Per l'equip de Kiwop · Agència Digital especialitzada en Desenvolupament de Programari i Intel·ligència Artificial aplicada · Publicat el 7 de maig de 2026 · Última actualització: 7 de maig de 2026
TL;DR — RAG és la resposta quan el LLM necessita coneixement dinàmic que no va estar en el seu entrenament: bases de dades internes, documents actualitzats, catàlegs. Fine-tuning és la resposta quan necessites canviar el comportament, l'estil o el domini de raonament del model de forma persistent, i tens el dataset per justificar-ho. MCP és la resposta quan l'agent necessita actuar, no només recordar: executar, llegir, escriure, cridar APIs. Combinar dos o els tres és freqüent i, en molts casos, l'arquitectura correcta. Triar només un sense avaluar els altres és l'antipatró més car que veiem en producció.

Cada setmana rebem la mateixa pregunta des d'equips tècnics que estan dissenyant les seves primeres aplicacions LLM en producció: "Muntem RAG o millor fem fine-tuning?". I la resposta honesta és que la pregunta està mal plantejada gairebé sempre. RAG, fine-tuning i MCP no són alternatives en la mateixa dimensió: resolen problemes diferents en capes diferents del stack.
La confusió és comprensible. Les tres tècniques es presenten juntes en tutorials, en papers i en pitch decks de proveïdors com si fossin enfocaments intercanviables per "fer que el LLM sàpiga més coses". No ho són. Un equip que fa fine-tuning quan necessita RAG malgasta setmanes i desenes de milers d'euros. Un equip que munta RAG quan necessita MCP construeix un sistema de recuperació d'informació sofisticat que al final no pot executar res.
Aquest post és el framework de decisió que ens hauria estalviat diversos cicles d'arquitectura fa dos anys. Està basat en la nostra experiència real desplegant agents IA en producció, construint el SaaS Nexo, i muntant l'assistent personal PA sobre MCP amb Claude Code. No és teoria: és el que aprenem quan alguna cosa falla en producció i hem de diagnosticar per què.
Per què un LLM sol mai no és suficient
Un model de llenguatge en estat pur té quatre limitacions estructurals que cap augment de paràmetres resol completament.
Coneixement congelat en el temps. Les dades d'entrenament tenen una data de tall. GPT-4o té tall a l'abril de 2024. Claude 3.5 Sonnet a l'abril de 2024. Tot el que va passar després no existeix per al model, excepte el que li posis al context. Si la teva aplicació necessita dades d'avui, la setmana passada, o el catàleg actualitzat d'ahir, el model sol no pot ajudar-te.
Coneixement que mai no hi va estar. Els models s'entrenen amb dades públiques d'internet. La teva documentació interna, els teus contractes, els teus tickets de suport, la teva base de coneixement corporativa: res d'això és al model base. I no hi hauria d'estar, per raons de privacitat tant com de seguretat.
Al·lucinacions estructurals. Quan el model no sap alguna cosa, no sempre ho diu. De vegades ho inventa amb la mateixa confiança amb què diu alguna cosa veritable. El problema no és la ignorància; és la confiança falsa en la ignorància. L'única solució real és donar al model accés a la font de veritat en el moment de la inferència.
Sense capacitat d'acció. El model genera text. No pot llegir la teva base de dades, no pot escriure al teu CRM, no pot enviar un email. Perquè un LLM actuï al món necessita eines externes. Això és una capa d'infraestructura diferent al coneixement.
Aquestes quatre limitacions generen tres famílies de solucions: RAG per a les dues primeres, fine-tuning per a certs casos de la segona (domini de raonament), i MCP per a la quarta. Cadascuna toca una dimensió diferent del problema.
Les tres estratègies per connectar un LLM amb el teu món
Abans d'entrar en detall, una definició curta de cadascuna que després expandirem:
RAG (Retrieval-Augmented Generation): el model rep, en el moment de la inferència, fragments de documents recuperats d'una base de dades vectorial o un motor de cerca. No canvia el model; canvia el que el model veu.
Fine-tuning: el model es reentrena sobre dades específiques del domini, ajustant els seus pesos. No canvia el que el model veu en cada inferència; canvia el que el model és.
MCP (Model Context Protocol): l'agent té accés a eines tipades — APIs, bases de dades, sistemes externs — que pot invocar durant la generació. No és només coneixement; és capacitat d'acció.
La distinció fonamental: RAG és memòria declarativa, fine-tuning és aprenentatge procedural, MCP és agència. Els tres són ortogonals. Es poden combinar sense que un substitueixi l'altre.
RAG — Retrieval-Augmented Generation
Què és i com funciona
RAG va ser formalitzat al paper de Lewis et al. (Facebook AI Research, 2020) i es va convertir en el patró dominant per connectar LLMs amb bases de coneixement pròpies. La idea és enganyosament simple: quan arriba una pregunta de l'usuari, abans de cridar el model, recuperes els fragments més rellevants del teu corpus, els insereixes al prompt com a context, i el model genera la resposta ancorada en aquelles fonts.
