By the Kiwop team · Digital Agency specialized in Software Development and Applied Artificial Intelligence · Published May 7, 2026 · Last updated: May 7, 2026
TL;DR — RAG is the answer when the LLM needs dynamic knowledge that wasn't in its training: internal databases, updated documents, catalogs. Fine-tuning is the answer when you need to persistently change the model's behavior, style or reasoning domain, and you have the dataset to justify it. MCP is the answer when the agent needs to act, not just remember: execute, read, write, call APIs. Combining two or all three is common and, in many cases, the right architecture. Choosing only one without evaluating the others is the most expensive antipattern we see in production.

Every week we get the same question from technical teams designing their first LLM applications in production: "Should we set up RAG or is fine-tuning the better choice?". And the honest answer is that the question is almost always framed wrong. RAG, fine-tuning and MCP are not alternatives on the same dimension: they solve different problems at different layers of the stack.
The confusion is understandable. All three techniques get presented together in tutorials, papers and provider pitch decks as if they were interchangeable approaches for "making the LLM know more things". They're not. A team that does fine-tuning when they need RAG wastes weeks and tens of thousands of euros. A team that sets up RAG when they need MCP builds a sophisticated information retrieval system that ultimately can't execute anything.
This post is the decision framework that would have saved us several architecture cycles two years ago. It's based on our real experience deploying AI agents in production, building the Nexo SaaS, and setting up the PA personal assistant on MCP with Claude Code. This isn't theory: it's what we learn when something breaks in production and we need to diagnose why.
Why a Standalone LLM Is Never Enough
A language model in its pure form has four structural limitations that no increase in parameter count fully resolves.
Knowledge frozen in time. Training data has a cutoff date. GPT-4o's cutoff is April 2024. Claude 3.5 Sonnet's is April 2024. Everything that happened after that doesn't exist for the model, except what you put in the context. If your application needs data from today, last week, or yesterday's updated catalog, the model alone cannot help you.
Knowledge that was never there. Models are trained on publicly available internet data. Your internal documentation, contracts, support tickets, corporate knowledge base: none of that is in the base model. And it shouldn't be, for privacy reasons as much as security.
Structural hallucinations. When the model doesn't know something, it doesn't always say so. Sometimes it makes things up with the same confidence it uses when saying something true. The problem isn't ignorance; it's false confidence in ignorance. The only real solution is giving the model access to the source of truth at inference time.
No capacity for action. The model generates text. It cannot read your database, write to your CRM, or send an email. For an LLM to act in the world it needs external tools. That's a different infrastructure layer from knowledge.
These four limitations generate three families of solutions: RAG for the first two, fine-tuning for certain cases of the second (reasoning domain), and MCP for the fourth. Each addresses a different dimension of the problem.
The Three Strategies for Connecting an LLM to Your World
Before going into detail, a short definition of each that we'll expand on:
RAG (Retrieval-Augmented Generation): the model receives, at inference time, document fragments retrieved from a vector database or search engine. It doesn't change the model; it changes what the model sees.
Fine-tuning: the model is retrained on domain-specific data, adjusting its weights. It doesn't change what the model sees at each inference; it changes what the model is.
MCP (Model Context Protocol): the agent has access to typed tools — APIs, databases, external systems — that it can invoke during generation. It's not just knowledge; it's the capacity for action.
The fundamental distinction: RAG is declarative memory, fine-tuning is procedural learning, MCP is agency. All three are orthogonal. They can be combined without one replacing another.
RAG — Retrieval-Augmented Generation
What It Is and How It Works
RAG was formalized in the paper by Lewis et al. (Facebook AI Research, 2020) and became the dominant pattern for connecting LLMs with proprietary knowledge bases. The idea is deceptively simple: when a user question comes in, before calling the model, you retrieve the most relevant fragments from your corpus, insert them into the prompt as context, and the model generates the response grounded in those sources.
