Door het Kiwop-team · Digitaal Agentschap gespecialiseerd in Softwareontwikkeling en toegepaste Kunstmatige Intelligentie · Gepubliceerd op 7 mei 2026 · Laatst bijgewerkt: 7 mei 2026
TL;DR — RAG is het antwoord wanneer de LLM dynamische kennis nodig heeft die niet in zijn training zat: interne databases, actuele documenten, catalogi. Fine-tuning is het antwoord wanneer je het gedrag, de stijl of het redeneerdomein van het model blijvend wilt veranderen, en je het dataset hebt om dat te rechtvaardigen. MCP is het antwoord wanneer de agent moet handelen en niet alleen herinneren: uitvoeren, lezen, schrijven, APIs aanroepen. Twee of alle drie combineren komt vaak voor en is in veel gevallen de juiste architectuur. Slechts één kiezen zonder de anderen te evalueren is het duurste antipatroon dat we in productie zien.

Elke week krijgen we dezelfde vraag van technische teams die hun eerste LLM-applicaties in productie ontwerpen: "Zetten we RAG op of doen we beter fine-tuning?". En het eerlijke antwoord is dat de vraag bijna altijd verkeerd gesteld is. RAG, fine-tuning en MCP zijn geen alternatieven op dezelfde dimensie: ze lossen verschillende problemen op in verschillende lagen van de stack.
De verwarring is begrijpelijk. De drie technieken worden samen gepresenteerd in tutorials, papers en pitch decks van leveranciers alsof het uitwisselbare benaderingen zijn om "de LLM meer dingen te laten weten". Dat zijn ze niet. Een team dat fine-tuning doet terwijl het RAG nodig heeft, verspilt weken en tienduizenden euro's. Een team dat RAG opzet terwijl het MCP nodig heeft, bouwt een geavanceerd systeem voor informatieretrieval dat uiteindelijk niets kan uitvoeren.
Dit artikel is het beslissingsraamwerk dat ons twee jaar geleden meerdere architectuurcycli had kunnen besparen. Het is gebaseerd op onze echte ervaring met het deployen van AI-agenten in productie, het bouwen van de SaaS Nexo, en het opzetten van de persoonlijke assistent PA op MCP met Claude Code. Het is geen theorie: het is wat we leren wanneer iets in productie faalt en we moeten diagnosticeren waarom.
Waarom een LLM alleen nooit voldoende is
Een taalmodel in pure staat heeft vier structurele beperkingen die geen toename van parameters volledig oplost.
Kennis bevroren in de tijd. De trainingsdata heeft een afsluitdatum. GPT-4o heeft een cutoff in april 2024. Claude 3.5 Sonnet ook in april 2024. Alles wat daarna is gebeurd, bestaat niet voor het model, tenzij je het in de context stopt. Als je applicatie gegevens van vandaag, vorige week of de bijgewerkte catalogus van gisteren nodig heeft, kan het model alleen je niet helpen.
Kennis die er nooit in zat. Modellen worden getraind op publieke data van het internet. Jouw interne documentatie, je contracten, je supporttickets, je bedrijfskennisbank: niets daarvan zit in het basismodel. En dat zou ook niet moeten, om redenen van privacy én beveiliging.
Structurele hallucinaties. Wanneer het model iets niet weet, zegt het dat niet altijd. Soms verzint het het met hetzelfde vertrouwen als wanneer het iets waars zegt. Het probleem is niet de onwetendheid; het is het valse vertrouwen in die onwetendheid. De enige echte oplossing is het model toegang geven tot de bron van waarheid op het moment van inferentie.
Geen handelingscapaciteit. Het model genereert tekst. Het kan je database niet lezen, niet schrijven naar je CRM, geen e-mail versturen. Voor een LLM om in de wereld te handelen heeft het externe tools nodig. Dat is een andere infrastructuurlaag dan kennis.