La implementació moderna té tres components:
- Ingestion pipeline: els documents es processen, es tallen en chunks (típicament 512-1024 tokens amb solapament), s'encodifiquen en embeddings, i s'emmagatzemen en una base de dades vectorial (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval: en inferència, la pregunta de l'usuari es converteix en embedding i es fa cerca per similitud (cosinus o producte punt) per recuperar els top-K chunks més rellevants.
- Augmentation: els chunks recuperats s'insereixen al prompt del sistema juntament amb la pregunta, i el model genera la resposta.
Les variants més sofisticades afegeixen re-ranking (un segon model ordena els resultats del retrieval per rellevància real, no només similitud vectorial), HyDE (Hypothetical Document Embeddings, que genera un document hipotètic abans de cercar), i RAG híbrid (cerca vectorial + BM25 lèxic combinats). Segons l'enquesta sobre RAG d'arxiv de Gao et al. (2024), el re-ranking és el factor individual que més millora la qualitat de resposta en RAG empresarial.
Casos d'ús òptims
RAG brilla exactament en aquestes situacions:
- Knowledge base empresarial: documentació interna, manuals tècnics, procediments de RRHH, polítiques d'empresa. El corpus s'actualitza amb freqüència; no pots re-entrenar el model cada setmana.
- Suport al client amb producte propi: l'assistent necessita respondre sobre el teu producte específic, no sobre productes genèrics del mercat.
- Anàlisi de documents ad-hoc: l'usuari puja contractes, informes, o PDFs i fa preguntes. El contingut varia en cada sessió.
- Compliance i auditoria: la resposta ha de poder traçar-se a un fragment concret d'un document font — cita, article, clàusula. RAG és l'únic patró que ho fa estructuralment.
- Dades amb alta freqüència d'actualització: catàlegs de producte, preus, disponibilitat d'inventari. Qualsevol cosa que canvia més ràpid del que actualitzaries un model.
A Kiwop implementem RAG com a base del sistema de RAG empresarial per a clients en sectors legal, immobiliari i fintech, on la traçabilitat a document font no és opcional.
Quan NO usar RAG
RAG no és la solució quan el problema no és de coneixement sinó de comportament. Si el model base produeix respostes en un format incorrecte, en un registre d'idioma inadequat, o amb un estil de raonament que no encaixa amb el teu domini — això no s'arregla amb més context. Un prompt millor potser sí; RAG, no.
Tampoc és la solució quan la latència és crítica. Un pipeline RAG típic afegeix 200-600ms a la latència total: el temps d'embedding de la query, el retrieval vectorial, i l'ampliació del prompt. Per a interfícies d'alta freqüència amb expectativa de resposta immediata, aquest overhead pot ser inacceptable.
I no és la solució quan el corpus és massa petit. Si els teus documents caben còmodament a la finestra de context (diguem, menys de 50 pàgines A4), el patró més simple és posar tot el document al context directament. Pots estalviar mesos de treball d'enginyeria de dades.
Costos reals: vector DB, infra, latència
Un RAG empresarial funcional té tres costos que els tutorials rarament quantifiquen.
Vector database: Pinecone Starter (gratuït fins a 2GB) és suficient per a prototips. Un corpus empresarial mitjà (50K documents amb embeddings de 1536 dimensions) ronda els 500MB-2GB vectorials — el límit s'assoleix abans del que s'espera. Pinecone Standard comença a $70/mes. Weaviate Cloud al seu tier de producció és comparable. Si uses pgvector al teu PostgreSQL existent, el cost d'emmagatzematge és marginal, però l'escalabilitat de queries concurrents requereix més gestió.
Embedding en ingestion: un corpus de 100K chunks amb text-embedding-3-small d'OpenAI ($0.02/1M tokens) costa menys de $5 la primera vegada. El cost real és el reprocesament quan canvies el model d'embeddings — cosa inevitable quan emergeixen millors models — i la infraestructura del pipeline d'ingestion (worker, queue, deduplicació, versionat).
Latència operativa: en producció, amb re-ranking inclòs, espera 400-800ms d'overhead afegit. Si el teu LLM ja tarda 1-2s a respondre, el total pot apropar-se als 3s — per sobre del llindar de percepció de "resposta lenta" per a interfícies conversacionals.
Fine-tuning — entrenar el model en el teu domini
Què és (LoRA, QLoRA, full fine-tune)
Fine-tuning és ajustar els pesos d'un model preentrenat sobre un dataset específic, de manera que el model interioritza patrons, formats, o coneixements que no estan suficientment representats en el seu entrenament base.
