Por el equipo de Kiwop · Agencia Digital especializada en Desarrollo de Software e Inteligencia Artificial aplicada · Publicado el 7 de mayo de 2026 · Última actualización: 7 de mayo de 2026
TL;DR — RAG es la respuesta cuando el LLM necesita conocimiento dinámico que no estuvo en su entrenamiento: bases de datos internas, documentos actualizados, catálogos. Fine-tuning es la respuesta cuando necesitas cambiar el comportamiento, el estilo o el dominio de razonamiento del modelo de forma persistente, y tienes el dataset para justificarlo. MCP es la respuesta cuando el agente necesita actuar, no solo recordar: ejecutar, leer, escribir, llamar APIs. Combinar dos o los tres es frecuente y, en muchos casos, la arquitectura correcta. Elegir solo uno sin evaluar los demás es el antipatrón más caro que vemos en producción.

Cada semana recibimos la misma pregunta desde equipos técnicos que están diseñando sus primeras aplicaciones LLM en producción: "¿Montamos RAG o mejor hacemos fine-tuning?". Y la respuesta honesta es que la pregunta está mal planteada casi siempre. RAG, fine-tuning y MCP no son alternativas en la misma dimensión: resuelven problemas distintos en capas distintas del stack.
La confusión es comprensible. Los tres técnicas se presentan juntas en tutoriales, en papers y en pitch decks de proveedores como si fueran enfoques intercambiables para "hacer que el LLM sepa más cosas". No lo son. Un equipo que hace fine-tuning cuando necesita RAG desperdicia semanas y decenas de miles de euros. Un equipo que monta RAG cuando necesita MCP construye un sistema de recuperación de información sofisticado que al final no puede ejecutar nada.
Este post es el framework de decisión que nos hubiera ahorrado varios ciclos de arquitectura hace dos años. Está basado en nuestra experiencia real desplegando agentes IA en producción, construyendo el SaaS Nexo, y montando el asistente personal PA sobre MCP con Claude Code. No es teoría: es lo que aprendemos cuando algo falla en producción y tenemos que diagnosticar por qué.
Por qué un LLM solo nunca es suficiente
Un modelo de lenguaje en estado puro tiene cuatro limitaciones estructurales que ningún aumento de parámetros resuelve completamente.
Conocimiento congelado en el tiempo. El training data tiene una fecha de corte. GPT-4o tiene corte en abril de 2024. Claude 3.5 Sonnet en abril de 2024. Todo lo que pasó después no existe para el modelo, excepto lo que le pongas en el contexto. Si tu aplicación necesita datos de hoy, la semana pasada, o el catálogo actualizado de ayer, el modelo solo no puede ayudarte.
Conocimiento que nunca estuvo ahí. Los modelos se entrenan con datos públicos de internet. Tu documentación interna, tus contratos, tus tickets de soporte, tu base de conocimiento corporativa: nada de eso está en el modelo base. Y no debería estarlo, por razones de privacidad tanto como de seguridad.
Alucinaciones estructurales. Cuando el modelo no sabe algo, no lo dice siempre. A veces lo inventa con la misma confianza con que dice algo verdadero. El problema no es la ignorancia; es la confianza falsa en la ignorancia. La única solución real es darle al modelo acceso a la fuente de verdad en el momento de la inferencia.
Sin capacidad de acción. El modelo genera texto. No puede leer tu base de datos, no puede escribir en tu CRM, no puede enviar un email. Para que un LLM actúe en el mundo necesita herramientas externas. Eso es una capa de infraestructura diferente al conocimiento.
Estas cuatro limitaciones generan tres familias de soluciones: RAG para las dos primeras, fine-tuning para ciertos casos de la segunda (dominio de razonamiento), y MCP para la cuarta. Cada una toca una dimensión distinta del problema.
Las tres estrategias para conectar un LLM con tu mundo
Antes de entrar en detalle, una definición corta de cada una que luego expandiremos:
RAG (Retrieval-Augmented Generation): el modelo recibe, en el momento de la inferencia, fragmentos de documentos recuperados de una base de datos vectorial o un motor de búsqueda. No cambia el modelo; cambia lo que el modelo ve.
Fine-tuning: el modelo se reentrena sobre datos específicos del dominio, ajustando sus pesos. No cambia lo que el modelo ve en cada inferencia; cambia lo que el modelo es.
MCP (Model Context Protocol): el agente tiene acceso a herramientas tipadas — APIs, bases de datos, sistemas externos — que puede invocar durante la generación. No es solo conocimiento; es capacidad de acción.
La distinción fundamental: RAG es memoria declarativa, fine-tuning es aprendizaje procedural, MCP es agencia. Los tres son ortogonales. Se pueden combinar sin que uno sustituya al otro.
RAG — Retrieval-Augmented Generation
Qué es y cómo funciona
RAG fue formalizado en el paper de Lewis et al. (Facebook AI Research, 2020) y se convirtió en el patrón dominante para conectar LLMs con bases de conocimiento propietarias. La idea es deceptivamente simple: cuando llega una pregunta del usuario, antes de llamar al modelo, recuperas los fragmentos más relevantes de tu corpus, los insertas en el prompt como contexto, y el modelo genera la respuesta grounding-ado en esas fuentes.