The modern implementation has three components:
- Ingestion pipeline: documents are processed, split into chunks (typically 512–1024 tokens with overlap), encoded into embeddings, and stored in a vector database (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval: at inference time, the user's question is converted into an embedding and a similarity search (cosine or dot product) is performed to retrieve the top-K most relevant chunks.
- Augmentation: the retrieved chunks are inserted into the system prompt along with the question, and the model generates the response.
More sophisticated variants add re-ranking (a second model orders retrieval results by actual relevance, not just vector similarity), HyDE (Hypothetical Document Embeddings, which generates a hypothetical document before searching), and hybrid RAG (vector search + lexical BM25 combined). According to the RAG survey on arxiv by Gao et al. (2024), re-ranking is the single factor that most improves response quality in enterprise RAG.
Optimal Use Cases
RAG excels in exactly these situations:
- Enterprise knowledge base: internal documentation, technical manuals, HR procedures, company policies. The corpus updates frequently; you can't retrain the model every week.
- Customer support with your own product: the assistant needs to answer about your specific product, not generic market products.
- Ad-hoc document analysis: the user uploads contracts, reports, or PDFs and asks questions. Content varies each session.
- Compliance and auditing: the answer must be traceable to a specific fragment of a source document — citation, article, clause. RAG is the only pattern that does this structurally.
- High-frequency update data: product catalogs, prices, inventory availability. Anything that changes faster than you'd update a model.
At Kiwop we implement RAG as the foundation of our enterprise RAG system for clients in legal, real estate and fintech sectors, where traceability to source documents is not optional.
When NOT to Use RAG
RAG is not the solution when the problem is behavior, not knowledge. If the base model produces responses in the wrong format, in an inappropriate language register, or with a reasoning style that doesn't fit your domain — that's not fixed with more context. A better prompt might help; RAG won't.
It's also not the solution when latency is critical. A typical RAG pipeline adds 200–600ms to total latency: the time to embed the query, vector retrieval, and prompt expansion. For high-frequency interfaces with expectations of immediate response, that overhead may be unacceptable.
And it's not the solution when the corpus is too small. If your documents comfortably fit within the context window (say, fewer than 50 A4 pages), the simplest pattern is to put the entire document in the context directly. You can save months of data engineering work.
Real Costs: Vector DB, Infrastructure, Latency
A functional enterprise RAG has three costs that tutorials rarely quantify.
Vector database: Pinecone Starter (free up to 2GB) is enough for prototypes. A typical enterprise corpus (50K documents with 1536-dimensional embeddings) comes to around 500MB–2GB of vectors — the limit is reached sooner than expected. Pinecone Standard starts at $70/month. Weaviate Cloud at its production tier is comparable. If you use pgvector on your existing PostgreSQL the storage cost is marginal, but scaling concurrent queries requires more management.
Embedding at ingestion: a corpus of 100K chunks with OpenAI's text-embedding-3-small ($0.02/1M tokens) costs less than $5 the first time. The real cost is reprocessing when you switch embedding models — something inevitable as better models emerge — and the ingestion pipeline infrastructure (worker, queue, deduplication, versioning).
Operational latency: in production, including re-ranking, expect 400–800ms of added overhead. If your LLM already takes 1–2s to respond, the total can approach 3s — above the "slow response" perception threshold for conversational interfaces.
Fine-Tuning — Training the Model on Your Domain
What It Is (LoRA, QLoRA, Full Fine-Tune)
Fine-tuning is adjusting the weights of a pre-trained model on a specific dataset, so the model internalizes patterns, formats, or knowledge that are insufficiently represented in its base training.
There are three main variants by cost and capability:
Full fine-tuning: all model weights are updated. Maximum adaptation capacity, highest cost. For 7B parameter models it requires GPUs with 80GB VRAM (two A100s minimum). For 70B models we're talking about clusters of 8+ GPUs. In practice, it only makes sense with reference instances for very specific domains or with proprietary models where the provider manages compute (OpenAI fine-tuning API, Google Vertex AI Tuning).