Hi ha tres variants principals segons cost i capacitat:
Full fine-tuning: tots els pesos del model s'actualitzen. Màxima capacitat d'adaptació, cost més alt. Per a models de 7B paràmetres requereix GPUs amb 80GB VRAM (dos A100 com a mínim). Per a models de 70B ja estem parlant de clústers de 8+ GPUs. A la pràctica, només té sentit amb instàncies de referència per a domini molt específic o amb models propietaris on el proveïdor gestiona el còmput (OpenAI fine-tuning API, Google Vertex AI Tuning).
LoRA (Low-Rank Adaptation): en lloc d'actualitzar tots els pesos, s'afegeixen matrius de rang baix que aprenen el delta. La llibreria PEFT de Hugging Face implementa LoRA com a estàndard; segons la documentació oficial de PEFT, LoRA pot reduir el nombre de paràmetres entrenables en més de 10.000x mantenint una qualitat comparable al full fine-tuning en moltes tasques. Un model de 7B amb LoRA entrena en una GPU A10 de 24GB VRAM.
QLoRA: LoRA sobre model quantitzat a 4-bit. Permet entrenar models de 70B en una sola GPU A100 de 80GB, a costa d'una mica de qualitat respecte a LoRA full-precision. És la variant de referència per a experimentació amb models grans sense accés a clúster.
La documentació de fine-tuning d'OpenAI cobreix el procés complet per als seus models (GPT-4o mini, GPT-4o). El fine-tuning de GPT-4o mini té un cost de $3/1M tokens en entrenament i $0.30/1M tokens en inferència (un 30% superior al model base). Anthropic no ofereix fine-tuning públic dels seus models; Google ofereix tuning sobre Gemini Pro via Vertex AI.
Casos d'ús òptims
Fine-tuning resol exactament aquests problemes:
- Format de sortida estricte i complex: si el model ha de produir JSON amb un schema molt específic, codi en un estil de l'empresa, o documents amb estructura fixa, el fine-tuning fixa aquell patró millor que qualsevol instrucció al prompt.
- Registre d'idioma i to molt específic: assistents que han de sonar exactament com la veu de marca de l'empresa, amb vocabulari propi, formes de cortesia específiques del sector, o terminologia tècnica molt tancada.
- Raonament en domini molt especialitzat: medicina, dret, enginyeria específica de procés industrial. El model base té coneixement general del domini; el fine-tuning l'afila en les particularitats del domini propi.
- Latència reduïda via prompts curts: un model fine-tunejat pot comportar-se com si tingués un system prompt llarg sense necessitar aquell prompt en cada crida — els pesos ja interioritzen les instruccions. Això redueix tokens d'entrada i, per tant, cost i latència.
- Classificació i extracció repetitiva: si tens una tasca molt definida (classificar emails per categoria, extreure entitats de factures, normalitzar adreces) amb milers d'exemples anotats, fine-tuning supera RAG i prompt engineering en precisió i consistència.
Quan NO fer fine-tuning
Aquesta és la part que més projectes ignoren.
No facis fine-tuning per afegir coneixement factual que canvia amb el temps. El model aprèn el coneixement com a pesos estàtics; quan aquell coneixement caduca, has de re-entrenar. RAG resol el problema estructuralment millor.
No facis fine-tuning per resoldre al·lucinacions de coneixement. Si el model al·lucina perquè no sap alguna cosa, donar-li més exemples d'aquell coneixement en fine-tuning pot reduir l'al·lucinació en els casos vistos durant l'entrenament, però no l'elimina estructuralment — i pot augmentar-la en casos no vistos. La solució correcta és RAG amb ancoratge a font.
No facis fine-tuning sense dataset de qualitat. El mínim real per veure millora és entre 100 i 1.000 exemples d'alta qualitat, anotats amb el format correcte. "Tenim 50 exemples" gairebé mai no és suficient. I els exemples han de cobrir la distribució real de casos, no només els casos feliços.
No facis fine-tuning com a primer experiment. Abans de fine-tuning, esgota el prompt engineering avançat (few-shot examples, chain-of-thought, system prompts detallats). En la majoria de casos, un prompt ben construït dóna el 80-90% del resultat amb el 0% del cost de fine-tuning.
Costos reals (còmput, dataset, manteniment)
Els costos tenen tres dimensions que poca gent calcula conjuntament.
Cost d'entrenament: fine-tuning de GPT-4o mini amb 1.000 exemples de 500 tokens = aprox. $1-3. Fine-tuning de GPT-4o amb el mateix dataset = aprox. $30-90. LoRA sobre un model 7B open-source en un A10G a AWS = $2-8/hora, una execució típica de 2-6 hores = $10-50. LoRA sobre un 70B en clúster d'A100 = $20-80/hora. Aquests són costos de primera execució; l'experimentació (provar hiperparàmetres, revisar errors, re-entrenar) multiplica fàcilment per 3-5x.