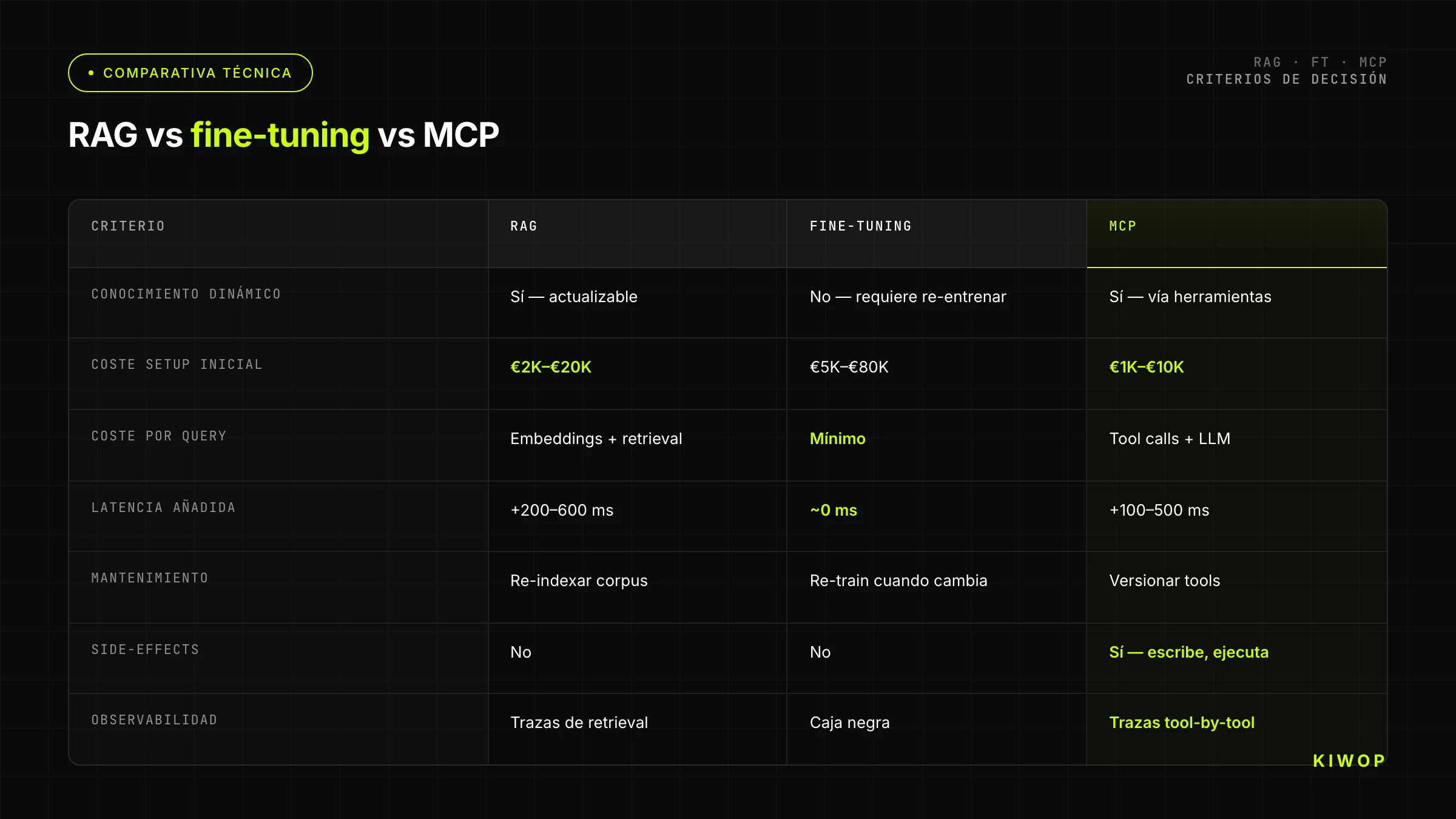
Deze vier beperkingen genereren drie families van oplossingen: RAG voor de eerste twee, fine-tuning voor bepaalde gevallen van de tweede (redeneerdomein), en MCP voor de vierde. Elke aanpak raakt een andere dimensie van het probleem.
De drie strategieën om een LLM met jouw wereld te verbinden
Voordat we in detail treden, een korte definitie van elk die we daarna uitbreiden:
RAG (Retrieval-Augmented Generation): het model ontvangt op het moment van inferentie fragmenten van documenten die zijn opgehaald uit een vectordatabase of een zoekmachine. Het model verandert niet; wat het model ziet, verandert.
Fine-tuning: het model wordt opnieuw getraind op domeinspecifieke data, waarbij zijn gewichten worden aangepast. Het verandert niet wat het model bij elke inferentie ziet; het verandert wat het model is.
MCP (Model Context Protocol): de agent heeft toegang tot getypeerde tools — APIs, databases, externe systemen — die hij tijdens de generatie kan aanroepen. Het is niet alleen kennis; het is handelingscapaciteit.
Het fundamentele onderscheid: RAG is declaratief geheugen, fine-tuning is procedureel leren, MCP is agentie. De drie zijn orthogonaal. Ze kunnen worden gecombineerd zonder dat één de ander vervangt.
RAG — Retrieval-Augmented Generation
Wat het is en hoe het werkt
RAG werd geformaliseerd in het paper van Lewis et al. (Facebook AI Research, 2020) en werd het dominante patroon voor het verbinden van LLMs met eigen kennisbanken. Het idee is misleidend eenvoudig: wanneer een vraag van de gebruiker binnenkomt, haal je — voordat je het model aanroept — de meest relevante fragmenten uit je corpus op, voeg je ze in de prompt in als context, en genereert het model het antwoord gegrond in die bronnen.
De moderne implementatie heeft drie componenten:
- Ingestion pipeline: documenten worden verwerkt, opgeknipt in chunks (typisch 512-1024 tokens met overlapping), geëncodeerd in embeddings en opgeslagen in een vectordatabase (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval: bij inferentie wordt de vraag van de gebruiker omgezet naar een embedding en wordt er gezocht op gelijkenis (cosinus of puntproduct) om de top-K meest relevante chunks op te halen.
- Augmentation: de opgehaalde chunks worden in de systemprompt ingevoegd samen met de vraag, en het model genereert het antwoord.
De meer geavanceerde varianten voegen re-ranking toe (een tweede model sorteert de retrievalresultaten op echte relevantie, niet alleen vectorgelijkenis), HyDE (Hypothetical Document Embeddings, dat een hypothetisch document genereert voordat er gezocht wordt), en hybride RAG (vectorzoeking + BM25 lexicaal gecombineerd). Volgens de RAG-enquête op arxiv van Gao et al. (2024) is re-ranking de individuele factor die de responskwaliteit in enterprise RAG het meest verbetert.