LoRA (Low-Rank Adaptation): instead of updating all weights, low-rank matrices are added that learn the delta. Hugging Face's PEFT library implements LoRA as the standard; according to the official PEFT documentation, LoRA can reduce the number of trainable parameters by more than 10,000x while maintaining quality comparable to full fine-tuning on many tasks. A 7B model with LoRA trains on a 24GB VRAM A10 GPU.
QLoRA: LoRA over a 4-bit quantized model. Allows training 70B models on a single 80GB A100 GPU, at the cost of some quality compared to full-precision LoRA. It's the reference variant for experimenting with large models without cluster access.
The OpenAI fine-tuning documentation covers the full process for their models (GPT-4o mini, GPT-4o). Fine-tuning GPT-4o mini costs $3/1M tokens in training and $0.30/1M tokens in inference (30% more than the base model). Anthropic doesn't offer public fine-tuning of their models; Google offers tuning on Gemini Pro via Vertex AI.
Optimal Use Cases
Fine-tuning solves exactly these problems:
- Strict and complex output format: if the model must produce JSON with a very specific schema, code in the company's style, or documents with a fixed structure, fine-tuning locks in that pattern better than any prompt instruction.
- Very specific language register and tone: assistants that must sound exactly like the company's brand voice, with proprietary vocabulary, sector-specific courtesy forms, or very narrow technical terminology.
- Reasoning in a very specialized domain: medicine, law, specific industrial process engineering. The base model has general domain knowledge; fine-tuning sharpens it on the specifics of the proprietary domain.
- Reduced latency via short prompts: a fine-tuned model can behave as if it has a long system prompt without needing that prompt on every call — the weights already internalize the instructions. This reduces input tokens and therefore cost and latency.
- Repetitive classification and extraction: if you have a very well-defined task (classify emails by category, extract entities from invoices, normalize addresses) with thousands of labeled examples, fine-tuning outperforms RAG and prompt engineering in precision and consistency.
When NOT to Fine-Tune
This is the part that most projects ignore.
Don't fine-tune to add factual knowledge that changes over time. The model learns knowledge as static weights; when that knowledge expires, you have to retrain. RAG resolves the problem structurally better.
Don't fine-tune to resolve knowledge hallucinations. If the model hallucinates because it doesn't know something, giving it more examples of that knowledge in fine-tuning can reduce hallucination in cases seen during training, but it doesn't eliminate it structurally — and may increase it in unseen cases. The correct solution is RAG with source grounding.
Don't fine-tune without a quality dataset. The real minimum to see improvement is between 100 and 1,000 high-quality examples, annotated in the correct format. "We have 50 examples" is almost never enough. And the examples must cover the real distribution of cases, not just happy paths.
Don't fine-tune as a first experiment. Before fine-tuning, exhaust advanced prompt engineering (few-shot examples, chain-of-thought, detailed system prompts). In most cases, a well-crafted prompt delivers 80–90% of the result with 0% of the fine-tuning cost.
Real Costs (Compute, Dataset, Maintenance)
Costs have three dimensions that few people calculate together.
Training cost: fine-tuning GPT-4o mini with 1,000 examples of 500 tokens = approx. $1–3. Fine-tuning GPT-4o with the same dataset = approx. $30–90. LoRA on a 7B open-source model on an A10G on AWS = $2–8/hour, a typical run of 2–6 hours = $10–50. LoRA on a 70B on an A100 cluster = $20–80/hour. These are first-run costs; experimentation (testing hyperparameters, reviewing errors, retraining) easily multiplies by 3–5x.
Dataset cost: human annotation of quality examples is the biggest hidden cost. If you need 1,000 medical classification examples with specialist labeling, the annotation cost can exceed the compute cost by 10x. For many projects, the dataset is the real bottleneck, not training.
Maintenance cost: a fine-tuned model ages. The domain changes, edge cases emerge, the base model updates (and the fine-tuning doesn't migrate automatically). Each base model update cycle potentially means repeating the fine-tuning. This turns fine-tuning into a long-term ML engineering commitment, not a one-off project.