Cost de dataset: l'anotació humana d'exemples de qualitat és el cost ocult més gran. Si necessites 1.000 exemples de classificació mèdica amb etiquetatge d'especialista, el cost d'anotació pot superar en 10x el cost de còmput. Per a molts projectes, el dataset és el coll d'ampolla real, no l'entrenament.
Cost de manteniment: un model fine-tunejat envelleix. El domini canvia, els casos extrems emergeixen, el model base s'actualitza (i el fine-tuning no migra automàticament). Cada cicle d'actualització del model base implica potencialment repetir el fine-tuning. Això converteix el fine-tuning en un compromís a llarg termini d'enginyeria de ML, no un projecte puntual.
MCP — eines i acció
Resum ràpid
MCP (Model Context Protocol) és l'estàndard obert — publicat per Anthropic el novembre de 2024 i donat a la Linux Foundation el desembre de 2025 — per connectar agents LLM amb eines externes. Cobrim la seva arquitectura completa, incloent la comparativa amb WebMCP i A2A, al post MCP, WebMCP i A2A: quin protocol triar per als teus agents IA.
L'arquitectura bàsica: un client MCP (l'agent o el seu host) es connecta a un o diversos servidors MCP, descobreix les seves tools mitjançant un handshake JSON-RPC, i les invoca amb paràmetres tipats durant la generació. Les tools poden fer qualsevol cosa que una API pot fer: llegir i escriure en bases de dades, cridar APIs externes, executar codi, enviar emails, modificar fitxers.
Amb més de 10.000 servidors MCP públics i 97 milions de descàrregues mensuals de SDK, MCP és avui l'estàndard de facto per a eines d'agents.
Quan usar MCP en lloc de RAG
La pregunta correcta no és "MCP o RAG" sinó "¿el problema és de coneixement o d'acció?".
Usa MCP quan la resposta requereix llegir dades en temps real: si l'usuari pregunta "quantes unitats queden en magatzem del producte X?" la resposta és al teu ERP ara mateix, no en un document indexat fa tres dies. RAG amb corpus actualitzat podria funcionar, però MCP és més directe: l'agent crida la tool get_inventory(product_id="X") i obté la resposta exacta sense latència d'indexació.
Usa MCP quan la resposta requereix escriptura o acció: crear un tiquet, enviar una notificació, actualitzar un registre, aprovar un workflow. Això mai no és territori RAG — RAG només llegeix.
Usa MCP quan la font de veritat ja té API: si el teu sistema ja té una API ben definida, construir un servidor MCP al damunt és freqüentment més senzill que muntar un pipeline d'ingestion + embedding + vector store.
Usa MCP quan les dades són estructurades i relacionals: consultes que impliquen joins, agregacions o filtres complexos sobre dades relacionals viuen millor en SQL via un servidor MCP que en cerca semàntica sobre chunks de text.
A la nostra arquitectura per al servei d'integració de LLMs, el patró que recomanem per defecte és MCP per a accés a dades transaccionals + RAG per a documentació i coneixement no estructurat. Els dos conviuen sense conflicte.
Limitacions
MCP afegeix latència de tool invocation (un round-trip HTTP o stdin/stdout per eina). En agents que encadenen moltes tools, el temps d'espera s'acumula. I l'observabilitat d'un agent amb tools és substancialment més complexa que la d'una simple LLM call: necessites tracing de tool calls, logging de paràmetres i resultats, i gestió d'errors en cada eina. Cobrim aquests patrons en detall a agents IA en producció: patrons i antipatrons.
MCP tampoc canvia les capacitats de raonament del model. Si el model base raona malament en el teu domini, donar-li tools no ho corregeix. Les tools amplien el que el model ja sap fer; no corregeixen el que fa malament.