Optimale gebruikssituaties
RAG schittert in precies deze situaties:
- Bedrijfskennisbank: interne documentatie, technische handleidingen, HR-procedures, bedrijfsbeleid. Het corpus wordt regelmatig bijgewerkt; je kunt het model niet elke week opnieuw trainen.
- Klantenservice met eigen product: de assistent moet antwoorden over jouw specifieke product, niet over generieke producten op de markt.
- Ad-hoc documentanalyse: de gebruiker uploadt contracten, rapporten of PDF's en stelt vragen. De inhoud varieert per sessie.
- Compliance en audit: het antwoord moet herleidbaar zijn naar een specifiek fragment van een brondocument — citaat, artikel, clausule. RAG is het enige patroon dat dat structureel doet.
- Data met hoge updatefrequentie: productcatalogi, prijzen, voorraadbeschikbaarheid. Alles wat sneller verandert dan je een model zou bijwerken.
Bij Kiwop implementeren we RAG als basis van het enterprise RAG-systeem voor klanten in de juridische, vastgoed- en fintechsector, waar herleidbaarheid naar brondocumenten niet optioneel is.
Wanneer RAG NIET gebruiken
RAG is niet de oplossing wanneer het probleem niet om kennis maar om gedrag gaat. Als het basismodel antwoorden produceert in een verkeerde opmaak, in een ongeschikt taalregister, of met een redeneertstijl die niet past bij je domein — dat los je niet op met meer context. Een betere prompt misschien wel; RAG niet.
Het is ook niet de oplossing wanneer latentie kritiek is. Een typische RAG-pipeline voegt 200-600ms toe aan de totale latentie: de embeddingtijd van de query, de vectorretrieval en de uitbreiding van de prompt. Voor high-frequency interfaces met de verwachting van een onmiddellijk antwoord kan die overhead onaanvaardbaar zijn.
En het is niet de oplossing wanneer het corpus te klein is. Als je documenten ruimschoots passen in het contextvenster (zeg, minder dan 50 A4-pagina's), is het eenvoudigste patroon het hele document direct in de context te laden. Je kunt maanden data-engineering werk besparen.
Echte kosten: vector DB, infra, latentie
Een functionele enterprise RAG heeft drie kosten die tutorials zelden kwantificeren.
Vectordatabase: Pinecone Starter (gratis tot 2GB) is voldoende voor prototypes. Een gemiddeld bedrijfscorpus (50K documenten met embeddings van 1536 dimensies) heeft 500MB-2GB aan vectoropslag nodig — de limiet wordt sneller bereikt dan verwacht. Pinecone Standard begint bij $70/maand. Weaviate Cloud op productietier is vergelijkbaar. Als je pgvector gebruikt in je bestaande PostgreSQL zijn de opslagkosten marginaal, maar de schaalbaarheid bij gelijktijdige queries vraagt meer beheer.
Embedding bij ingestion: een corpus van 100K chunks met text-embedding-3-small van OpenAI ($0,02/1M tokens) kost minder dan $5 de eerste keer. De echte kosten zitten in de herverwerking wanneer je het embeddingmodel verandert — iets wat onvermijdelijk is als er betere modellen verschijnen — en in de infrastructuur van de ingestion pipeline (worker, queue, deduplicatie, versiebeheer).
Operationele latentie: in productie, inclusief re-ranking, verwacht je 400-800ms extra overhead. Als je LLM al 1-2s nodig heeft om te antwoorden, kan het totaal de 3s naderen — boven de perceptiedrempel van "trage respons" voor conversationele interfaces.
Fine-tuning — het model trainen op jouw domein
Wat het is (LoRA, QLoRA, full fine-tune)
Fine-tuning is het aanpassen van de gewichten van een voorgetraind model op een specifieke dataset, zodat het model patronen, formaten of kennis internaliseert die onvoldoende vertegenwoordigd zijn in zijn basistraining.
Er zijn drie hoofdvarianten naar kosten en capaciteit:
Full fine-tuning: alle gewichten van het model worden bijgewerkt. Maximale aanpassingscapaciteit, hoogste kosten. Voor modellen van 7B parameters zijn GPU's met 80GB VRAM nodig (minimaal twee A100's). Voor modellen van 70B heb je clusters van 8+ GPU's nodig. In de praktijk heeft dit alleen zin met referentie-instanties voor een zeer specifiek domein of met eigen modellen waarbij de leverancier de compute beheert (OpenAI fine-tuning API, Google Vertex AI Tuning).
LoRA (Low-Rank Adaptation): in plaats van alle gewichten bij te werken, worden matrices met lage rang toegevoegd die de delta leren. De PEFT-bibliotheek van Hugging Face implementeert LoRA als standaard; volgens de officiële PEFT-documentatie kan LoRA het aantal traineerbare parameters met meer dan 10.000x reduceren terwijl de kwaliteit vergelijkbaar blijft met full fine-tuning voor veel taken. Een model van 7B met LoRA traint op een GPU A10 van 24GB VRAM.