MCP — Tools and Action
Quick Recap
MCP (Model Context Protocol) is the open standard — published by Anthropic in November 2024 and donated to the Linux Foundation in December 2025 — for connecting LLM agents to external tools. We covered its full architecture, including the comparison with WebMCP and A2A, in the post MCP, WebMCP and A2A: Which Protocol to Choose for Your AI Agents.
The basic architecture: an MCP client (the agent or its host) connects to one or more MCP servers, discovers their tools via a JSON-RPC handshake, and invokes them with typed parameters during generation. The tools can do anything an API can do: read and write to databases, call external APIs, execute code, send emails, modify files.
With more than 10,000 public MCP servers and 97 million monthly SDK downloads, MCP is today the de facto standard for agent tools.
When to Use MCP Instead of RAG
The right question isn't "MCP or RAG" but "is the problem one of knowledge or of action?".
Use MCP when the answer requires reading real-time data: if the user asks "how many units of product X are left in the warehouse?" the answer is in your ERP right now, not in a document indexed three days ago. RAG with an updated corpus could work, but MCP is more direct: the agent calls the get_inventory(product_id="X") tool and gets the exact answer without indexing latency.
Use MCP when the answer requires writing or action: creating a ticket, sending a notification, updating a record, approving a workflow. This is never RAG territory — RAG only reads.
Use MCP when the source of truth already has an API: if your system already has a well-defined API, building an MCP server on top of it is frequently simpler than setting up an ingestion + embedding + vector store pipeline.