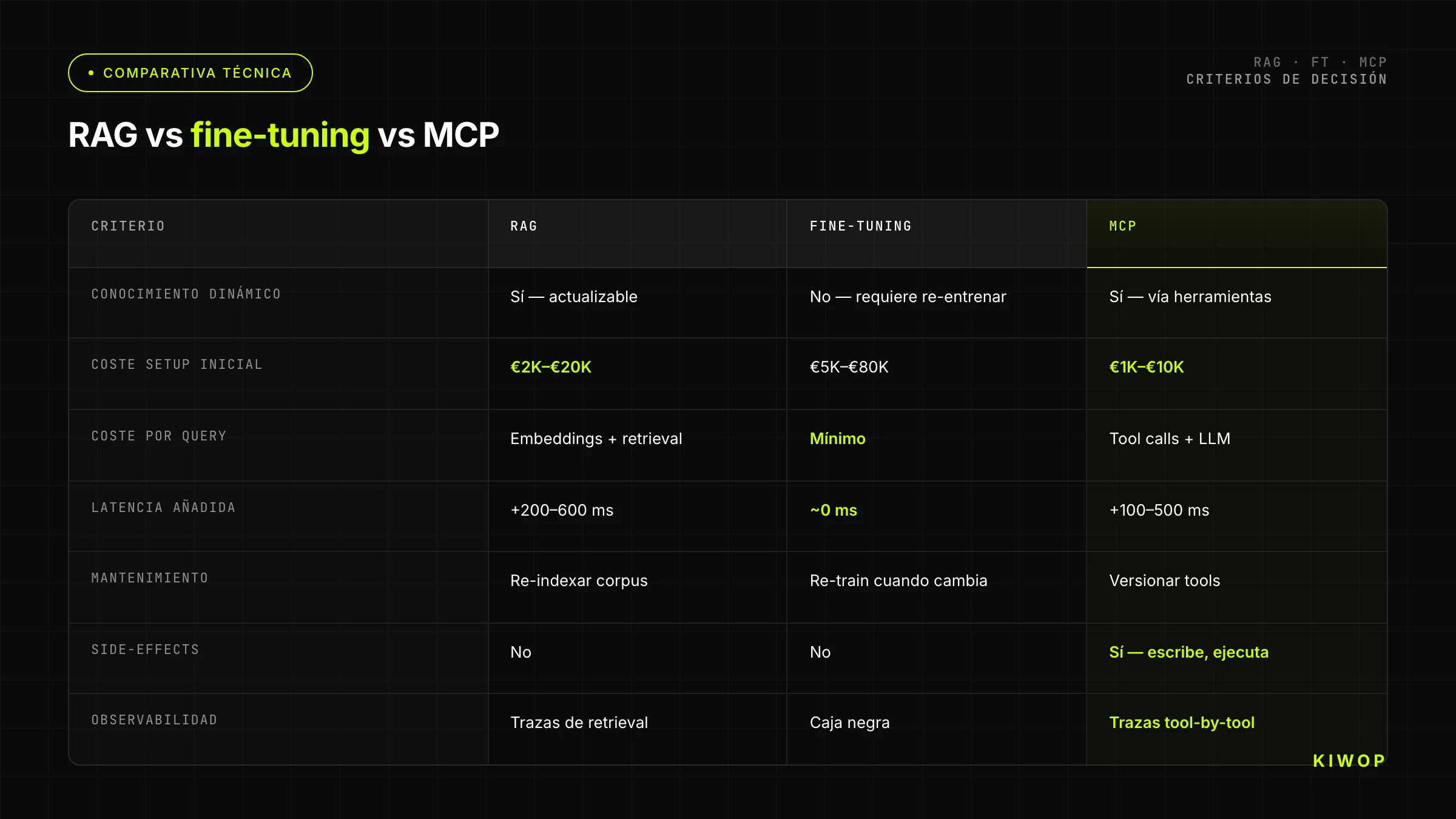
Taula comparativa: RAG vs fine-tuning vs MCP
Arbre de decisió: què usar?
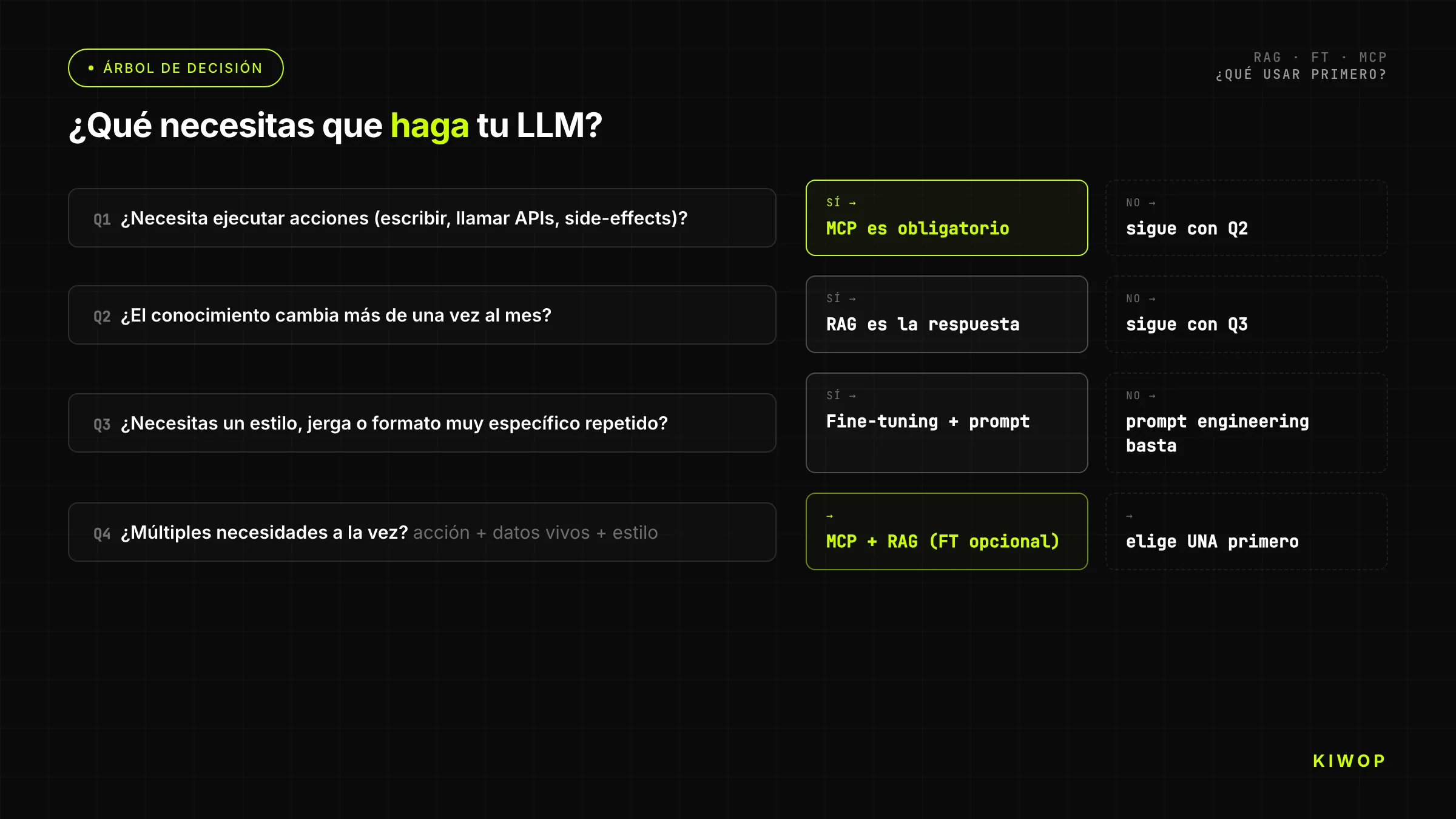
L'arbre simplificat per a equips que necessiten una resposta ràpida:
Pregunta 1: l'agent necessita executar accions sobre sistemes externs (llegir APIs en temps real, escriure dades, invocar processos)?
- Sí → necessites MCP. ¿També necessita coneixement de documents? Afegeix RAG. Continua a l'arbre per les altres dimensions.
- No → continua.
Pregunta 2: el LLM necessita respondre sobre documents, dades o coneixement que no va estar en el seu entrenament o que canvia freqüentment?
- Sí → RAG és la primera resposta. ¿El corpus té més de 200 pàgines? Confirma que RAG escala per al teu cas. ¿El corpus cap a la finestra de context? Considera posar el context directament sense RAG.
- No → continua.
Pregunta 3: el model base produeix respostes en el format/to/estil incorrecte per al teu cas d'ús, i tens més de 500 exemples anotats correctament?
- Sí → fine-tuning és una opció. ¿Has esgotat el prompt engineering avançat? Si no, comença per aquí.
- No → torna a avaluar si el problema és realment de comportament del model o de coneixement.
Pregunta 4: tens recursos i temps per mantenir el model fine-tunejat al llarg del cicle de vida del model base?
- Sí → fine-tuning.