QLoRA: LoRA op een model gekwantiseerd naar 4-bit. Hiermee kunnen modellen van 70B op een enkele A100 GPU van 80GB getraind worden, ten koste van enige kwaliteitsverlies ten opzichte van LoRA full-precision. Het is de referentievariant voor experimenteren met grote modellen zonder toegang tot een cluster.
De fine-tuning documentatie van OpenAI dekt het volledige proces voor hun modellen (GPT-4o mini, GPT-4o). Fine-tuning van GPT-4o mini kost $3/1M tokens voor training en $0,30/1M tokens bij inferentie (30% meer dan het basismodel). Anthropic biedt geen publieke fine-tuning van hun modellen aan; Google biedt tuning op Gemini Pro via Vertex AI.
Optimale gebruikssituaties
Fine-tuning lost precies deze problemen op:
- Strikte en complexe outputopmaak: als het model JSON moet produceren met een zeer specifiek schema, code in een bedrijfsstijl, of documenten met een vaste structuur, verankert fine-tuning dat patroon beter dan welke instructie in de prompt dan ook.
- Zeer specifiek taalregister en toon: assistenten die precies de merkstem van het bedrijf moeten klinken, met eigen vocabulaire, sectorspecifieke beleefdheidsnormen of zeer gesloten technische terminologie.
- Redeneren in een zeer gespecialiseerd domein: geneeskunde, recht, specifieke industriële procesingenieurswetenschappen. Het basismodel heeft algemene domeinkennis; fine-tuning scherpt het aan op de bijzonderheden van het eigen domein.
- Verminderde latentie via korte prompts: een fine-getuned model kan zich gedragen alsof het een lange systeemprompt heeft zonder die prompt bij elke aanroep nodig te hebben — de gewichten internaliseren de instructies al. Dit verlaagt de invoertokens en daarmee kosten en latentie.
- Repetitieve classificatie en extractie: als je een zeer goed gedefinieerde taak hebt (e-mails classificeren per categorie, entiteiten uit facturen extraheren, adressen normaliseren) met duizenden geannoteerde voorbeelden, overtreft fine-tuning RAG en prompt engineering in nauwkeurigheid en consistentie.
Wanneer NIET fine-tunen
Dit is het deel dat de meeste projecten negeren.
Tune niet fine voor het toevoegen van feitelijke kennis die in de loop van de tijd verandert. Het model leert kennis als statische gewichten; als die kennis veroudert, moet je opnieuw trainen. RAG lost het probleem structureel beter op.
Tune niet fine om hallucinaties van kennis op te lossen. Als het model hallucineert omdat het iets niet weet, kan het geven van meer voorbeelden van die kennis via fine-tuning de hallucinatie verminderen voor gevallen die tijdens training zijn gezien, maar elimineert het die structureel niet — en kan het voor niet-geziene gevallen toenemen. De juiste oplossing is RAG met grounding in de bron.
Tune niet fine zonder kwaliteitsdataset. Het echte minimum om verbetering te zien ligt tussen 100 en 1.000 voorbeelden van hoge kwaliteit, geannoteerd in het juiste formaat. "We hebben 50 voorbeelden" is bijna nooit voldoende. En de voorbeelden moeten de echte verdeling van gevallen dekken, niet alleen de happy paths.
Tune niet fine als eerste experiment. Voordat je fine-tuning doet, put geavanceerde prompt engineering uit (few-shot examples, chain-of-thought, gedetailleerde systeemprompts). In de meeste gevallen geeft een goede prompt 80-90% van het resultaat met 0% van de kosten van fine-tuning.
Echte kosten (compute, dataset, onderhoud)
De kosten hebben drie dimensies die weinig mensen samen berekenen.
Trainingskosten: fine-tuning van GPT-4o mini met 1.000 voorbeelden van 500 tokens = ca. $1-3. Fine-tuning van GPT-4o met hetzelfde dataset = ca. $30-90. LoRA op een open-source 7B-model op een A10G bij AWS = $2-8/uur, een typische run van 2-6 uur = $10-50. LoRA op een 70B in een A100-cluster = $20-80/uur. Dit zijn kosten van de eerste run; experimenteren (hyperparameters testen, fouten herzien, opnieuw trainen) vermenigvuldigt dat makkelijk met 3-5x.
Datasetkosten: menselijke annotatie van kwaliteitsvoorbeelden is de grootste verborgen kost. Als je 1.000 voorbeelden van medische classificatie nodig hebt met etiketten van een specialist, kunnen de annotatiekosten 10x de compute kosten overtreffen. Voor veel projecten is de dataset het echte knelpunt, niet de training.
Onderhoudskosten: een fine-getuned model veroudert. Het domein verandert, edge cases duiken op, het basismodel wordt bijgewerkt (en de fine-tuning migreert niet automatisch mee). Elke updatecyclus van het basismodel impliceert potentieel het opnieuw uitvoeren van de fine-tuning. Dit maakt fine-tuning een langdurige ML-engineering-verplichting, geen eenmalig project.