Use MCP when data is structured and relational: queries involving joins, aggregations or complex filters on relational data live better in SQL via an MCP server than in semantic search over text chunks.
In our architecture for the LLM integration service, the pattern we recommend by default is MCP for transactional data access + RAG for documentation and unstructured knowledge. The two coexist without conflict.
Limitations
MCP adds tool invocation latency (one HTTP or stdin/stdout round-trip per tool). In agents that chain many tools, wait time accumulates. And the observability of an agent with tools is substantially more complex than a simple LLM call: you need tool call tracing, parameter and result logging, and error handling for each tool. We cover these patterns in detail in AI agents in production: patterns and antipatterns.
MCP also doesn't change the model's reasoning capabilities. If the base model reasons poorly in your domain, giving it tools doesn't fix that. Tools amplify what the model already knows how to do; they don't correct what it does poorly.
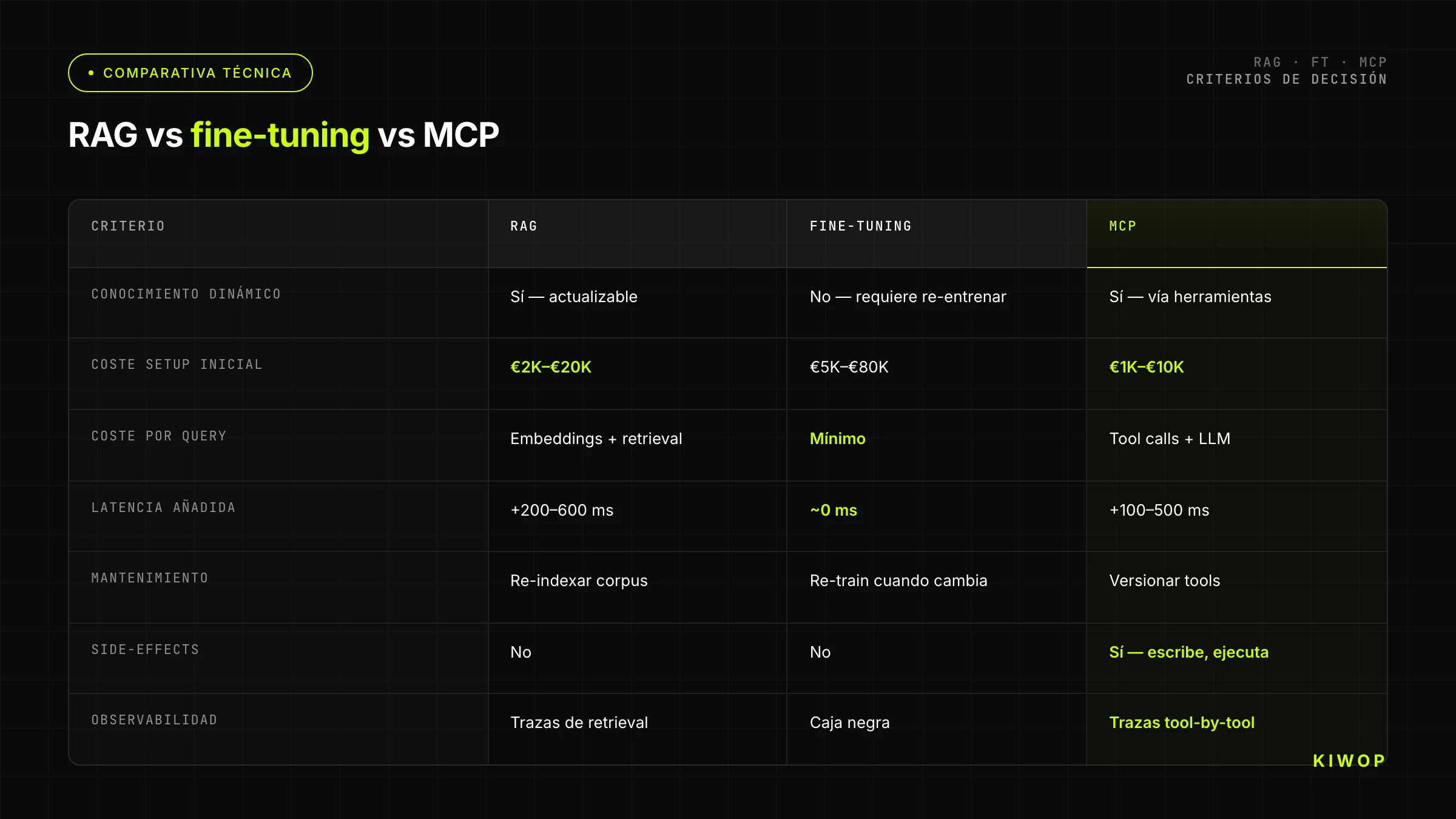
Comparison Table: RAG vs Fine-Tuning vs MCP
Decision Tree: What to Use?
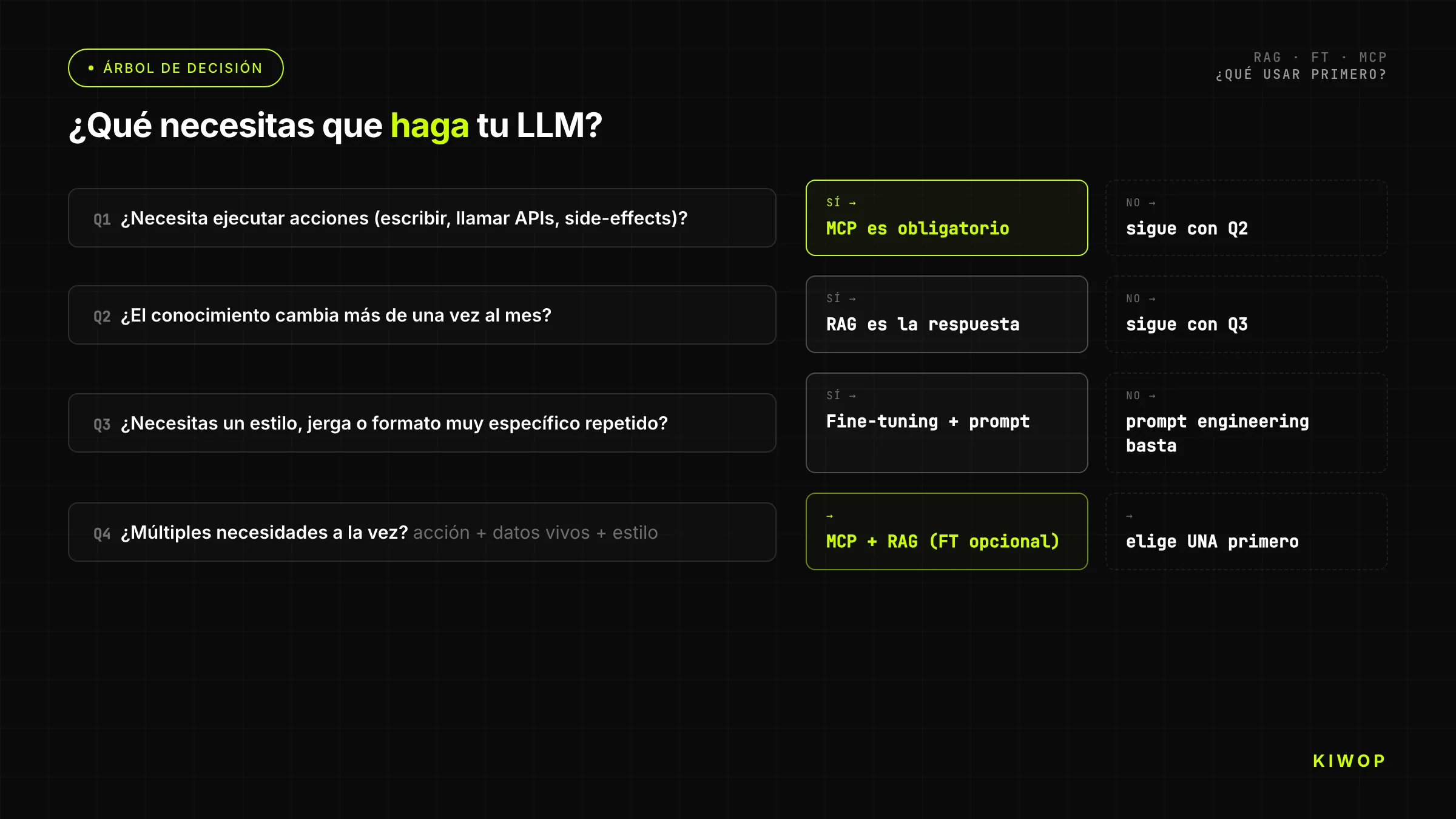
The simplified tree for teams that need a quick answer:
Question 1: Does the agent need to execute actions on external systems (read real-time APIs, write data, invoke processes)?
- Yes → you need MCP. Do you also need knowledge from documents? Add RAG. Continue through the tree for other dimensions.
- No → continue.
Question 2: Does the LLM need to answer about documents, data or knowledge that wasn't in its training or changes frequently?