La implementación moderna tiene tres componentes:
- Ingestion pipeline: documentos se procesan, se trocean en chunks (típicamente 512-1024 tokens con solapamiento), se encodean en embeddings, y se almacenan en una base de datos vectorial (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval: en inferencia, la pregunta del usuario se convierte en embedding y se hace búsqueda por similitud (coseno o producto punto) para recuperar los top-K chunks más relevantes.
- Augmentation: los chunks recuperados se insertan en el prompt del sistema junto con la pregunta, y el modelo genera la respuesta.
Las variantes más sofisticadas añaden re-ranking (un segundo modelo ordena los resultados del retrieval por relevancia real, no solo similitud vectorial), HyDE (Hypothetical Document Embeddings, que genera un documento hipotético antes de buscar), y RAG híbrido (búsqueda vectorial + BM25 léxico combinados). Según la encuesta sobre RAG de arxiv de Gao et al. (2024), el re-ranking es el factor individual que más mejora la calidad de respuesta en RAG empresarial.
Casos de uso óptimos
RAG brilla en exactamente estas situaciones:
- Knowledge base empresarial: documentación interna, manuales técnicos, procedimientos de RRHH, políticas de empresa. El corpus se actualiza con frecuencia; no puedes re-entrenar el modelo cada semana.
- Soporte al cliente con producto propio: el asistente necesita responder sobre tu producto específico, no sobre productos genéricos del mercado.
- Análisis de documentos ad-hoc: el usuario sube contratos, informes, o PDFs y hace preguntas. El contenido varía en cada sesión.
- Compliance y auditoría: la respuesta debe poder trazarse a un fragmento concreto de un documento fuente — cita, artículo, cláusula. RAG es el único patrón que lo hace estructuralmente.
- Datos con alta frecuencia de actualización: catálogos de producto, precios, disponibilidad de inventario. Cualquier cosa que cambia más rápido de lo que actualizarías un modelo.
En Kiwop implementamos RAG como base del sistema de RAG empresarial para clientes en sectores legal, inmobiliario y fintech, donde la trazabilidad a documento fuente no es opcional.
Cuándo NO usar RAG
RAG no es la solución cuando el problema no es de conocimiento sino de comportamiento. Si el modelo base produce respuestas en un formato incorrecto, en un registro de idioma inapropiado, o con un estilo de razonamiento que no encaja con tu dominio — eso no se arregla con más contexto. Un prompt mejor quizás sí; RAG, no.
Tampoco es la solución cuando la latencia es crítica. Un pipeline RAG típico añade 200-600ms a la latencia total: el tiempo de embedding de la query, el retrieval vectorial, y la ampliación del prompt. Para interfaces de alta frecuencia con expectativa de respuesta inmediata, ese overhead puede ser inaceptable.
Y no es la solución cuando el corpus es demasiado pequeño. Si tus documentos caben holgadamente en la ventana de contexto (digamos, menos de 50 páginas A4), el pattern más simple es meter todo el documento en el contexto directamente. Puedes ahorrar meses de trabajo de ingeniería de datos.
Costes reales: vector DB, infra, latencia
Un RAG empresarial funcional tiene tres costes que los tutoriales raramente cuantifican.
Vector database: Pinecone Starter (gratis hasta 2GB) es suficiente para prototipos. Un corpus empresarial medio (50K documentos con embeddings de 1536 dimensiones) ronda los 500MB-2GB vectoriales — el límite se alcanza antes de lo esperado. Pinecone Standard arranca en $70/mes. Weaviate Cloud en su tier de producción es comparable. Si usas pgvector en tu PostgreSQL existente el coste de almacenamiento es marginal, pero la escalabilidad de queries concurrentes requiere más gestión.
Embedding en ingestion: un corpus de 100K chunks con text-embedding-3-small de OpenAI ($0.02/1M tokens) cuesta menos de $5 la primera vez. El coste real es el reprocesado cuando cambias el modelo de embeddings — algo inevitable cuando emergen mejores modelos — y la infraestructura del pipeline de ingestion (worker, queue, deduplicación, versionado).
Latencia operativa: en producción, con re-ranking incluido, espera 400-800ms de overhead añadido. Si tu LLM ya tarda 1-2s en responder, el total puede rozar los 3s — por encima del umbral de percepción de "respuesta lenta" para interfaces conversacionales.
Fine-tuning — entrenar el modelo en tu dominio
Qué es (LoRA, QLoRA, full fine-tune)
Fine-tuning es ajustar los pesos de un modelo preentrenado sobre un dataset específico, de forma que el modelo internalice patrones, formatos, o conocimientos que no están suficientemente representados en su entrenamiento base.
Hay tres variantes principales según coste y capacidad:
Full fine-tuning: todos los pesos del modelo se actualizan. Máxima capacidad de adaptación, coste más alto. Para modelos de 7B parámetros requiere GPUs con 80GB VRAM (dos A100 mínimo). Para modelos de 70B ya estamos hablando de clusters de 8+ GPUs. En la práctica, solo tiene sentido con instancias de referencia para dominio muy específico o con modelos propietarios donde el proveedor gestiona el computo (OpenAI fine-tuning API, Google Vertex AI Tuning).
LoRA (Low-Rank Adaptation): en lugar de actualizar todos los pesos, se añaden matrices de bajo rango que aprenden el delta. La librería PEFT de Hugging Face implementa LoRA como estándar; según la documentación oficial de PEFT, LoRA puede reducir el número de parámetros entrenables en más de 10.000x manteniendo una calidad comparable al full fine-tuning en muchas tareas. Un modelo de 7B con LoRA entrena en una GPU A10 de 24GB VRAM.
