Par l'équipe de Kiwop · Agence Digitale spécialisée en Développement Logiciel et Intelligence Artificielle appliquée · Publié le 7 mai 2026 · Dernière mise à jour : 7 mai 2026
TL;DR — RAG est la réponse quand le LLM a besoin d'une connaissance dynamique absente de son entraînement : bases de données internes, documents mis à jour, catalogues. Le fine-tuning est la réponse quand vous devez modifier le comportement, le style ou le domaine de raisonnement du modèle de façon persistante, et que vous disposez du dataset pour le justifier. MCP est la réponse quand l'agent doit agir, pas seulement mémoriser : exécuter, lire, écrire, appeler des APIs. Combiner deux ou les trois est fréquent et, dans de nombreux cas, constitue l'architecture correcte. Choisir l'un sans évaluer les autres est l'antipatron le plus coûteux que nous observons en production.

Chaque semaine nous recevons la même question d'équipes techniques qui conçoivent leurs premières applications LLM en production : « Montons-nous un RAG ou vaut-il mieux faire du fine-tuning ? ». Et la réponse honnête est que la question est mal posée presque à chaque fois. RAG, fine-tuning et MCP ne sont pas des alternatives sur la même dimension : ils résolvent des problèmes différents dans des couches différentes du stack.
La confusion est compréhensible. Les trois techniques sont présentées ensemble dans des tutoriels, des papers et des pitch decks de fournisseurs comme si elles étaient des approches interchangeables pour « faire en sorte que le LLM en sache davantage ». Ce n'est pas le cas. Une équipe qui fait du fine-tuning alors qu'elle a besoin de RAG gaspille des semaines et des dizaines de milliers d'euros. Une équipe qui monte un RAG alors qu'elle a besoin de MCP construit un système sophistiqué de récupération d'information qui, au final, ne peut rien exécuter.
Ce post est le framework de décision qui nous aurait épargné plusieurs cycles d'architecture il y a deux ans. Il est basé sur notre expérience réelle de déploiement d'agents IA en production, de construction du SaaS Nexo, et de mise en place de l'assistant personnel PA sur MCP avec Claude Code. Ce n'est pas de la théorie : c'est ce que nous apprenons quand quelque chose échoue en production et que nous devons en diagnostiquer la cause.
Pourquoi un LLM seul ne suffit jamais
Un modèle de langage à l'état pur possède quatre limitations structurelles qu'aucune augmentation de paramètres ne résout complètement.
Connaissance figée dans le temps. Les données d'entraînement ont une date de coupure. GPT-4o a une coupure en avril 2024. Claude 3.5 Sonnet en avril 2024. Tout ce qui s'est passé après n'existe pas pour le modèle, sauf ce que vous lui mettez dans le contexte. Si votre application a besoin de données d'aujourd'hui, de la semaine dernière, ou du catalogue mis à jour d'hier, le modèle seul ne peut pas vous aider.
Connaissance qui n'a jamais été là. Les modèles sont entraînés sur des données publiques d'internet. Votre documentation interne, vos contrats, vos tickets de support, votre base de connaissance d'entreprise : rien de tout cela n'est dans le modèle de base. Et cela ne devrait pas y être, pour des raisons de confidentialité autant que de sécurité.
Hallucinations structurelles. Quand le modèle ne sait pas quelque chose, il ne le dit pas toujours. Parfois il l'invente avec la même confiance que lorsqu'il dit quelque chose de vrai. Le problème n'est pas l'ignorance ; c'est la fausse confiance dans l'ignorance. La seule vraie solution est de donner au modèle accès à la source de vérité au moment de l'inférence.
Absence de capacité d'action. Le modèle génère du texte. Il ne peut pas lire votre base de données, écrire dans votre CRM ni envoyer un email. Pour qu'un LLM agisse dans le monde, il a besoin d'outils externes. C'est une couche d'infrastructure différente de la connaissance.
Ces quatre limitations génèrent trois familles de solutions : RAG pour les deux premières, fine-tuning pour certains cas de la deuxième (domaine de raisonnement), et MCP pour la quatrième. Chacune touche une dimension distincte du problème.