- Yes → RAG is the first answer. Does the corpus have more than 200 pages? Confirm that RAG scales for your case. Does the corpus fit in the context window? Consider inserting context directly without RAG.
- No → continue.
Question 3: Does the base model produce responses in the wrong format/tone/style for your use case, and do you have more than 500 correctly annotated examples?
- Yes → fine-tuning is an option. Have you exhausted advanced prompt engineering? If not, start there.
- No → go back and evaluate whether the problem is really about model behavior or knowledge.
Question 4: Do you have the resources and time to maintain the fine-tuned model throughout the base model's lifecycle?
- Yes → fine-tuning.
- No → advanced prompt engineering + RAG for knowledge; accept the behavioral limitations.
Most enterprise LLM applications in production end up with RAG + MCP as the base architecture. Fine-tuning adds complexity and cost that rarely justifies the incremental benefit over well-executed prompt engineering.
Real Cases at Kiwop
Nexo (Multi-Tenant SaaS): MCP + Selective RAG
Nexo is the SaaS workspace we're building at Kiwop. The full architecture is documented in the post about multi-tenant SaaS architecture with Laravel and Inertia.
The Nexo agent has two distinct layers of information access:
MCP layer — for transactional operations: creating tasks, updating project statuses, reading tenant workspace metrics, sending notifications. All of this lives in the tenant's relational database and has a well-defined internal API. Building an MCP server per tenant lets the agent operate on real-time data without indexing latency.
