regras anti-alucinação diretamente no prompt de sistema, de forma literal e redundante. Não "por favor, sê preciso". Regras numeradas, em maiúsculas os termos críticos, com instruções operativas do que fazer perante a dúvida.
O exemplo mais claro em produção é o extrator de contratos do Nexo. O prompt de sistema do OpenAiContractExtractor arranca com estas instruções:
CRITICAL RULES: 1. NEVER invent or hallucinate data. If a field is not clearly stated, return null. 2. Return ONLY valid JSON. No explanations outside the JSON. 3. For each field, provide: - value: The extracted value (or null if not found) - confidence: A score from 0.0 to 1.0 indicating how confident you are - evidence: A brief quote from the document supporting your extraction (or null) 4. Dates MUST be in YYYY-MM-DD format. If day/month is unclear, return null.
Três mecanismos entram em jogo:
Permitir ao modelo dizer "não sei". Devolver null quando um dado não está claro é um resultado válido; inventá-lo, não. Muita gente escreve prompts sem saída explícita para "dado não disponível" e o modelo, forçado, preenche com o mais plausível que encontra.
Pedir confiança e evidência por campo. A confidence obriga o modelo a meta-raciocinar sobre a sua certeza. A evidence — citação literal do documento — é verificável: se a citação não aparecer, descarta-se o campo. O output passa a ser auditável em vez de caixa negra.
Formatos estruturados estritos. Datas em YYYY-MM-DD, números como tipos numéricos, enumerações fechadas ("fixed" | "hourly" | "monthly"). Quanto mais fechado é o formato, menos espaço para alucinação criativa.
Esta estratégia não elimina a alucinação mas reduz a níveis toleráveis com confirmação humana. Nos nossos dados internos, passar de prompts laxos a prompts com regras anti-alucinação literais reduziu os campos falsamente preenchidos em aproximadamente um fator de cinco, sem mudar o modelo.
Padrão 6: observabilidade obrigatória
A primeira vez que um cliente pergunta "porque é que o agente fez isso?" e não tens dados para responder, aprendes que a observabilidade não é opcional. Cada execução tem de deixar um rasto auditável: tokens, latência, steps executados, inputs, outputs, quem disparou e a partir de onde.
Em Brain, isto implementa-se com BrainProtocolRun. Cada execução cria um registo com:
status:running | completed | failed | cancelledstep_results: array com um objeto por step executado (nome, tipo, duração em ms, estado, resultado ou erro)context: o contexto acumulado, truncado a 50.000 caracteres para armazenamentocurrent_step: em que step ia quando se completou ou falhoutokens_used: tokens totais consumidos (soma input + output de todos osai_call)started_at/completed_attriggered_by_user_id/trigger_source: quem e a partir de que canal disparou o runerror: se falhou, a mensagem completa
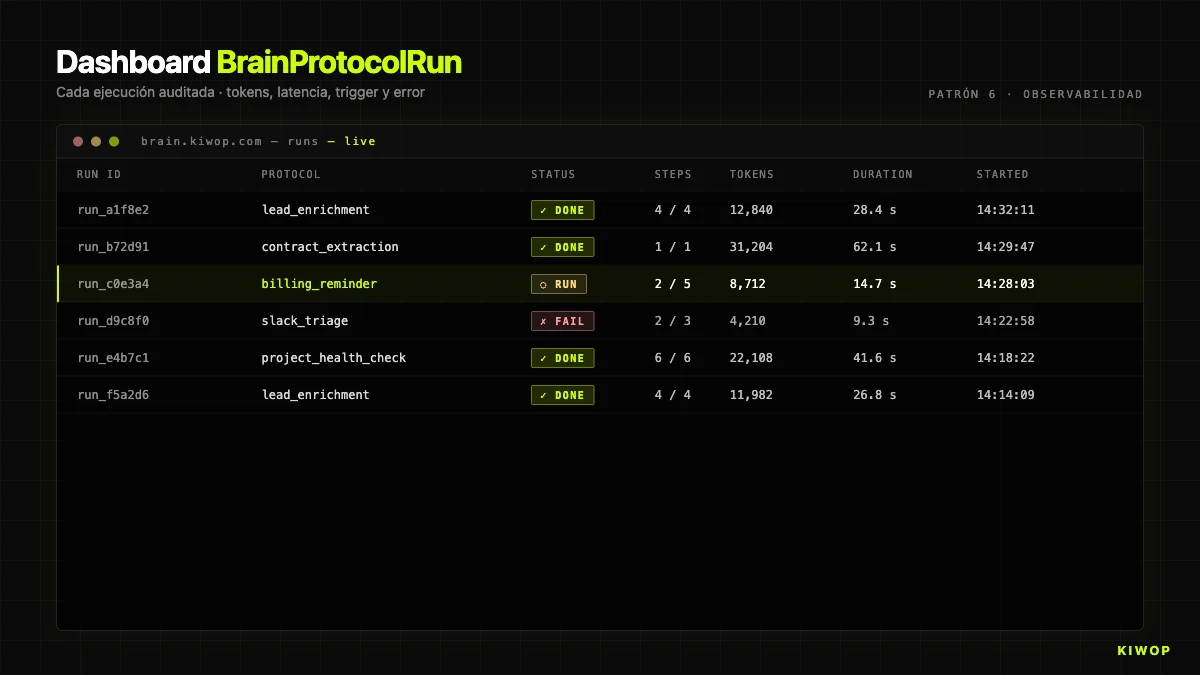