Les trois stratégies pour connecter un LLM à votre monde
Avant d'entrer dans les détails, une définition courte de chacune que nous développerons ensuite :
RAG (Retrieval-Augmented Generation) : le modèle reçoit, au moment de l'inférence, des fragments de documents récupérés depuis une base de données vectorielle ou un moteur de recherche. Le modèle ne change pas ; ce que le modèle voit change.
Fine-tuning : le modèle est ré-entraîné sur des données spécifiques au domaine, en ajustant ses poids. Ce n'est pas ce que le modèle voit à chaque inférence qui change ; c'est ce que le modèle est.
MCP (Model Context Protocol) : l'agent a accès à des outils typés — APIs, bases de données, systèmes externes — qu'il peut invoquer pendant la génération. Ce n'est pas seulement de la connaissance ; c'est une capacité d'action.
La distinction fondamentale : RAG est la mémoire déclarative, le fine-tuning est l'apprentissage procédural, MCP est l'agentivité. Les trois sont orthogonaux. Ils peuvent se combiner sans que l'un remplace l'autre.
RAG — Retrieval-Augmented Generation
Ce que c'est et comment ça fonctionne
RAG a été formalisé dans le paper de Lewis et al. (Facebook AI Research, 2020) et est devenu le pattern dominant pour connecter les LLMs à des bases de connaissance propriétaires. L'idée est trompeusement simple : quand une question arrive de l'utilisateur, avant d'appeler le modèle, vous récupérez les fragments les plus pertinents de votre corpus, vous les insérez dans le prompt comme contexte, et le modèle génère la réponse en s'ancrant dans ces sources.
L'implémentation moderne comporte trois composants :
- Pipeline d'ingestion : les documents sont traités, découpés en chunks (typiquement 512-1024 tokens avec chevauchement), encodés en embeddings, et stockés dans une base de données vectorielle (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval : à l'inférence, la question de l'utilisateur est convertie en embedding et une recherche par similarité (cosinus ou produit scalaire) est effectuée pour récupérer les top-K chunks les plus pertinents.
- Augmentation : les chunks récupérés sont insérés dans le prompt système avec la question, et le modèle génère la réponse.
Les variantes plus sophistiquées ajoutent le re-ranking (un second modèle ordonne les résultats du retrieval par pertinence réelle, pas seulement similitude vectorielle), HyDE (Hypothetical Document Embeddings, qui génère un document hypothétique avant de chercher), et le RAG hybride (recherche vectorielle + BM25 lexical combinés). Selon l'enquête sur le RAG d'arxiv de Gao et al. (2024), le re-ranking est le facteur individuel qui améliore le plus la qualité de réponse dans le RAG d'entreprise.
Cas d'usage optimaux
RAG excelle exactement dans ces situations :
- Base de connaissance d'entreprise : documentation interne, manuels techniques, procédures RH, politiques d'entreprise. Le corpus se met à jour fréquemment ; vous ne pouvez pas ré-entraîner le modèle chaque semaine.
- Support client avec produit propre : l'assistant doit répondre sur votre produit spécifique, pas sur des produits génériques du marché.
- Analyse de documents ad hoc : l'utilisateur uploade des contrats, rapports ou PDFs et pose des questions. Le contenu varie à chaque session.
- Conformité et audit : la réponse doit pouvoir être tracée à un fragment précis d'un document source — citation, article, clause. RAG est le seul pattern qui le fait structurellement.
- Données à haute fréquence de mise à jour : catalogues de produits, prix, disponibilité des stocks. Tout ce qui change plus vite que vous ne mettriez à jour un modèle.
Chez Kiwop, nous implémentons RAG comme base du système de RAG entreprise pour des clients dans les secteurs juridique, immobilier et fintech, où la traçabilité au document source n'est pas optionnelle.