QLoRA: LoRA sobre modelo cuantizado a 4-bit. Permite entrenar modelos de 70B en una sola GPU A100 de 80GB, a costa de algo de calidad respecto a LoRA full-precision. Es la variante de referencia para experimentación con modelos grandes sin acceso a clúster.
La documentación de fine-tuning de OpenAI cubre el proceso completo para sus modelos (GPT-4o mini, GPT-4o). El fine-tuning de GPT-4o mini tiene un coste de $3/1M tokens en entrenamiento y $0.30/1M tokens en inferencia (un 30% superior al modelo base). Anthropic no ofrece fine-tuning público de sus modelos; Google ofrece tuning sobre Gemini Pro vía Vertex AI.
Casos de uso óptimos
Fine-tuning resuelve exactamente estos problemas:
- Formato de salida estricto y complejo: si el modelo debe producir JSON con un schema muy específico, código en un estilo de la empresa, o documentos con estructura fija, el fine-tuning fija ese patrón mejor que cualquier instrucción en el prompt.
- Registro de idioma y tono muy específico: asistentes que deben sonar exactamente como la voz de marca de la empresa, con vocabulario propio, formas de cortesía específicas del sector, o terminología técnica muy cerrada.
- Razonamiento en dominio muy especializado: medicina, derecho, ingeniería específica de proceso industrial. El modelo base tiene conocimiento general del dominio; el fine-tuning lo afila en las particularidades del dominio propio.
- Latencia reducida vía prompts cortos: un modelo fine-tuneado puede comportarse como si tuviera un system prompt largo sin necesitar ese prompt en cada llamada — los pesos ya internalizan las instrucciones. Esto reduce tokens de entrada y, por tanto, coste y latencia.
- Clasificación y extracción repetitiva: si tienes un task muy definido (clasificar emails por categoría, extraer entidades de facturas, normalizar direcciones) con miles de ejemplos anotados, fine-tuning supera a RAG y a prompt engineering en precisión y consistencia.
Cuándo NO fine-tunear
Esta es la parte que más proyectos ignoran.
No fine-tunees para añadir conocimiento factual que cambia con el tiempo. El modelo aprende el conocimiento como pesos estáticos; cuando ese conocimiento caduca, tienes que re-entrenar. RAG resuelve el problema estructuralmente mejor.
No fine-tunees para resolver alucinaciones de conocimiento. Si el modelo alucina porque no sabe algo, darle más ejemplos de ese conocimiento en fine-tuning puede reducir la alucinación en los casos vistos durante entrenamiento, pero no la elimina estructuralmente — y puede aumentarla en casos no vistos. La solución correcta es RAG con grounding en fuente.
No fine-tunees sin dataset de calidad. El mínimo real para ver mejora es entre 100 y 1.000 ejemplos de alta calidad, anotados con el formato correcto. "Tenemos 50 ejemplos" casi nunca es suficiente. Y los ejemplos deben cubrir la distribución real de casos, no solo los casos felices.
No fine-tunees como primer experimento. Antes de fine-tuning, agota el prompt engineering avanzado (few-shot examples, chain-of-thought, system prompts detallados). En la mayoría de casos, un prompt bien construido da el 80-90% del resultado con el 0% del coste de fine-tuning.
Costes reales (compute, dataset, mantenimiento)
Los costes tienen tres dimensiones que pocas personas calculan conjuntamente.
Coste de entrenamiento: fine-tuning de GPT-4o mini con 1.000 ejemplos de 500 tokens = aprox. $1-3. Fine-tuning de GPT-4o con el mismo dataset = aprox. $30-90. LoRA sobre un modelo 7B open-source en un A10G en AWS = $2-8/hora, una corrida típica de 2-6 horas = $10-50. LoRA sobre un 70B en clúster de A100 = $20-80/hora. Estos son costes de primera corrida; la experimentación (probar hiperparámetros, revisar errores, re-entrenar) multiplica fácilmente por 3-5x.
Coste de dataset: la anotación humana de ejemplos de calidad es el coste oculto más grande. Si necesitas 1.000 ejemplos de clasificación médica con etiquetado de especialista, el coste de anotación puede superar en 10x el coste de compute. Para muchos proyectos, el dataset es el cuello de botella real, no el entrenamiento.
Coste de mantenimiento: un modelo fine-tuneado envejece. El dominio cambia, los casos extremos emergen, el modelo base se actualiza (y el fine-tuning no migra automáticamente). Cada ciclo de actualización del modelo base implica potencialmente repetir el fine-tuning. Esto convierte el fine-tuning en un compromiso a largo plazo de ingeniería de ML, no un proyecto puntual.
MCP — herramientas y acción
Recap rápido
MCP (Model Context Protocol) es el estándar abierto — publicado por Anthropic en noviembre de 2024 y donado a la Linux Foundation en diciembre de 2025 — para conectar agentes LLM con herramientas externas. Cubrimos su arquitectura completa, incluyendo la comparativa con WebMCP y A2A, en el post MCP, WebMCP y A2A: qué protocolo elegir para tus agentes IA.
La arquitectura básica: un cliente MCP (el agente o su host) se conecta a uno o varios servidores MCP, descubre sus tools mediante un handshake JSON-RPC, y las invoca con parámetros tipados durante la generación. Las tools pueden hacer cualquier cosa que una API puede hacer: leer y escribir en bases de datos, llamar a APIs externas, ejecutar código, enviar emails, modificar ficheros.