- No → prompt engineering avançat + RAG per a coneixement; accepta les limitacions de comportament.
La majoria d'aplicacions empresarials LLM en producció acaben amb RAG + MCP com a arquitectura base. Fine-tuning afegeix complexitat i cost que rarament justifica el benefici incremental davant de prompt engineering ben fet.
Casos reals a Kiwop
Nexo (SaaS multi-tenant): MCP + RAG selectiu
Nexo és el workspace SaaS que estem construint a Kiwop. L'arquitectura completa està documentada al post sobre arquitectura SaaS multi-tenant amb Laravel i Inertia.
L'agent de Nexo té dues capes diferents d'accés a informació:
Capa MCP — per a operacions transaccionals: crear tasques, actualitzar estats de projecte, llegir mètriques del workspace del tenant, enviar notificacions. Tot això viu a la base de dades relacional del tenant i té una API interna ben definida. Muntar un servidor MCP per tenant ens permet que l'agent operi sobre dades reals en temps real sense latència d'indexació.
Capa RAG selectiva — per a documentació i notes no estructurades: actes de reunió, especificacions de producte, documentació tècnica que els equips pengen al workspace. Aquest corpus varia molt entre tenants i no té estructura fixa — és exactament el territori de RAG. Usem Qdrant com a vector store amb partició per tenant per garantir aïllament de dades.