Quand NE PAS utiliser RAG
RAG n'est pas la solution quand le problème n'est pas de connaissance mais de comportement. Si le modèle de base produit des réponses dans un format incorrect, dans un registre de langue inapproprié, ou avec un style de raisonnement qui ne correspond pas à votre domaine — ça ne se règle pas avec plus de contexte. Un meilleur prompt peut-être ; RAG, non.
Ce n'est pas non plus la solution quand la latence est critique. Un pipeline RAG typique ajoute 200-600 ms à la latence totale : le temps d'embedding de la requête, le retrieval vectoriel et l'augmentation du prompt. Pour des interfaces à haute fréquence avec attente de réponse immédiate, cet overhead peut être inacceptable.
Et ce n'est pas la solution quand le corpus est trop petit. Si vos documents tiennent facilement dans la fenêtre de contexte (disons, moins de 50 pages A4), le pattern le plus simple est d'injecter tout le document dans le contexte directement. Vous pouvez économiser des mois de travail d'ingénierie des données.
Coûts réels : vector DB, infrastructure, latence
Un RAG d'entreprise fonctionnel a trois coûts que les tutoriels quantifient rarement.
Base de données vectorielle : Pinecone Starter (gratuit jusqu'à 2 Go) suffit pour les prototypes. Un corpus d'entreprise moyen (50 000 documents avec embeddings de 1 536 dimensions) avoisine les 500 Mo-2 Go vectoriels — la limite est atteinte plus tôt que prévu. Pinecone Standard démarre à 70 $/mois. Weaviate Cloud sur son tier de production est comparable. Si vous utilisez pgvector dans votre PostgreSQL existant, le coût de stockage est marginal, mais la scalabilité des requêtes concurrentes demande plus de gestion.
Embedding en ingestion : un corpus de 100 000 chunks avec text-embedding-3-small d'OpenAI (0,02 $/1M tokens) coûte moins de 5 $ la première fois. Le coût réel est le retraitement quand vous changez de modèle d'embeddings — inévitable quand de meilleurs modèles émergent — et l'infrastructure du pipeline d'ingestion (worker, queue, déduplication, versionnage).
Latence opérationnelle : en production, avec re-ranking inclus, attendez 400-800 ms d'overhead ajouté. Si votre LLM met déjà 1-2 s à répondre, le total peut frôler les 3 s — au-dessus du seuil de perception de « réponse lente » pour les interfaces conversationnelles.
Fine-tuning — entraîner le modèle sur votre domaine
Ce que c'est (LoRA, QLoRA, full fine-tune)
Le fine-tuning consiste à ajuster les poids d'un modèle pré-entraîné sur un dataset spécifique, de façon à ce que le modèle internalise des patterns, des formats ou des connaissances insuffisamment représentés dans son entraînement de base.
Il existe trois variantes principales selon le coût et la capacité :
Full fine-tuning : tous les poids du modèle sont mis à jour. Capacité d'adaptation maximale, coût le plus élevé. Pour des modèles de 7B paramètres, il faut des GPUs avec 80 Go de VRAM (deux A100 minimum). Pour des modèles de 70B, on parle de clusters de 8+ GPUs. En pratique, cela n'a de sens qu'avec des instances de référence pour un domaine très spécifique ou avec des modèles propriétaires où le fournisseur gère le compute (API fine-tuning OpenAI, Google Vertex AI Tuning).
LoRA (Low-Rank Adaptation) : au lieu de mettre à jour tous les poids, on ajoute des matrices de bas rang qui apprennent le delta. La librairie PEFT de Hugging Face implémente LoRA comme standard ; selon la documentation officielle de PEFT, LoRA peut réduire le nombre de paramètres entraînables de plus de 10 000x en maintenant une qualité comparable au full fine-tuning pour de nombreuses tâches. Un modèle de 7B avec LoRA s'entraîne sur un GPU A10 de 24 Go de VRAM.
QLoRA : LoRA sur modèle quantisé en 4 bits. Permet d'entraîner des modèles de 70B sur un seul GPU A100 de 80 Go, au prix d'une légère perte de qualité par rapport à LoRA full-precision. C'est la variante de référence pour l'expérimentation avec de grands modèles sans accès à un cluster.