MCP — tools en handelingscapaciteit
Korte samenvatting
MCP (Model Context Protocol) is de open standaard — gepubliceerd door Anthropic in november 2024 en in december 2025 gedoneerd aan de Linux Foundation — voor het verbinden van LLM-agenten met externe tools. We behandelden de volledige architectuur, inclusief de vergelijking met WebMCP en A2A, in het artikel MCP, WebMCP en A2A: welk protocol kiezen voor jouw AI-agenten.
De basisarchitectuur: een MCP-client (de agent of zijn host) verbindt zich met één of meerdere MCP-servers, ontdekt hun tools via een JSON-RPC-handshake en roept ze aan met getypeerde parameters tijdens de generatie. De tools kunnen alles doen wat een API kan doen: lezen en schrijven naar databases, externe APIs aanroepen, code uitvoeren, e-mails verzenden, bestanden aanpassen.
Met meer dan 10.000 publieke MCP-servers en 97 miljoen maandelijkse SDK-downloads is MCP vandaag de de-facto-standaard voor agent-tools.
Wanneer MCP gebruiken in plaats van RAG
De juiste vraag is niet "MCP of RAG" maar "is het probleem kennis of actie?".
Gebruik MCP wanneer het antwoord real-time data vereist: als de gebruiker vraagt "hoeveel eenheden van product X zijn er nog op voorraad?" staat het antwoord nu in je ERP, niet in een drie dagen oud geïndexeerd document. RAG met bijgewerkt corpus zou kunnen werken, maar MCP is directer: de agent roept de tool get_inventory(product_id="X") aan en krijgt het exacte antwoord zonder indexatielatentie.
Gebruik MCP wanneer het antwoord schrijven of handelen vereist: een ticket aanmaken, een notificatie verzenden, een record bijwerken, een workflow goedkeuren. Dit is nooit RAG-territory — RAG leest alleen.
Gebruik MCP wanneer de bron van waarheid al een API heeft: als je systeem al een goed gedefinieerde API heeft, is het bouwen van een MCP-server erboven vaak eenvoudiger dan het opzetten van een ingestion pipeline + embedding + vector store.
Gebruik MCP wanneer de data gestructureerd en relationeel is: queries die joins, aggregaties of complexe filters op relationele data vereisen, leven beter in SQL via een MCP-server dan in semantisch zoeken op tekstchunks.
In onze architectuur voor de service LLM-integratie is het patroon dat we standaard aanbevelen MCP voor toegang tot transactionele data + RAG voor documentatie en ongestructureerde kennis. De twee coëxisteren zonder conflict.
Beperkingen
MCP voegt latentie toe door tool invocation (een HTTP-round-trip of stdin/stdout per tool). In agenten die veel tools aan elkaar koppelen, stapelt de wachttijd zich op. En de observability van een agent met tools is substantieel complexer dan van een eenvoudige LLM-aanroep: je hebt tracing van tool calls, logging van parameters en resultaten, en foutafhandeling per tool nodig. We behandelen deze patronen in detail in AI-agenten in productie: patronen en antipatronen.
MCP verandert ook niet de redenercapaciteiten van het model. Als het basismodel slecht redeneert in jouw domein, lost het geven van tools dat niet op. Tools versterken wat het model al goed kan; ze corrigeren niet wat het fout doet.
Vergelijkingstabel: RAG vs fine-tuning vs MCP