Con más de 10.000 servidores MCP públicos y 97 millones de descargas mensuales de SDK, MCP es hoy el estándar de facto para herramientas de agentes.
Cuándo usar MCP en lugar de RAG
La pregunta correcta no es "MCP o RAG" sino "¿el problema es de conocimiento o de acción?".
Usa MCP cuando la respuesta requiere leer datos en tiempo real: si el usuario pregunta "¿cuántas unidades quedan en almacén del producto X?" la respuesta está en tu ERP ahora mismo, no en un documento indexado hace tres días. RAG con corpus actualizado podría funcionar, pero MCP es más directo: el agente llama a la tool get_inventory(product_id="X") y obtiene la respuesta exacta sin latencia de indexación.
Usa MCP cuando la respuesta requiere escritura o acción: crear un ticket, enviar una notificación, actualizar un registro, aprobar un workflow. Esto nunca es RAG territory — RAG solo lee.
Usa MCP cuando la fuente de verdad ya tiene API: si tu sistema ya tiene una API bien definida, construir un servidor MCP encima es frecuentemente más sencillo que montar un pipeline de ingestion + embedding + vector store.
Usa MCP cuando los datos son estructurados y relacionales: consultas que implican joins, agregaciones o filtros complejos sobre datos relacionales viven mejor en SQL vía un servidor MCP que en búsqueda semántica sobre chunks de texto.
En nuestra arquitectura para el servicio de integración de LLMs, el patrón que recomendamos por defecto es MCP para acceso a datos transaccionales + RAG para documentación y conocimiento no estructurado. Los dos conviven sin conflicto.
Limitaciones
MCP añade latencia de tool invocation (un round-trip HTTP o stdin/stdout por herramienta). En agentes que encadenan muchas tools, el tiempo de espera se acumula. Y la observabilidad de un agente con tools es sustancialmente más compleja que la de un simple LLM call: necesitas tracing de tool calls, logging de parámetros y resultados, y gestión de errores en cada herramienta. Cubrimos estos patrones en detalle en agentes IA en producción: patrones y antipatrones.
MCP tampoco cambia las capacidades de razonamiento del modelo. Si el modelo base razona mal en tu dominio, darle tools no lo corrige. Las tools amplifican lo que el modelo ya sabe hacer; no corrigen lo que hace mal.
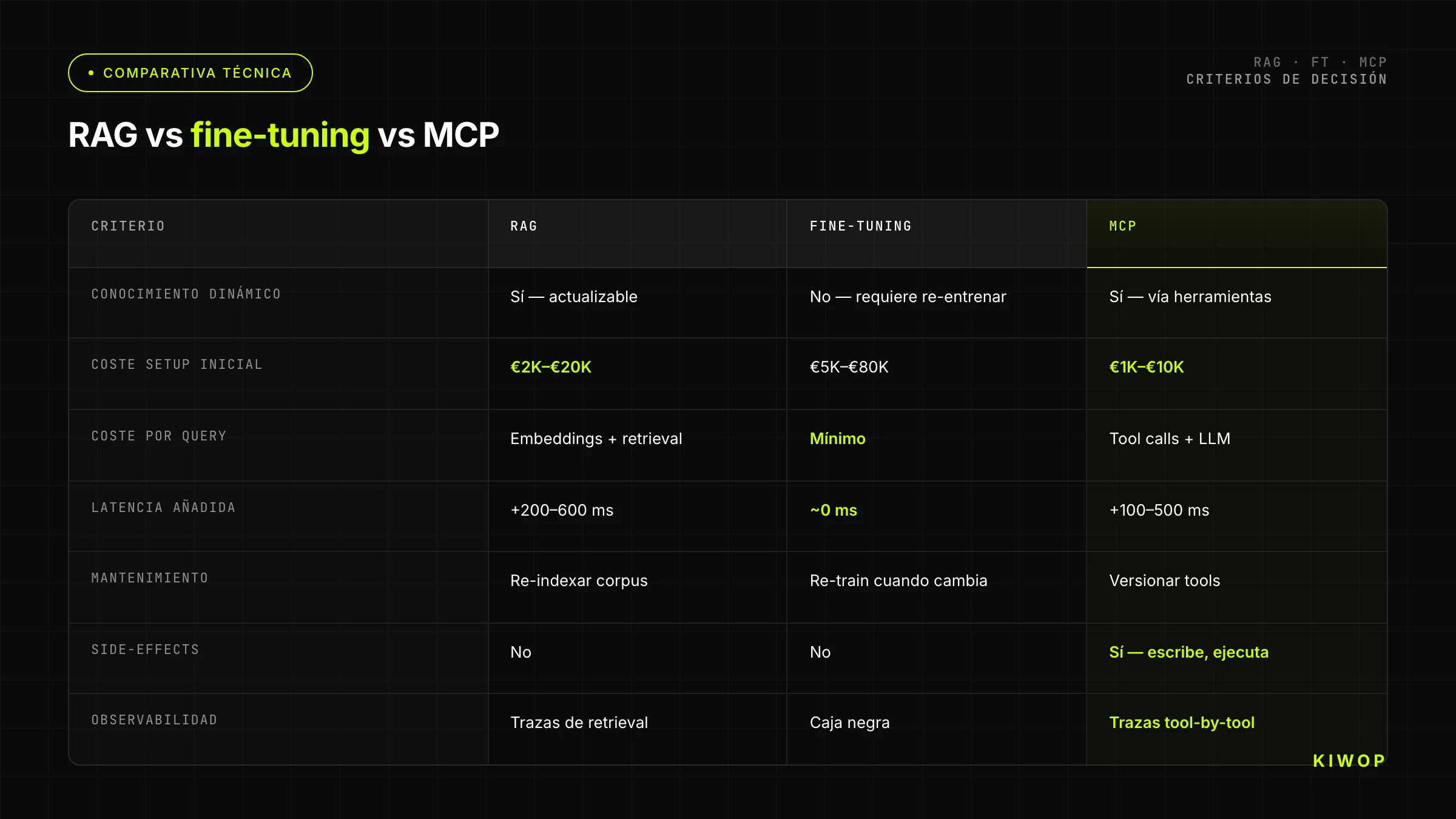
Tabla comparativa: RAG vs fine-tuning vs MCP
Árbol de decisión: ¿qué usar?