Fine-tuning: no n'hem fet cap per a Nexo. El model base amb system prompt ben construït cobreix el comportament esperat. El cost de manteniment d'un model fine-tunejat per a un SaaS que evoluciona setmanalment seria prohibitiu.
PA (assistent personal): MCP pur
L'assistent personal PA que vam construir amb Claude Code, documentat al detall al post construeix el teu PA amb Claude Code i MCP, usa només MCP stdio.
El PA necessita llegir i escriure Gmail, Calendar, Drive i Slack. Tota la informació viu en APIs ben definides amb SDKs madurs — exactament el cas d'ús òptim de MCP. No hi ha corpus de documents propi que indexar (el correu es llegeix directament), no hi ha comportament que canviar (el model base és prou capaç), i la latència és tolerable perquè les operacions són asíncrones.
RAG afegiria una capa de complexitat innecessària. Fine-tuning no resol cap problema real que tinguem. MCP pur és l'arquitectura més simple que funciona — i és la que usem.
Quan combinem els tres
L'únic cas en què combinem RAG, MCP i fine-tuning simultàniament és en projectes d'assistents per a sectors molt específics — legal i mèdic, principalment — on les tres necessitats són reals:
- MCP per accedir a sistemes interns del client (expedients, calendaris d'audiències, bases de dades de jurisprudència pròpies).
- RAG sobre documentació legal o clínica (normativa, protocols, historial de casos anonimitzats).
- Fine-tuning per adaptar el format de resposta a la terminologia exacta del sector i l'estil comunicatiu intern del client.
Fins i tot en aquells casos, fine-tuning és sempre l'últim que implementem, després d'esgotar RAG + prompt engineering. I el cicle de manteniment del model fine-tunejat està explícitament planificat i pressupostat des de l'inici.
5 antipatrons que veiem en producció
1. Fer fine-tuning quan RAG n'hi havia prou
És l'antipatró més freqüent i el més car. L'equip decideix fer fine-tuning perquè "volem que el model conegui els nostres productes" — però el catàleg de productes canvia mensualment. Després de setmanes d'anotació i entrenament, el model fine-tunejat té informació desactualitzada des del primer dia. La solució correcta des del principi era RAG amb corpus actualitzat automàticament.
El senyal d'alerta: si et preguntes "necessita el model saber X?" i X és qualsevol cosa que canvia més ràpid que el teu cicle de re-entrenament, la resposta és RAG, no fine-tuning.
2. RAG sense re-ranking
Un pipeline RAG sense re-ranking recupera els top-K chunks més similars vectorialment — però la similitud vectorial no és el mateix que la rellevància real per a la pregunta concreta. El model rep context parcialment rellevant, barreja informació correcta amb soroll, i la qualitat de resposta és mediocre.
El re-ranking amb un cross-encoder (models com bge-reranker-v2-m3 o Cohere Rerank) afegeix 50-150ms de latència però pot millorar la precisió de resposta en un 20-40% segons el corpus. És una de les inversions amb millor ROI en un pipeline RAG madur. I tanmateix, la majoria d'implementacions que veiem en producció no el tenen.
3. MCP sense sandboxing
Un agent amb MCP pot executar accions irreversibles: esborrar registres, enviar emails massius, executar transaccions. Sense una capa de confirmació explícita per a operacions destructives, un agent que mal interpreta una instrucció pot causar danys reals.
El patró correcte: distingir entre tools de només lectura (que l'agent pot invocar lliurement) i tools d'escriptura o destructives (que requereixen confirmació humana explícita abans d'executar-se). MCP no imposa això per protocol — és responsabilitat de l'arquitectura de l'agent. Ho cobrim a agents IA en producció: patrons i antipatrons.
4. Combinar-ho tot "per si de cas"
L'arquitectura més perillosa que veiem és la que combina RAG + fine-tuning + MCP des del dia u sense casos d'ús que justifiquin cada capa. El resultat és un sistema difícil de debuguejar (l'error ve del retrieval, dels pesos fine-tunejats, o de la tool call?), car de mantenir, i amb múltiples punts de fallada independents.
El principi d'enginyeria és sempre el mateix: comença amb l'arquitectura més simple que resol el problema. Afegeix complexitat només quan hi ha un problema concret que la justifica. Una aplicació RAG amb bon corpus i bon re-ranking freqüentment supera una arquitectura RAG+FT+MCP mal dissenyada en tots els KPIs que importen.
5. Ignorar el cost de mantenir el corpus
Un sistema RAG en producció no és "indexo els documents una vegada i ja està". El corpus envelleix: els documents s'actualitzen, se n'afegeixen de nous, alguns queden obsolets. Si no tens un procés d'actualització de l'índex — idealment automatitzat — el retrieval comença a retornar context desactualitzat i la qualitat del sistema degrada silenciosament.