Beslissingsboom: wat gebruik je?
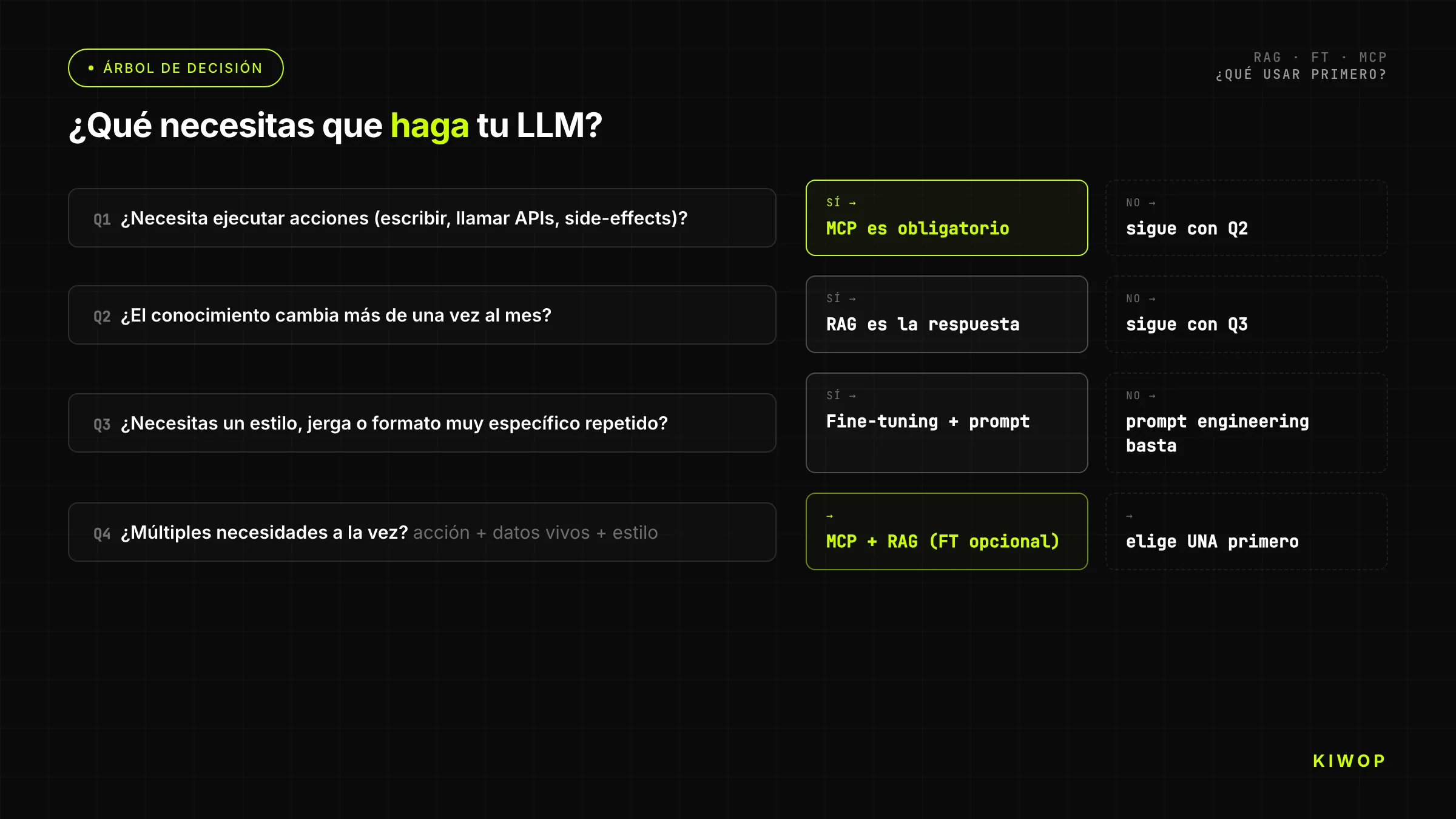
De vereenvoudigde boom voor teams die een snel antwoord nodig hebben:
Vraag 1: moet de agent acties uitvoeren op externe systemen (real-time APIs lezen, data schrijven, processen aanroepen)?
- Ja → je hebt MCP nodig. Heeft hij ook documentkennis nodig? Voeg RAG toe. Ga verder in de boom voor de andere dimensies.
- Nee → ga verder.
Vraag 2: moet de LLM antwoorden over documenten, data of kennis die niet in zijn training zat of die regelmatig verandert?
- Ja → RAG is het eerste antwoord. Heeft het corpus meer dan 200 pagina's? Bevestig dat RAG schaalt voor jouw geval. Past het corpus in het contextvenster? Overweeg de context direct te laden zonder RAG.
- Nee → ga verder.
Vraag 3: produceert het basismodel antwoorden in het verkeerde formaat/toon/stijl voor jouw gebruik, en heb je meer dan 500 correct geannoteerde voorbeelden?
- Ja → fine-tuning is een optie. Heb je geavanceerde prompt engineering uitgeput? Als niet, begin daar.
- Nee → evalueer opnieuw of het probleem echt om modelgedrag of om kennis gaat.
Vraag 4: heb je de middelen en tijd om het fine-getunede model te onderhouden gedurende de levenscyclus van het basismodel?
- Ja → fine-tuning.
- Nee → geavanceerde prompt engineering + RAG voor kennis; accepteer de gedragsbeperkingen.
De meeste enterprise LLM-applicaties in productie eindigen met RAG + MCP als basisarchitectuur. Fine-tuning voegt complexiteit en kosten toe die zelden het incrementele voordeel ten opzichte van goed uitgevoerde prompt engineering rechtvaardigen.
Echte cases bij Kiwop
Nexo (multi-tenant SaaS): MCP + selectieve RAG
Nexo is de SaaS workspace die we bij Kiwop aan het bouwen zijn. De volledige architectuur is gedocumenteerd in het artikel over multi-tenant SaaS-architectuur met Laravel en Inertia.
De agent van Nexo heeft twee afzonderlijke lagen voor toegang tot informatie:
MCP-laag — voor transactionele operaties: taken aanmaken, projectstatussen bijwerken, metrissen van de workspace van de tenant lezen, notificaties versturen. Dit alles leeft in de relationele database van de tenant en heeft een goed gedefinieerde interne API. Een MCP-server per tenant opzetten stelt de agent in staat op echte data in real time te opereren zonder indexatielatentie.
Selectieve RAG-laag — voor documentatie en ongestructureerde notities: vergadernotulen, productspecificaties, technische documentatie die teams uploaden naar de workspace. Dit corpus varieert sterk per tenant en heeft geen vaste structuur — dit is precies het RAG-territorium. We gebruiken Qdrant als vector store met partitionering per tenant om gegevensisolatie te garanderen.
Fine-tuning: we hebben niets gedaan voor Nexo. Het basismodel met een goed geconstrueerde systeemprompt dekt het verwachte gedrag. De onderhoudskosten van een fine-getuned model voor een SaaS die wekelijks evolueert, zouden prohibitief zijn.
PA (persoonlijke assistent): pure MCP
De persoonlijke assistent PA die we bouwden met Claude Code, gedetailleerd gedocumenteerd in het artikel bouw je PA met Claude Code en MCP, gebruikt alleen MCP stdio.