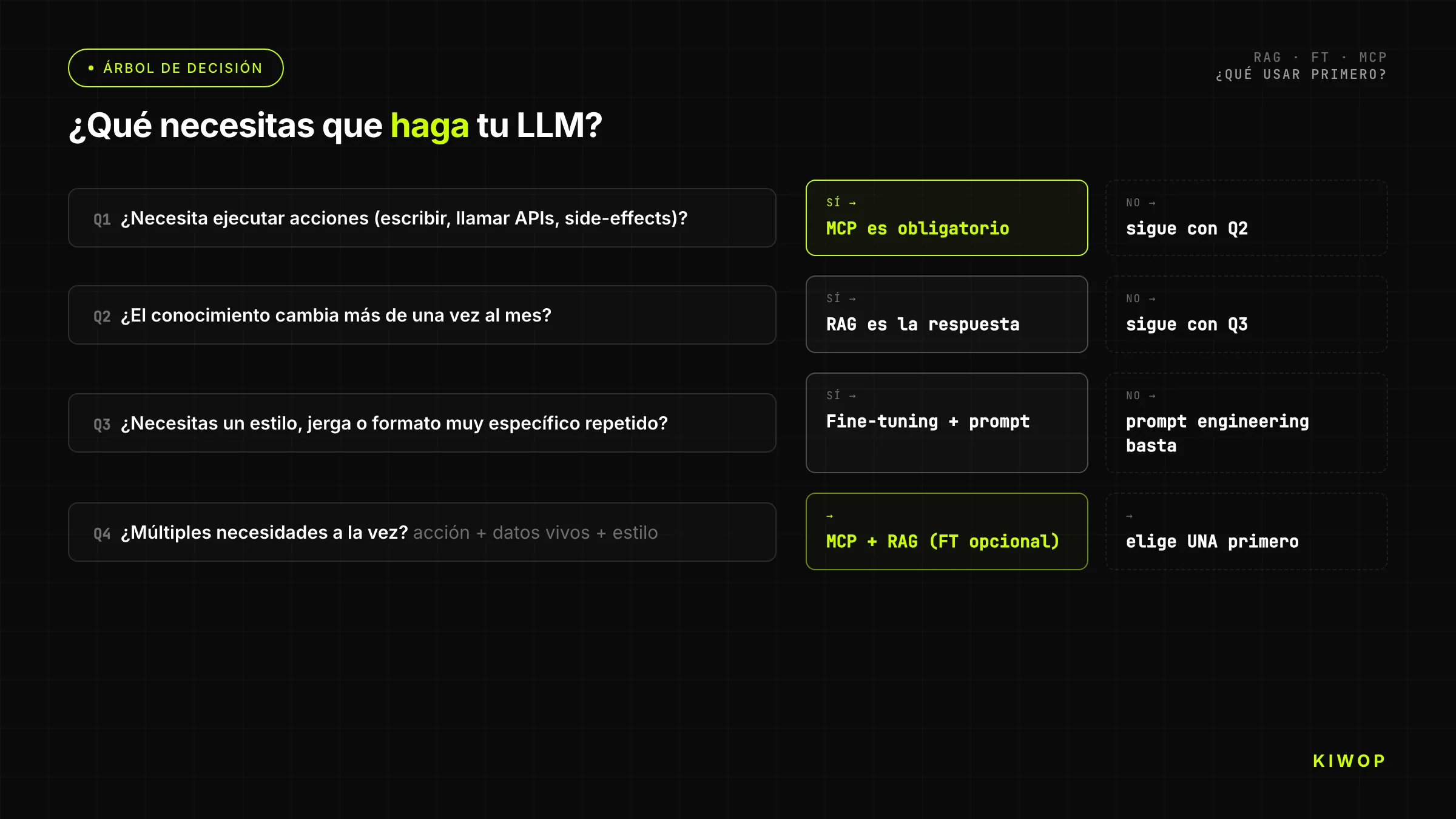
El árbol simplificado para equipos que necesitan una respuesta rápida:
Pregunta 1: ¿el agente necesita ejecutar acciones sobre sistemas externos (leer APIs en tiempo real, escribir datos, invocar procesos)?
- Sí → necesitas MCP. ¿También necesita conocimiento de documentos? Añade RAG. Continúa al árbol por las otras dimensiones.
- No → continúa.