La documentation de fine-tuning d'OpenAI couvre le processus complet pour ses modèles (GPT-4o mini, GPT-4o). Le fine-tuning de GPT-4o mini coûte 3 $/1M tokens en entraînement et 0,30 $/1M tokens en inférence (30 % de plus que le modèle de base). Anthropic ne propose pas de fine-tuning public de ses modèles ; Google propose du tuning sur Gemini Pro via Vertex AI.
Cas d'usage optimaux
Le fine-tuning résout exactement ces problèmes :
- Format de sortie strict et complexe : si le modèle doit produire du JSON avec un schéma très spécifique, du code dans le style de l'entreprise, ou des documents avec une structure fixe, le fine-tuning ancre ce pattern mieux que n'importe quelle instruction dans le prompt.
- Registre de langue et ton très spécifiques : assistants qui doivent sonner exactement comme la voix de marque de l'entreprise, avec un vocabulaire propre, des formes de politesse spécifiques au secteur, ou une terminologie technique très fermée.
- Raisonnement dans un domaine très spécialisé : médecine, droit, ingénierie spécifique à un processus industriel. Le modèle de base a une connaissance générale du domaine ; le fine-tuning l'affûte sur les particularités du domaine propre.
- Latence réduite via prompts courts : un modèle fine-tuné peut se comporter comme s'il avait un long system prompt sans avoir besoin de ce prompt à chaque appel — les poids internalisent déjà les instructions. Cela réduit les tokens d'entrée et, par conséquent, le coût et la latence.
- Classification et extraction répétitives : si vous avez une tâche très définie (classer des emails par catégorie, extraire des entités de factures, normaliser des adresses) avec des milliers d'exemples annotés, le fine-tuning surpasse RAG et prompt engineering en précision et cohérence.
Quand NE PAS faire de fine-tuning
C'est la partie que la plupart des projets ignorent.
Ne faites pas de fine-tuning pour ajouter des connaissances factuelles qui changent dans le temps. Le modèle apprend la connaissance comme poids statiques ; quand cette connaissance devient obsolète, vous devez ré-entraîner. RAG résout le problème structurellement mieux.
Ne faites pas de fine-tuning pour résoudre des hallucinations de connaissance. Si le modèle hallucine parce qu'il ne sait pas quelque chose, lui donner plus d'exemples de cette connaissance en fine-tuning peut réduire l'hallucination pour les cas vus en entraînement, mais ne l'élimine pas structurellement — et peut l'augmenter pour les cas non vus. La solution correcte est RAG avec ancrage dans la source.
Ne faites pas de fine-tuning sans dataset de qualité. Le minimum réel pour voir une amélioration est entre 100 et 1 000 exemples de haute qualité, annotés dans le bon format. « Nous avons 50 exemples » ne suffit presque jamais. Et les exemples doivent couvrir la distribution réelle des cas, pas seulement les cas nominaux.
Ne faites pas de fine-tuning comme première expérience. Avant le fine-tuning, épuisez le prompt engineering avancé (exemples few-shot, chain-of-thought, system prompts détaillés). Dans la plupart des cas, un prompt bien construit donne 80-90 % du résultat avec 0 % du coût du fine-tuning.
Coûts réels (compute, dataset, maintenance)
Les coûts ont trois dimensions que peu de personnes calculent ensemble.
Coût d'entraînement : fine-tuning de GPT-4o mini avec 1 000 exemples de 500 tokens = environ 1-3 $. Fine-tuning de GPT-4o avec le même dataset = environ 30-90 $. LoRA sur un modèle 7B open-source sur un A10G sur AWS = 2-8 $/heure, une run typique de 2-6 heures = 10-50 $. LoRA sur un 70B sur cluster d'A100 = 20-80 $/heure. Ce sont des coûts de première run ; l'expérimentation (tester des hyperparamètres, réviser les erreurs, ré-entraîner) multiplie facilement par 3-5x.