Selective RAG layer — for documentation and unstructured notes: meeting minutes, product specifications, technical documentation that teams upload to the workspace. This corpus varies widely between tenants and has no fixed structure — that's exactly RAG territory. We use Qdrant as the vector store with per-tenant partitioning to guarantee data isolation.
Fine-tuning: we haven't done any for Nexo. The base model with a well-crafted system prompt covers the expected behavior. The maintenance cost of a fine-tuned model for a SaaS that evolves weekly would be prohibitive.
PA (Personal Assistant): Pure MCP
The PA personal assistant we built with Claude Code, documented in detail in the post build your PA with Claude Code and MCP, uses only MCP stdio.
The PA needs to read and write Gmail, Calendar, Drive and Slack. All the information lives in well-defined APIs with mature SDKs — exactly the optimal use case for MCP. There's no proprietary document corpus to index (email is read directly), no behavior to change (the base model is sufficiently capable), and latency is tolerable because operations are asynchronous.
RAG would add an unnecessary layer of complexity. Fine-tuning doesn't solve any real problem we have. Pure MCP is the simplest architecture that works — and that's what we use.
When We Combine All Three
The only case where we combine RAG, MCP and fine-tuning simultaneously is in assistant projects for very specific sectors — legal and medical, primarily — where all three needs are real:
- MCP to access the client's internal systems (case files, hearing calendars, proprietary jurisprudence databases).
- RAG on legal or clinical documentation (regulations, protocols, anonymized case histories).
- Fine-tuning to adapt the response format to the sector's exact terminology and the client's internal communication style.
Even in those cases, fine-tuning is always the last thing we implement, after exhausting RAG + prompt engineering. And the fine-tuned model's maintenance cycle is explicitly planned and budgeted from the start.
5 Antipatterns We See in Production
1. Fine-Tuning When RAG Was Enough
This is the most frequent and most expensive antipattern. The team decides to fine-tune because "we want the model to know our products" — but the product catalog changes monthly. After weeks of annotation and training, the fine-tuned model has outdated information from day one. The correct solution from the start was RAG with an automatically updated corpus.
The warning signal: if you're asking yourself "does the model need to know X?" and X is anything that changes faster than your retraining cycle, the answer is RAG, not fine-tuning.
2. RAG Without Re-Ranking
A RAG pipeline without re-ranking retrieves the top-K most vectorially similar chunks — but vector similarity is not the same as actual relevance to the specific question. The model receives partially relevant context, mixes correct information with noise, and response quality is mediocre.
Re-ranking with a cross-encoder (models like bge-reranker-v2-m3 or Cohere Rerank) adds 50–150ms of latency but can improve response precision by 20–40% depending on the corpus. It's one of the best-ROI investments in a mature RAG pipeline. Yet most implementations we see in production don't have it.
3. MCP Without Sandboxing
An agent with MCP can execute irreversible actions: delete records, send mass emails, execute transactions. Without an explicit confirmation layer for destructive operations, an agent that misinterprets an instruction can cause real harm.
The correct pattern: distinguish between read-only tools (which the agent can invoke freely) and write or destructive tools (which require explicit human confirmation before executing). MCP doesn't impose this by protocol — it's the agent architecture's responsibility. We cover this in AI agents in production: patterns and antipatterns.
4. Combining Everything "Just in Case"
The most dangerous architecture we see is one that combines RAG + fine-tuning + MCP from day one without use cases that justify each layer. The result is a system that's hard to debug (is the error coming from the retrieval, the fine-tuned weights, or the tool call?), expensive to maintain, and with multiple independent failure points.
The engineering principle is always the same: start with the simplest architecture that solves the problem. Add complexity only when there's a specific problem that justifies it. A RAG application with a good corpus and good re-ranking frequently outperforms a poorly designed RAG+FT+MCP architecture on every KPI that matters.
5. Ignoring the Cost of Maintaining the Corpus
A RAG system in production is not "I index the documents once and that's it." The corpus ages: documents update, new ones are added, some become obsolete. If you don't have an index update process — ideally automated — the retrieval starts returning outdated context and system quality silently degrades.