Pregunta 2: ¿el LLM necesita responder sobre documentos, datos o conocimiento que no estuvo en su entrenamiento o que cambia frecuentemente?
- Sí → RAG es la primera respuesta. ¿El corpus tiene más de 200 páginas? Confirma que RAG escala para tu caso. ¿El corpus cabe en la ventana de contexto? Considera meter el contexto directamente sin RAG.
- No → continúa.
Pregunta 3: ¿el modelo base produce respuestas en el formato/tono/estilo incorrecto para tu caso de uso, y tienes más de 500 ejemplos anotados correctamente?
- Sí → fine-tuning es una opción. ¿Agotaste prompt engineering avanzado? Si no, empieza por ahí.
- No → vuelve a evaluar si el problema es realmente de comportamiento del modelo o de conocimiento.
Pregunta 4: ¿tienes recursos y tiempo para mantener el modelo fine-tuneado a lo largo del ciclo de vida del modelo base?
- Sí → fine-tuning.
- No → prompt engineering avanzado + RAG para conocimiento; acepta las limitaciones de comportamiento.
La mayoría de aplicaciones empresariales LLM en producción acaban con RAG + MCP como arquitectura base. Fine-tuning añade complejidad y coste que rara vez justifica el beneficio incremental frente a prompt engineering bien hecho.
Casos reales en Kiwop
Nexo (SaaS multi-tenant): MCP + RAG selectivo
Nexo es el workspace SaaS que estamos construyendo en Kiwop. La arquitectura completa está documentada en el post sobre arquitectura SaaS multi-tenant con Laravel e Inertia.
El agente de Nexo tiene dos capas distintas de acceso a información:
Capa MCP — para operaciones transaccionales: crear tareas, actualizar estados de proyecto, leer métricas del workspace del tenant, enviar notificaciones. Todo esto vive en la base de datos relacional del tenant y tiene una API interna bien definida. Montar un servidor MCP por tenant nos permite que el agente opere sobre datos reales en tiempo real sin latencia de indexación.
Capa RAG selectiva — para documentación y notas no estructuradas: minutas de reunión, especificaciones de producto, documentación técnica que los equipos suben al workspace. Este corpus varía mucho entre tenants y no tiene estructura fija — es exactamente el territorio de RAG. Usamos Qdrant como vector store con partición por tenant para garantizar aislamiento de datos.
Fine-tuning: no hemos hecho ninguno para Nexo. El modelo base con system prompt bien construido cubre el comportamiento esperado. El coste de mantenimiento de un modelo fine-tuneado para un SaaS que evoluciona semanalmente sería prohibitivo.
PA (asistente personal): MCP puro
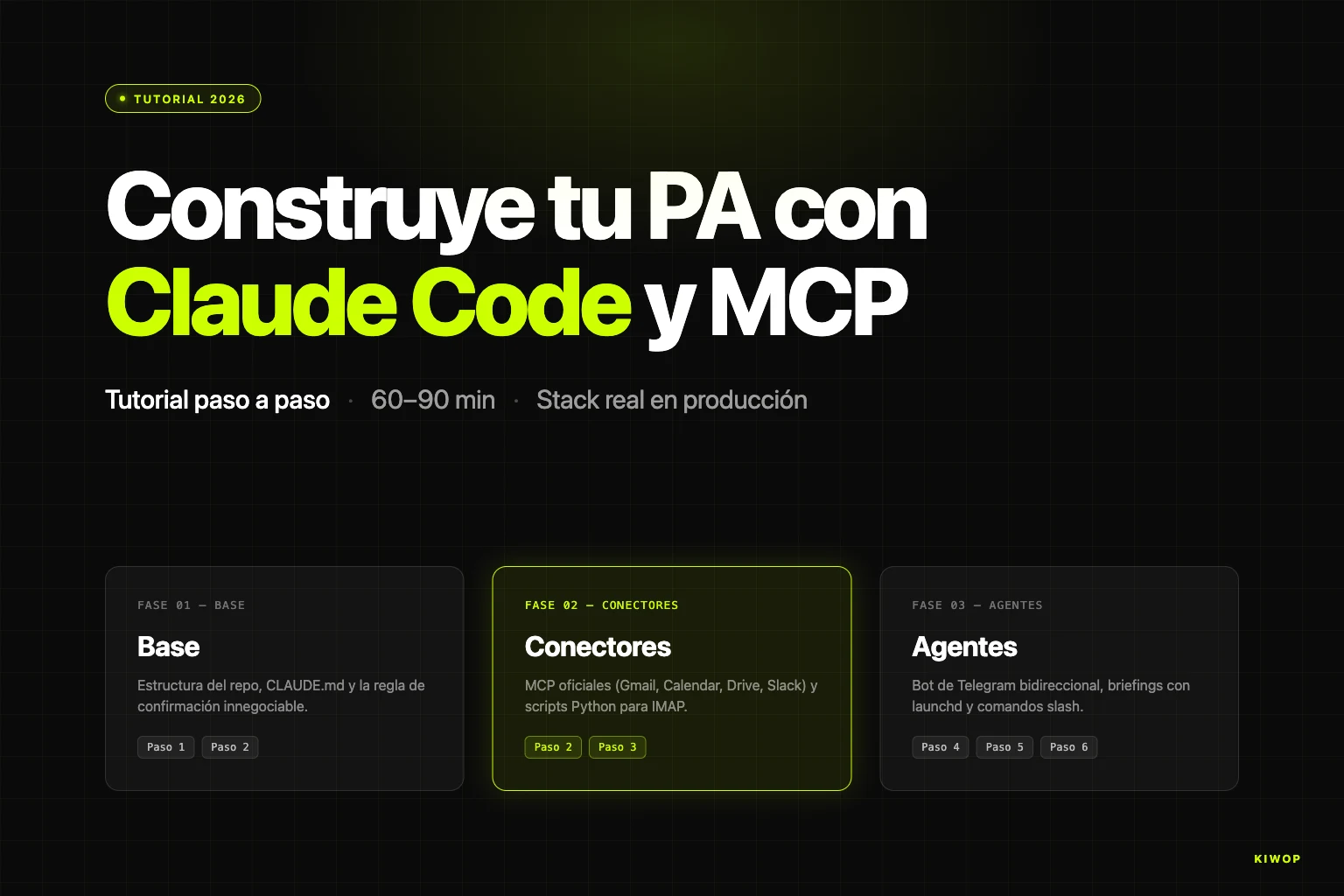
El asistente personal PA que construimos con Claude Code, documentado al detalle en el post construye tu PA con Claude Code y MCP, usa solo MCP stdio.