De PA moet Gmail, Calendar, Drive en Slack lezen en schrijven. Alle informatie leeft in goed gedefinieerde APIs met volwassen SDK's — precies de optimale use case voor MCP. Er is geen eigen documentcorpus om te indexeren (e-mail wordt direct gelezen), geen gedrag om te veranderen (het basismodel is voldoende capabel), en de latentie is aanvaardbaar omdat de operaties asynchroon zijn.
RAG zou een onnodige complexiteitslaag toevoegen. Fine-tuning lost geen enkel echt probleem dat we hebben op. Pure MCP is de eenvoudigste architectuur die werkt — en dat is wat we gebruiken.
Wanneer we alle drie combineren
Het enige geval waarin we RAG, MCP en fine-tuning tegelijkertijd combineren, zijn projecten voor assistenten in zeer specifieke sectoren — voornamelijk juridisch en medisch — waar alle drie behoeften echt zijn:
- MCP voor toegang tot interne systemen van de klant (dossiers, zittingskalenders, eigen jurisprudentiedatabases).
- RAG over juridische of klinische documentatie (regelgeving, protocollen, geanonimiseerde casehistorie).
- Fine-tuning om het antwoordformaat aan te passen aan de exacte terminologie van de sector en de interne communicatiestijl van de klant.
Zelfs in die gevallen is fine-tuning altijd het laatste wat we implementeren, nadat RAG + prompt engineering is uitgeput. En de onderhoudscyclus van het fine-getunede model is expliciet gepland en begroot vanaf het begin.
5 antipatronen die we in productie zien
1. Fine-tunen terwijl RAG voldoende was
Het meest voorkomende en duurste antipatroon. Het team besluit fine-tuning te doen omdat "we willen dat het model onze producten kent" — maar de productcatalogus verandert maandelijks. Na weken van annotatie en training heeft het fine-getunede model verouderde informatie vanaf dag één. De juiste oplossing van meet af aan was RAG met automatisch bijgewerkt corpus.
Het alarmsignaal: als je je afvraagt "moet het model X weten?" en X is iets dat sneller verandert dan je hertrainscyclus, is het antwoord RAG, niet fine-tuning.
2. RAG zonder re-ranking
Een RAG-pipeline zonder re-ranking haalt de top-K meest vectorieel gelijkende chunks op — maar vectorgelijkenis is niet hetzelfde als echte relevantie voor de concrete vraag. Het model ontvangt gedeeltelijk relevante context, mengt correcte informatie met ruis, en de responskwaliteit is middelmatig.
Re-ranking met een cross-encoder (modellen zoals bge-reranker-v2-m3 of Cohere Rerank) voegt 50-150ms latentie toe maar kan de responsnauwkeurigheid met 20-40% verbeteren afhankelijk van het corpus. Het is een van de investeringen met de beste ROI in een volwassen RAG-pipeline. En toch heeft de meerderheid van de implementaties die we in productie zien het niet.
3. MCP zonder sandboxing
Een agent met MCP kan onomkeerbare acties uitvoeren: records verwijderen, massale e-mails versturen, transacties uitvoeren. Zonder een expliciete bevestigingslaag voor destructieve operaties kan een agent die een instructie verkeerd interpreteert echte schade veroorzaken.
Het juiste patroon: onderscheid maken tussen read-only tools (die de agent vrij kan aanroepen) en schrijf- of destructieve tools (die expliciete menselijke bevestiging vereisen voordat ze worden uitgevoerd). MCP legt dit niet op via het protocol — het is de verantwoordelijkheid van de agentarchitectuur. We behandelen dit in AI-agenten in productie: patronen en antipatrones.
4. Alles combineren "voor het geval dat"
De gevaarlijkste architectuur die we zien, is die welke RAG + fine-tuning + MCP vanaf dag één combineert zonder use cases die elke laag rechtvaardigen. Het resultaat is een systeem dat moeilijk te debuggen is (komt de fout uit de retrieval, de fine-getunede gewichten of de tool call?), duur te onderhouden, en met meerdere onafhankelijke single points of failure.
Het engineering-principe is altijd hetzelfde: begin met de eenvoudigste architectuur die het probleem oplost. Voeg complexiteit alleen toe wanneer er een concreet probleem is dat het rechtvaardigt. Een RAG-applicatie met een goed corpus en goede re-ranking overtreft regelmatig een slecht ontworpen RAG+FT+MCP-architectuur op alle KPI's die er toe doen.
5. De onderhoudskosten van het corpus negeren
Een RAG-systeem in productie is niet "ik indexeer de documenten één keer en klaar". Het corpus veroudert: documenten worden bijgewerkt, nieuwe worden toegevoegd, sommige raken verouderd. Als je geen proces hebt voor het bijwerken van de index — idealiter geautomatiseerd — begint de retrieval verouderde context terug te geven en degradeert de kwaliteit van het systeem geruisloos.
De onderhoudspipeline van het corpus (detectie van wijzigingen, gedeeltelijke herindexering, validatie van de retrieval-kwaliteit) is net zo belangrijk als de initiële ingestion pipeline. Kwantificeer het in het budget vanaf dag één, anders werkt het systeem goed in de demo en slecht in productie zes maanden later.