The corpus maintenance pipeline (change detection, partial re-indexing, retrieval quality validation) is as important as the initial ingestion pipeline. Budget for it from day one, or the system works well in the demo and poorly in production six months later.
Frequently Asked Questions
Does RAG replace fine-tuning?
Not as a general rule, but RAG replaces fine-tuning in 80% of cases where teams think they need fine-tuning. If the goal is for the model to "know more things," RAG is almost always the correct and more maintainable answer. Fine-tuning wins when the goal is for the model to "behave differently" — different format, tone, or reasoning — and when you have the dataset and maintenance cycle to sustain it.
How much does it cost to set up enterprise RAG?
A functional RAG for a corpus of 10,000 documents with an ingestion pipeline, vector store in Pinecone or Qdrant, re-ranking, and a basic frontend costs between $2,000 and $8,000 in initial development (2–6 weeks of engineering). The monthly operational cost in infrastructure (vector DB + embedding API calls + LLM calls) is usually between $200 and $2,000/month depending on query volume. The corpus maintenance cost depends on how frequently it updates and whether the process is manual or automated.
Can I use RAG and MCP at the same time?
Yes, and it's the pattern we recommend for most enterprise agents. The agent has MCP tools to access transactional data in real time and a RAG retriever to answer questions about documents and unstructured knowledge. The two are invoked at different moments in the reasoning process and don't interfere with each other. In fact, an MCP server can expose the RAG retriever as a tool, making the pattern especially clean.
OpenAI or Anthropic for fine-tuning?
Anthropic doesn't offer fine-tuning of their models to external clients today. The commercial options are OpenAI (GPT-4o mini and GPT-4o), Google Vertex AI (Gemini Pro) and, for open-source models, providers like Together AI, Replicate, or own infrastructure. OpenAI has the most mature and documented fine-tuning platform on the market. Google is competitive for use cases in the GCP ecosystem. For most new projects, if the candidate base model is from Anthropic, the alternative to unavailable fine-tuning is to build more solid RAG or use prompt caching to reduce costs on long prompts.
Which vector database should I choose?
It depends on context. If you already use PostgreSQL, pgvector is the entry point with the least operational friction. If you need to scale to millions of vectors with submillisecond latencies, Pinecone has the best time-to-production. Weaviate is strong when the corpus is very large and you need hybrid search (vector + keyword) with multiple tenants. Qdrant is open-source, fast, and the best option if you want full control without a cloud license. For most enterprise cases we handle via enterprise RAG, we start with pgvector on the client's existing PostgreSQL and migrate to Qdrant when volume justifies it.
Conclusion and Next Steps
The question isn't "RAG, fine-tuning or MCP?" — it's "what dimension of the problem am I solving?". Dynamic knowledge: RAG. Model behavior: fine-tuning, but with criteria and a maintenance plan. Action on systems: MCP.
Most LLM applications in production need RAG + MCP as their base. Fine-tuning is the third level that's added only when RAG + well-crafted prompt engineering isn't enough, and when the team has the real capacity to sustain the model's lifecycle.
The most expensive trap is choosing without criteria and then discovering six months later that the architecture doesn't hold. We've seen projects spend two months doing fine-tuning when RAG would have taken two weeks and worked better. We've seen RAG pipelines without re-ranking that were completely redesigned after the system reached production and quality wasn't acceptable.
If your team is in this decision process — evaluating whether you need RAG, fine-tuning, MCP, or some combination — that's exactly the work we do at Kiwop. We review the architecture, the use case, the available resources, and design the minimum system that solves the problem with the lowest maintenance cost. Our services for AI agent development, enterprise RAG and LLM integration are designed for teams that want to reach production with solid technical decisions, without paying the price of learning everything from scratch. Write to us and we'll evaluate it together.
If you found this post useful, follow the thread with the full cluster: MCP, WebMCP and A2A: Which Protocol to Choose for Your AI Agents, AI agents in production: patterns and antipatterns and build your PA with Claude Code and MCP.