Essa estrutura responde às três perguntas que sempre se acabam a fazer: quanto custa? (soma de tokens_used × preço por token), porque falhou? (error + step_results até ao step que falhou), porque demorou tanto? (duration_ms por step).
Duas regras adicionais aprendidas pela via dolorosa:
Logs consultáveis a quente. Não servem ficheiros que ninguém olha. A DB aplicacional está bem para volume baixo-médio; para volume alto, um stack dedicado (Datadog, Grafana, Honeycomb) paga o custo antes do primeiro incidente grave.
Guarda sempre `trigger_source` e `triggered_by_user_id`. Quando algo corre mal, a primeira pergunta é forense: disparou-o o scheduler, um utilizador, uma integração externa, um webhook? Sem essa rastreabilidade, cada incidente é uma investigação arqueológica.
Este padrão está no coração da nossa oferta de LLMOps: gerir modelos em produção não é gerir os modelos — é gerir a telemetria, o custo, a qualidade e a segurança dos agentes que os usam.
Padrão 7: agentic timeouts com retry exponencial
Os LLMs externos falham — picos de procura, cortes de rede, sessões penduradas. Um agente que não lida com timeouts explícitos é um agente que fica pendurado, e um agente pendurado é pior do que um que falha: o humano não sabe o que se passa.
Três componentes na nossa política:
Timeouts explícitos por step. Em Brain cada ai_call define o seu max_tokens e timeout efetivo. Default do cliente: 120 segundos. Se um step o ultrapassa, o engine marca-o como failed em vez de deixar o run pendurado.
Retry exponencial com limite. Para erros transitórios (rate limit, 5xx, timeouts de rede) retentamos com backoff: delay = base * 2^attempt + jitter, base = 500ms, máximo 3 retentativas, tope 30 segundos. Absorve blips sem martelar o fornecedor.
Falha rápida em erros não recuperáveis. Os 4xx (input inválido, credenciais caducadas, quota esgotada) não se retentam — a próxima tentativa vai falhar na mesma. Se o step está marcado critical: true, aborta o protocolo inteiro.
Nota para agentes MCP: os servidores MCP também se penduram, e o cliente não propaga sempre bem o timeout. Em PA envolvemos algumas chamadas MCP com timeout ao nível de processo. A lição: não confies em timeouts de uma única camada, empilha várias.
Padrão 8: desenho agnóstico ao fornecedor de LLM
A 4 de abril de 2026 aprendemos em primeira mão o valor de ter a infraestrutura desacoplada do fornecedor. Nesse dia a Anthropic cortou os tokens OAuth que permitiam usar subscrições Claude Max e Pro com terceiros harnesses, e vários agentes do ecossistema ficaram sem backend. Contamos a história em De OpenClaw a PA com Claude Code e MCP e dedicamos um post específico à construção passo a passo do PA com Claude Code e MCP.
A infraestrutura do Nexo não se viu afetada porque estava desenhada para ser agnóstica ao fornecedor. O componente chave é o AiGateway, uma abstração que centraliza as chamadas a LLM e decide em runtime que cliente usar consoante a ligação do workspace e a feature.