El PA necesita leer y escribir Gmail, Calendar, Drive y Slack. Toda la información vive en APIs bien definidas con SDKs maduros — exactamente el caso de uso óptimo de MCP. No hay corpus de documentos propietario que indexar (el email se lee directamente), no hay comportamiento que cambiar (el modelo base es suficientemente capaz), y la latencia es tolerable porque las operaciones son asíncronas.
RAG añadiría una capa de complejidad innecesaria. Fine-tuning no resuelve ningún problema real que tengamos. MCP puro es la arquitectura más simple que funciona — y eso es lo que usamos.
Cuándo combinamos los tres
El único caso en que combinamos RAG, MCP y fine-tuning simultáneamente es en proyectos de asistentes para sectores muy específicos — legal y médico, principalmente — donde las tres necesidades son reales:
- MCP para acceder a sistemas internos del cliente (expedientes, calendarios de audiencias, bases de datos de jurisprudencia propias).
- RAG sobre documentación legal o clínica (normativa, protocolos, historial de casos anonimizados).
- Fine-tuning para adaptar el formato de respuesta a la terminología exacta del sector y el estilo comunicativo interno del cliente.
Incluso en esos casos, fine-tuning es siempre lo último que implementamos, después de agotar RAG + prompt engineering. Y el ciclo de mantenimiento del modelo fine-tuneado está explícitamente planificado y presupuestado desde el inicio.
5 antipatrones que vemos en producción
1. Fine-tunear cuando RAG bastaba
Es el antipatrón más frecuente y el más caro. El equipo decide hacer fine-tuning porque "queremos que el modelo conozca nuestros productos" — pero el catálogo de productos cambia mensualmente. Tras semanas de anotación y entrenamiento, el modelo fine-tuneado tiene información desactualizada desde el primer día. La solución correcta desde el principio era RAG con corpus actualizado automáticamente.
La señal de alerta: si te preguntas "¿necesita el modelo saber X?" y X es cualquier cosa que cambia más rápido que tu ciclo de re-entrenamiento, la respuesta es RAG, no fine-tuning.
2. RAG sin re-ranking
Un pipeline RAG sin re-ranking recupera los top-K chunks más similares vectorialmente — pero similitud vectorial no es lo mismo que relevancia real para la pregunta concreta. El modelo recibe contexto parcialmente relevante, mezcla información correcta con ruido, y la calidad de respuesta es mediocre.
El re-ranking con un cross-encoder (modelos como bge-reranker-v2-m3 o Cohere Rerank) añade 50-150ms de latencia pero puede mejorar la precisión de respuesta en un 20-40% según el corpus. Es una de las inversiones con mejor ROI en un pipeline RAG maduro. Y sin embargo, la mayoría de implementaciones que vemos en producción no lo tienen.
3. MCP sin sandboxing
Un agente con MCP puede ejecutar acciones irreversibles: borrar registros, enviar emails masivos, ejecutar transacciones. Sin una capa de confirmación explícita para operaciones destructivas, un agente que malinterpreta una instrucción puede causar daño real.
El patrón correcto: distinguir entre tools de solo lectura (que el agente puede invocar libremente) y tools de escritura o destructivas (que requieren confirmación humana explícita antes de ejecutarse). MCP no impone esto por protocolo — es responsabilidad de la arquitectura del agente. Lo cubrimos en agentes IA en producción: patrones y antipatrones.
4. Combinar todo "por si acaso"
La arquitectura más peligrosa que vemos es la que combina RAG + fine-tuning + MCP desde el día uno sin casos de uso que justifiquen cada capa. El resultado es un sistema difícil de debuggear (¿el error viene del retrieval, de los pesos fine-tuneados, o de la tool call?), caro de mantener, y con múltiples puntos de fallo independientes.
El principio de ingeniería es siempre el mismo: empieza con la arquitectura más simple que resuelve el problema. Añade complejidad solo cuando hay un problema concreto que la justifica. Una aplicación RAG con buen corpus y buen re-ranking frecuentemente supera a una arquitectura RAG+FT+MCP mal diseñada en todos los KPIs que importan.