Veelgestelde vragen
Vervangt RAG fine-tuning?
Niet als algemene regel, maar RAG vervangt fine-tuning in 80% van de gevallen waarbij teams denken dat ze fine-tuning nodig hebben. Als het doel is dat het model "meer dingen weet", is RAG bijna altijd het juiste en beter onderhoudbare antwoord. Fine-tuning wint wanneer het doel is dat het model "anders gedraagt" — ander formaat, toon of redenering — en wanneer je het dataset en de onderhoudscyclus hebt om dat vol te houden.
Hoeveel kost het opzetten van enterprise RAG?
Een functionele RAG voor een corpus van 10.000 documenten met een ingestion pipeline, vector store in Pinecone of Qdrant, re-ranking en een basis frontend kost tussen €2.000 en €8.000 aan initiële ontwikkeling (2-6 weken engineering). De maandelijkse operationele infrakosten (vector DB + embedding API-calls + LLM-calls) liggen doorgaans tussen €200 en €2.000/maand afhankelijk van het queryvolume. De onderhoudskosten van het corpus hangen af van hoe vaak het wordt bijgewerkt en of het proces handmatig of geautomatiseerd is.
Kan ik RAG en MCP tegelijk gebruiken?
Ja, en het is het patroon dat we voor de meeste enterprise-agenten aanbevelen. De agent heeft MCP-tools om real-time toegang te krijgen tot transactionele data en een RAG-retriever om vragen te beantwoorden over documenten en ongestructureerde kennis. De twee worden op verschillende momenten in het redeneren aangesproken en interfereren niet met elkaar. Een MCP-server kan de RAG-retriever zelfs als tool blootstellen, waardoor het patroon bijzonder schoon wordt.
OpenAI of Anthropic voor fine-tuning?
Anthropic biedt vandaag geen fine-tuning van hun modellen aan externe klanten aan. De commerciële opties zijn OpenAI (GPT-4o mini en GPT-4o), Google Vertex AI (Gemini Pro) en, voor open-source modellen, providers zoals Together AI, Replicate, of eigen infrastructuur. OpenAI heeft het meest volwassen en gedocumenteerde fine-tuning platform op de markt. Google is competitief voor use cases in het GCP-ecosysteem. Voor de meeste nieuwe projecten waarbij het kandidaat-basismodel van Anthropic is, is het alternatief voor niet-beschikbare fine-tuning het bouwen van solidere RAG of het gebruik van prompt caching om de kosten van lange prompts te verlagen.
Welke vectordatabase kiezen?
Dat hangt van de context af. Als je al PostgreSQL gebruikt, is pgvector het instappunt met de minste operationele wrijving. Als je moet schalen naar miljoenen vectoren met submilliseconde latentie, heeft Pinecone de beste time-to-production. Weaviate is sterk wanneer het corpus erg groot is en je hybride zoeken (vectorieel + keyword) met meerdere tenants nodig hebt. Qdrant is open-source, snel en de beste optie als je volledige controle wilt zonder cloudlicentie. Voor de meeste enterprise-cases die we beheren via enterprise RAG, beginnen we met pgvector in de bestaande PostgreSQL van de klant en migreren we naar Qdrant wanneer het volume dat rechtvaardigt.
Conclusie en volgende stappen
De vraag is niet "RAG, fine-tuning of MCP?" — het is "welke dimensie van het probleem los ik op?". Dynamische kennis: RAG. Modelgedrag: fine-tuning, maar met criterium en een onderhoudsplan. Handelen op systemen: MCP.
De meeste LLM-applicaties in productie hebben RAG + MCP als basis nodig. Fine-tuning is het derde niveau dat alleen wordt toegevoegd wanneer RAG + goed geconstrueerde prompt engineering niet voldoende is, en wanneer het team de echte capaciteit heeft om de levenscyclus van het model vol te houden.
De duurste valkuil is zonder criterium kiezen en dan zes maanden later ontdekken dat de architectuur niet standhoudt. We hebben projecten gezien die twee maanden bezig waren met fine-tuning terwijl RAG twee weken zou hebben geduurd en beter zou hebben gewerkt. We hebben RAG-pipelines zonder re-ranking gezien die volledig opnieuw ontworpen werden nadat het systeem productie bereikt had en de kwaliteit niet acceptabel was.
Als jouw team in dit beslissingsproces zit — evalueren of je RAG, fine-tuning, MCP of een combinatie nodig hebt — is dat precies het werk dat we bij Kiwop doen. We beoordelen de architectuur, de use case, de beschikbare middelen en ontwerpen het minimale systeem dat het probleem oplost met de laagste onderhoudskosten. Onze services voor AI-agenten ontwikkelen, enterprise RAG en LLM-integratie zijn bedoeld voor teams die productie willen bereiken met solide technische beslissingen, zonder de prijs te betalen voor alles zelf te leren. Schrijf ons en we evalueren het samen.
Als dit artikel nuttig was, volg de draad met het volledige cluster: MCP, WebMCP en A2A: welk protocol kiezen voor jouw AI-agenten, AI-agenten in productie: patronen en antipatronen en bouw je PA met Claude Code en MCP.