Por detrás de chat(), AiGateway resolve uma WorkspaceAiConnection, constrói o cliente (AnthropicClient, OpenAiClient ou ClaudeCliClient para console-auth) e emite com o modelo correto. Mudar um workspace de Anthropic para OpenAI é uma mudança de configuração, não de código.
Três efeitos concretos:
Resiliência. Se a Anthropic tem uma incidência, rodamos para OpenAI em minutos sem tocar em código de protocolo. A 4 de abril não tivemos de o fazer porque o corte afetou OAuth de Claude Code, não a API que usa Nexo, mas a capacidade estava provada.
Escolha por feature. Chat usa Haiku 4.5 por custo; resumos de reunião usam Opus 4.7 por qualidade; extração de contratos usa GPT-4o pelo seu modo JSON estruturado. A abstração permite otimizar cada feature em separado.
Otimização por workspace. Workspaces pequenos sobre modelos baratos, workspaces premium sobre modelos premium. Decisão em workspaces_ai_connections, não em código.
A regra: nunca chames a API do fornecedor diretamente a partir do teu código de negócio. Passa sempre por uma camada intermédia própria. Quando o fornecedor mudar algo — e vai mudar — o impacto fica nessa camada.
Comparação de fornecedores LLM a abril de 2026
Esta tabela resume como vemos hoje os três grandes fornecedores tier-top da perspetiva de um agente em produção. Não é um ranking absoluto — é um guia de quando faz sentido apoiar-se em cada um dentro de uma arquitetura multi-fornecedor como a do padrão anterior.
Comparação a abril de 2026; modelos e preços evoluem rapidamente.
A seguir desmontamos quatro antipadrões IA de agentes que vimos descarrilar projetos — tanto nossos como de clientes — quando alguma das disciplinas anteriores não é aplicada.
Antipadrão 1: agente autónomo que atua sem supervisão
A narrativa do "agente autónomo que decide sozinho" soa bem em slides e acaba mal em incidentes. A razão não é filosófica, é estatística: qualquer processo estocástico (e os LLMs são-no) cometerá erros, e erros sem supervisão humana convertem-se em danos acumulados.
Modos típicos de falha:
Ciclo infinito. Um agente que "decide o que fazer a seguir" pode invocar a mesma tool 50 vezes seguidas. Sem um teto como MAX_STEPS = 10, a execução consome tokens sem valor.
Cascata de efeitos. Uma fatura errada dispara um webhook que envia correio ao cliente, que abre ticket no CRM, que notifica a equipa comercial. Desfazer a cadeia custa mais do que o erro original.
Corrupção de estado. Um agente com permissões de escrita que interprete mal uma instrução pode modificar registos impossíveis de reconstruir sem backup prévio.
Regra prática: nenhum agente deveria ter permissões de escrita irreversíveis sem human-in-the-loop no início. Habilitar modo autónomo para ações específicas é possível após centenas de runs verificados e taxa de erro abaixo do limiar do domínio. Nunca antes. Nunca por defeito.
Antipadrão 2: confiar no contexto "infinito" do modelo
Os modelos de 2026 ostentam janelas de 200K, 500K e até 1M tokens. A mensagem que passou é que "agora podes meter o que quiseres". Isso não é verdade em produção.
Três razões para não confiar na janela completa:
Degradação de qualidade com contexto inflado. Os benchmarks públicos e as nossas avaliações internas mostram que a precisão de recuperação (needle-in-a-haystack) degrada-se ao aproximar-se do limite. Um modelo que encontra um dado a 99% a 50K tokens pode descer a 80% ou menos a 500K tokens.
Custo proporcional ao input. Um contexto de 300K tokens custa seis vezes mais que um de 50K. Com 100 chamadas diárias, a diferença mensal entre "cabe tudo" e "apenas o necessário" conta-se em centenas ou milhares de euros.
Latência do first-token. Um prompt de 300K tokens pode demorar vários segundos a ser processado antes de o modelo começar a responder, mesmo com prompt caching. Para experiência conversacional, mata a perceção de rapidez.
Disciplina: o contexto deve ser o mínimo necessário, não o máximo possível. Em Brain, os data_filter existem precisamente para reduzir o contexto entre steps: um connector_fetch pode trazer 500 correios; o filtro reduz aos 20 que cumprem critérios; o ai_call posterior só vê esses 20. O padrão RAG nasce da mesma disciplina — para bases documentais grandes, RAG empresarial é a arquitetura correta, não um contexto gigante.