5. Ignorar el coste de mantener el corpus
Un sistema RAG en producción no es "índexo los documentos una vez y ya está". El corpus envejece: los documentos se actualizan, se añaden nuevos, algunos quedan obsoletos. Si no tienes un proceso de actualización del índice — idealmente automatizado — el retrieval empieza a devolver contexto desactualizado y la calidad del sistema degrada silenciosamente.
El pipeline de mantenimiento de corpus (detección de cambios, re-indexación parcial, validación de calidad del retrieval) es tan importante como el pipeline de ingestion inicial. Cuantifícalo en el presupuesto desde el primer día, o el sistema funciona bien en el demo y mal en producción seis meses después.
Preguntas frecuentes
¿RAG sustituye a fine-tuning?
No como regla general, pero RAG sustituye a fine-tuning en el 80% de los casos en que equipos creen que necesitan fine-tuning. Si el objetivo es que el modelo "sepa más cosas", RAG es casi siempre la respuesta correcta y más mantenible. Fine-tuning gana cuando el objetivo es que el modelo "se comporte de forma distinta" — diferente formato, tono, o razonamiento — y cuando tienes el dataset y el ciclo de mantenimiento para sostenerlo.
¿Cuánto cuesta montar un RAG empresarial?
Un RAG funcional para un corpus de 10.000 documentos con pipeline de ingestion, vector store en Pinecone o Qdrant, re-ranking, y frontend básico cuesta entre $2.000 y $8.000 en desarrollo inicial (2-6 semanas de ingeniería). El coste mensual operativo en infra (vector DB + API calls de embeddings + LLM calls) suele estar entre $200 y $2.000/mes según volumen de queries. El coste de mantenimiento del corpus depende de con qué frecuencia se actualiza y si el proceso es manual o automatizado.
¿Puedo usar RAG y MCP a la vez?
Sí, y es el patrón que recomendamos para la mayoría de agentes empresariales. El agente tiene tools MCP para acceder a datos transaccionales en tiempo real y un retriever RAG para responder sobre documentos y conocimiento no estructurado. Los dos se invocan en momentos distintos del razonamiento y no interfieren entre sí. De hecho, un servidor MCP puede exponer el retriever RAG como tool, haciendo el patrón especialmente limpio.
¿OpenAI o Anthropic para fine-tuning?
Anthropic no ofrece fine-tuning de sus modelos a clientes externos hoy. Las opciones comerciales son OpenAI (GPT-4o mini y GPT-4o), Google Vertex AI (Gemini Pro) y, para modelos open-source, proveedores como Together AI, Replicate, o infraestructura propia. OpenAI tiene la plataforma de fine-tuning más madura y documentada del mercado. Google es competitivo para casos de uso en el ecosistema GCP. Para la mayoría de proyectos nuevos, si el modelo base candidato es de Anthropic, la alternativa al fine-tuning no disponible es construir RAG más sólido o usar prompt caching para reducir costes de prompts largos.
¿Qué vector database elegir?
Depende del contexto. Si ya usas PostgreSQL, pgvector es el punto de entrada con menor fricción operativa. Si necesitas escalar a millones de vectores con latencias submilisegundo, Pinecone tiene el mejor time-to-production. Weaviate es fuerte cuando el corpus es muy grande y necesitas búsqueda híbrida (vectorial + keyword) con múltiples tenants. Qdrant es open-source, rápido, y la mejor opción si quieres control completo sin licencia cloud. Para la mayoría de casos empresariales que manejamos desde RAG empresarial, empezamos con pgvector en el mismo PostgreSQL del cliente y migramos a Qdrant cuando el volumen lo justifica.
Conclusión y siguientes pasos
La pregunta no es "¿RAG, fine-tuning o MCP?" — es "¿qué dimensión del problema estoy resolviendo?". Conocimiento dinámico: RAG. Comportamiento de modelo: fine-tuning, pero con criterio y con plan de mantenimiento. Acción sobre sistemas: MCP.
La mayoría de aplicaciones LLM en producción necesitan RAG + MCP como base. Fine-tuning es el tercer nivel que se añade solo cuando RAG + prompt engineering bien construido no es suficiente, y cuando el equipo tiene capacidad real de sostener el ciclo de vida del modelo.
La trampa más cara es elegir sin criterio y luego descubrir seis meses después que la arquitectura no se sostiene. Hemos visto proyectos que tardaron dos meses en hacer fine-tuning cuando RAG habría tardado dos semanas y habría funcionado mejor. Hemos visto pipelines RAG sin re-ranking que se rediseñaron completos después de que el sistema llegara a producción y la calidad no era aceptable.
Si tu equipo está en este proceso de decisión — evaluando si necesitáis RAG, fine-tuning, MCP, o alguna combinación — eso es exactamente el trabajo que hacemos en Kiwop. Revisamos la arquitectura, el caso de uso, los recursos disponibles, y diseñamos el sistema mínimo que resuelve el problema con el menor coste de mantenimiento. Nuestros servicios de desarrollo de agentes IA, RAG empresarial e integración de LLMs están pensados para equipos que quieren llegar a producción con decisiones técnicas sólidas, sin pagar el precio de aprender todo desde cero. Escríbenos y lo evaluamos.
Si el post te ha sido útil, sigue el hilo con el cluster completo: MCP, WebMCP y A2A: qué protocolo elegir para tus agentes IA, agentes IA en producción: patrones y antipatrones y construye tu PA con Claude Code y MCP.