El pipeline de manteniment del corpus (detecció de canvis, re-indexació parcial, validació de qualitat del retrieval) és tan important com el pipeline d'ingestion inicial. Quantifica-ho en el pressupost des del primer dia, o el sistema funciona bé en la demo i malament en producció sis mesos després.
Preguntes freqüents
RAG substitueix el fine-tuning?
No com a regla general, però RAG substitueix el fine-tuning en el 80% dels casos en què els equips creuen que el necessiten. Si l'objectiu és que el model "sàpiga més coses", RAG és gairebé sempre la resposta correcta i més mantenible. Fine-tuning guanya quan l'objectiu és que el model "es comporti de forma diferent" — diferent format, to, o raonament — i quan tens el dataset i el cicle de manteniment per sostenir-ho.
Quant costa muntar un RAG empresarial?
Un RAG funcional per a un corpus de 10.000 documents amb pipeline d'ingestion, vector store a Pinecone o Qdrant, re-ranking, i frontend bàsic costa entre €2.000 i €8.000 en desenvolupament inicial (2-6 setmanes d'enginyeria). El cost mensual operatiu en infra (vector DB + API calls d'embeddings + LLM calls) sol estar entre €200 i €2.000/mes segons volum de queries. El cost de manteniment del corpus depèn de la freqüència d'actualització i de si el procés és manual o automatitzat.
Puc usar RAG i MCP alhora?
Sí, i és el patró que recomanem per a la majoria d'agents empresarials. L'agent té tools MCP per accedir a dades transaccionals en temps real i un retriever RAG per respondre sobre documents i coneixement no estructurat. Els dos s'invoquen en moments diferents del raonament i no interfereixen entre si. De fet, un servidor MCP pot exposar el retriever RAG com a tool, fent el patró especialment net.
OpenAI o Anthropic per a fine-tuning?
Anthropic no ofereix fine-tuning dels seus models a clients externs avui. Les opcions comercials són OpenAI (GPT-4o mini i GPT-4o), Google Vertex AI (Gemini Pro) i, per a models open-source, proveïdors com Together AI, Replicate, o infraestructura pròpia. OpenAI té la plataforma de fine-tuning més madura i documentada del mercat. Google és competitiu per a casos d'ús en l'ecosistema GCP. Per a la majoria de projectes nous, si el model base candidat és d'Anthropic, l'alternativa al fine-tuning no disponible és construir RAG més sòlid o usar prompt caching per reduir costos de prompts llargs.
Quina vector database triar?
Depèn del context. Si ja uses PostgreSQL, pgvector és el punt d'entrada amb menys fricció operativa. Si necessites escalar a milions de vectors amb latències submil·lisegon, Pinecone té el millor time-to-production. Weaviate és fort quan el corpus és molt gran i necessites cerca híbrida (vectorial + keyword) amb múltiples tenants. Qdrant és open-source, ràpid, i la millor opció si vols control complet sense llicència cloud. Per a la majoria de casos empresarials que gestionem des de RAG empresarial, comencem amb pgvector al mateix PostgreSQL del client i migrem a Qdrant quan el volum ho justifica.
Conclusió i passos següents
La pregunta no és "RAG, fine-tuning o MCP?" — és "quina dimensió del problema estic resolent?". Coneixement dinàmic: RAG. Comportament de model: fine-tuning, però amb criteri i amb pla de manteniment. Acció sobre sistemes: MCP.
La majoria d'aplicacions LLM en producció necessiten RAG + MCP com a base. Fine-tuning és el tercer nivell que s'afegeix només quan RAG + prompt engineering ben construït no és suficient, i quan l'equip té capacitat real de sostenir el cicle de vida del model.
La trampa més cara és triar sense criteri i descobrir sis mesos després que l'arquitectura no es sosté. Hem vist projectes que van tardar dos mesos a fer fine-tuning quan RAG hauria tardat dues setmanes i hauria funcionat millor. Hem vist pipelines RAG sense re-ranking que es van redissenyar completament després que el sistema va arribar a producció i la qualitat no era acceptable.
Si el teu equip és en aquest procés de decisió — avaluant si necessiteu RAG, fine-tuning, MCP, o alguna combinació — és exactament el treball que fem a Kiwop. Revisem l'arquitectura, el cas d'ús, els recursos disponibles, i dissenyem el sistema mínim que resol el problema amb el menor cost de manteniment. Els nostres serveis de desenvolupament d'agents IA, RAG empresarial i integració de LLMs estan pensats per a equips que volen arribar a producció amb decisions tècniques sòlides, sense pagar el preu d'aprendre-ho tot des de zero. Escriu-nos i ho avaluem.
Si el post t'ha estat útil, segueix el fil amb el cluster complet: MCP, WebMCP i A2A: quin protocol triar per als teus agents IA, agents IA en producció: patrons i antipatrons i construeix el teu PA amb Claude Code i MCP.