Antipadrão 3: sem separação de leitura e escrita
Os agentes que leem e escrevem no mesmo step são bomba-relógio. Se a chamada falha a meio, não sabes se a escrita foi executada. Se se retenta, podes duplicar. Se houver erro de interpretação, não tens snapshot do estado que o agente viu.
Regra: separa leitura e escrita em passos distintos com materialização explícita entre ambos. Em Brain, a tipologia de steps reflete-o: connector_fetch e db_query são read-only; action é a única que escreve. Um protocolo bem desenhado tem forma "N steps de leitura, 0 ou 1 de escrita no final". Se precisas de escrever mais de uma vez, partes o protocolo em dois.
Em integrações de cliente aplicamos o mesmo padrão: o agente gera uma proposta (objeto em DB com o rascunho ou a mudança), e um segundo passo — com confirmação humana — executa a ação. Permite auditoria, retry seguro, rollback e human-in-the-loop sem redesenhar o fluxo. Exceção legítima: operações idempotentes com chave natural. Para o resto, separa.
Antipadrão 4: um único fornecedor de LLM crítico
Já o tocámos no padrão 8, mas merece sublinhar-se: um agente crítico que depende de um único fornecedor é um agente frágil. Não porque o fornecedor seja mau, mas porque qualquer decisão unilateral — mudança de preço, política, sunset de modelo, queda do serviço, corte de OAuth — pode deixar-te sem backend.
A 4 de abril de 2026 a Anthropic cortou OAuth de Claude Max para terceiros. A OpenAI ajusta preços de API periodicamente. A Google muda quotas de Gemini. Não são movimentos maliciosos — são decisões de negócio — mas todos têm o mesmo efeito sobre quem construiu assumindo que nada iria mudar.
Três camadas mínimas de desacoplamento:
Abstração própria tipo AiGateway. O teu código fala com a tua abstração, não com o SDK do fornecedor.
Credenciais e config em DB. Mudar de modelo ou fornecedor não deveria requerer deploy, mas um UPDATE.
Prompts portáveis. Se o teu prompt só funciona com um modelo específico, tens um prompt frágil. Os prompts bem escritos (regras explícitas, formato estruturado) funcionam aceitavelmente nos modelos tier-top dos três grandes. Se as diferenças são grandes, o problema está no prompt, não no modelo.
Com estas três camadas, quando o fornecedor A muda algo o teu custo de migração é de horas, não semanas.
Como aplicamos estes padrões nos serviços da Kiwop

Estes oito padrões e quatro antipadrões são o enquadramento com o qual entregamos projetos de IA na Kiwop. Quando um cliente chega com "quero um agente para X", a conversa segue esta ordem:
Primeiro, consultoria IA para delimitar o scope real. Quase sempre o que o cliente pede são três ou quatro agentes atados ao mesmo; o trabalho consultivo é separá-los e decidir o que é autónomo e o que requer handshake humano.
Segundo, desenvolvimento de agentes IA com arquitetura que aplica os padrões 3 a 8 por defeito: limites, MCPs, anti-alucinação, observabilidade, timeouts, abstração do fornecedor.
Terceiro, integração de LLMs sobre MCP quando existe e sobre conectores próprios quando não existe.
Quarto, uma vez em produção, LLMOps para gerir ciclo de vida: observabilidade, custos por workspace, rotação de modelos, resposta perante incidentes.
O objetivo: que o agente que entregamos ao dia 1 continue a funcionar ao dia 365 com custo previsível.
Perguntas frequentes
Quando faz sentido construir um agente IA em produção?
Quando há uma tarefa repetitiva semi-estruturada, com critérios claros de sucesso e que permite tolerar uma pequena percentagem de erros graças a confirmação humana. Exemplos: triagem de correio ou tickets, enriquecimento de leads, extração de documentos, resumo de reuniões, classificação de mensagens. Não faz sentido para tarefas com custo de erro muito alto sem supervisão, nem para tarefas resolúveis com uma regra determinista sem LLM.
Que modelo de LLM escolher para um agente em 2026?
Depende da feature. Para chat e multi-step com prioridade em custo, Haiku 4.5 ou GPT-4o-mini. Para raciocínio complexo e extração de qualidade, Sonnet 4.5, Opus 4.7 ou GPT-4o. Para JSON estrito, GPT-4o pelo seu modo nativo. Começa com o modelo mais barato que passa as tuas avaliações próprias e sobe de tier apenas quando os dados o justifiquem.
Quanto custa implementar um agente IA em produção?
Desenvolvimento entre 6.000 e 15.000 euros para um agente narrow scope com MCPs existentes (sobe com integrações à medida). Custo operativo: um agente de cerca de 500 interações diárias sobre Haiku 4.5 pode mover-se em 50-150 euros mensais em tokens; sobre Opus 4.7 a fatura pode multiplicar-se por 10 ou mais. Desenha para custo baixo e sobe apenas onde acrescente valor visível.
É seguro um agente IA que toca em dados de clientes?
Pode sê-lo: (1) dados sensíveis revistos antes do prompt; (2) ações irreversíveis com confirmação humana; (3) cada run auditado com rastreabilidade. Para conteúdo regulado (sanitário, legal, financeiro com segredo profissional), valoriza modelos on-premise ou regionais com acordos específicos de não treinamento. Um projeto de RAG empresarial com infraestrutura controlada costuma ser a opção correta.
Como evito que o meu agente alucine dados?
Várias camadas: (1) prompt com regras anti-alucinação literais ("se não tens o dado, devolve null"); (2) confiança e evidência por campo para output auditável; (3) formatos estruturados com enum fechados; (4) validação determinista antes de sistemas críticos; (5) confirmação humana em operações irreversíveis. Nenhuma isolada basta; as cinco juntas reduzem a alucinação a níveis toleráveis.
O que é um Brain protocol em Nexo?
Um workflow declarativo com steps tipados (connector_fetch, data_filter, ai_call, db_query, action, condition) executados sequencialmente com contexto mutável. Ao contrário de um agente "todo-o-terreno" que decide que tool chamar, um protocolo é determinista na sequência mas flexível dentro de cada step. Limites duros (MAX_STEPS = 10, MAX_CONTEXT_CHARS = 300000) e cada run auditado em BrainProtocolRun com tokens, latência por step, trigger source e resultado.
O que faço se o meu fornecedor de LLM muda preços ou fecha uma modalidade de acesso?
Se estás desacoplado (padrão 8), rodar é configuração: verifica que os prompts funcionam com o modelo novo e reavalia custo. Se não o estavas, primeiro introduz a camada de abstração, separa credenciais em config e testa os prompts em pelo menos dois fornecedores. O trabalho amortiza muito rapidamente na primeira vez que evita um incidente.
Posso começar com um agente autónomo e acrescentar confirmação depois?
Ao contrário: começa com confirmação humana em todas as ações irreversíveis e habilita autónomo apenas quando tiveres dados de taxa de erro baixa. Acrescentar confirmação após um incidente é mais caro do que retirá-la quando o agente demonstra solvência, sobretudo em domínios sensíveis (dinheiro, correios a clientes, CRM).
Conclusão: os padrões escalam, os antipadrões também
2026 é o primeiro ano em que os agentes IA se tornaram infraestrutura: não a coisa nova que experimentamos, mas a coisa que tínhamos e precisamos que continue a funcionar. Essa mudança de estatuto traz disciplinas emprestadas da engenharia clássica — observabilidade, limites explícitos, separação de responsabilidades, desacoplamento do fornecedor — que o hype de 2024 tinha deixado em segundo plano.
Os oito padrões e quatro antipadrões deste artigo são o que, na nossa experiência, separa um agente que sobrevive doze meses em produção de um que há que reconstruir ao fim de três. Os antipadrões IA mais caros não são as falhas técnicas mas as decisões de desenho: dar autonomia sem supervisão, confiar no contexto infinito, misturar leitura e escrita, ou atar-se a um único fornecedor. O valor não está no modelo nem no prompt — está na infraestrutura que envolve o prompt e o torna correto, auditável, barato e substituível ao dia 365.
Se estás a arrancar com o teu primeiro agente, ou já tens um e suspeitas que te custa mantê-lo mais do que te ajuda, na Kiwop — Agência Digital especializada em Desenvolvimento de Software e Inteligência Artificial aplicada para clientes globais na Europa e EUA — fazemos desenvolvimento de agentes IA, consultoria IA, integração de LLMs e LLMOps como peças coordenadas de um mesmo processo.