Coût du dataset : l'annotation humaine d'exemples de qualité est le coût caché le plus important. Si vous avez besoin de 1 000 exemples de classification médicale avec labellisation par un spécialiste, le coût d'annotation peut dépasser de 10x le coût du compute. Pour beaucoup de projets, le dataset est le vrai goulot d'étranglement, pas l'entraînement.
Coût de maintenance : un modèle fine-tuné vieillit. Le domaine change, les cas limites émergent, le modèle de base se met à jour (et le fine-tuning ne migre pas automatiquement). Chaque cycle de mise à jour du modèle de base implique potentiellement de répéter le fine-tuning. Cela fait du fine-tuning un engagement à long terme en ML engineering, pas un projet ponctuel.
MCP — outils et action
Récapitulatif rapide
MCP (Model Context Protocol) est le standard ouvert — publié par Anthropic en novembre 2024 et donné à la Linux Foundation en décembre 2025 — pour connecter des agents LLM à des outils externes. Nous couvrons son architecture complète, y compris la comparaison avec WebMCP et A2A, dans le post MCP, WebMCP et A2A : quel protocole choisir pour vos agents IA.
L'architecture de base : un client MCP (l'agent ou son hôte) se connecte à un ou plusieurs serveurs MCP, découvre leurs outils via un handshake JSON-RPC, et les invoque avec des paramètres typés pendant la génération. Les outils peuvent faire tout ce qu'une API peut faire : lire et écrire en base de données, appeler des APIs externes, exécuter du code, envoyer des emails, modifier des fichiers.
Avec plus de 10 000 serveurs MCP publics et 97 millions de téléchargements mensuels de SDK, MCP est aujourd'hui le standard de facto pour les outils d'agents.
Quand utiliser MCP plutôt que RAG
La bonne question n'est pas « MCP ou RAG » mais « le problème est-il de connaissance ou d'action ? ».
Utilisez MCP quand la réponse nécessite de lire des données en temps réel : si l'utilisateur demande « combien d'unités reste-t-il en stock du produit X ? » la réponse est dans votre ERP en ce moment même, pas dans un document indexé il y a trois jours. RAG avec corpus mis à jour pourrait fonctionner, mais MCP est plus direct : l'agent appelle l'outil get_inventory(product_id="X") et obtient la réponse exacte sans latence d'indexation.
Utilisez MCP quand la réponse nécessite une écriture ou une action : créer un ticket, envoyer une notification, mettre à jour un enregistrement, approuver un workflow. Ce n'est jamais du territoire RAG — RAG lit seulement.
Utilisez MCP quand la source de vérité a déjà une API : si votre système dispose déjà d'une API bien définie, construire un serveur MCP par-dessus est souvent plus simple que monter un pipeline d'ingestion + embedding + vector store.
Utilisez MCP quand les données sont structurées et relationnelles : les requêtes impliquant des jointures, agrégations ou filtres complexes sur des données relationnelles vivent mieux dans SQL via un serveur MCP que dans la recherche sémantique sur des chunks de texte.
Dans notre architecture pour le service d'intégration de LLMs, le pattern que nous recommandons par défaut est MCP pour l'accès aux données transactionnelles + RAG pour la documentation et la connaissance non structurée. Les deux coexistent sans conflit.
Limitations
MCP ajoute de la latence d'invocation d'outils (un round-trip HTTP ou stdin/stdout par outil). Dans des agents qui enchaînent beaucoup d'outils, le temps d'attente s'accumule. Et l'observabilité d'un agent avec des outils est substantiellement plus complexe que celle d'un simple appel LLM : vous avez besoin de tracing des tool calls, de logging des paramètres et résultats, et de gestion des erreurs sur chaque outil. Nous couvrons ces patterns en détail dans agents IA en production : patterns et antipatterns.
MCP ne change pas non plus les capacités de raisonnement du modèle. Si le modèle de base raisonne mal dans votre domaine, lui donner des outils ne le corrige pas. Les outils amplifient ce que le modèle sait déjà faire ; ils ne corrigent pas ce qu'il fait mal.
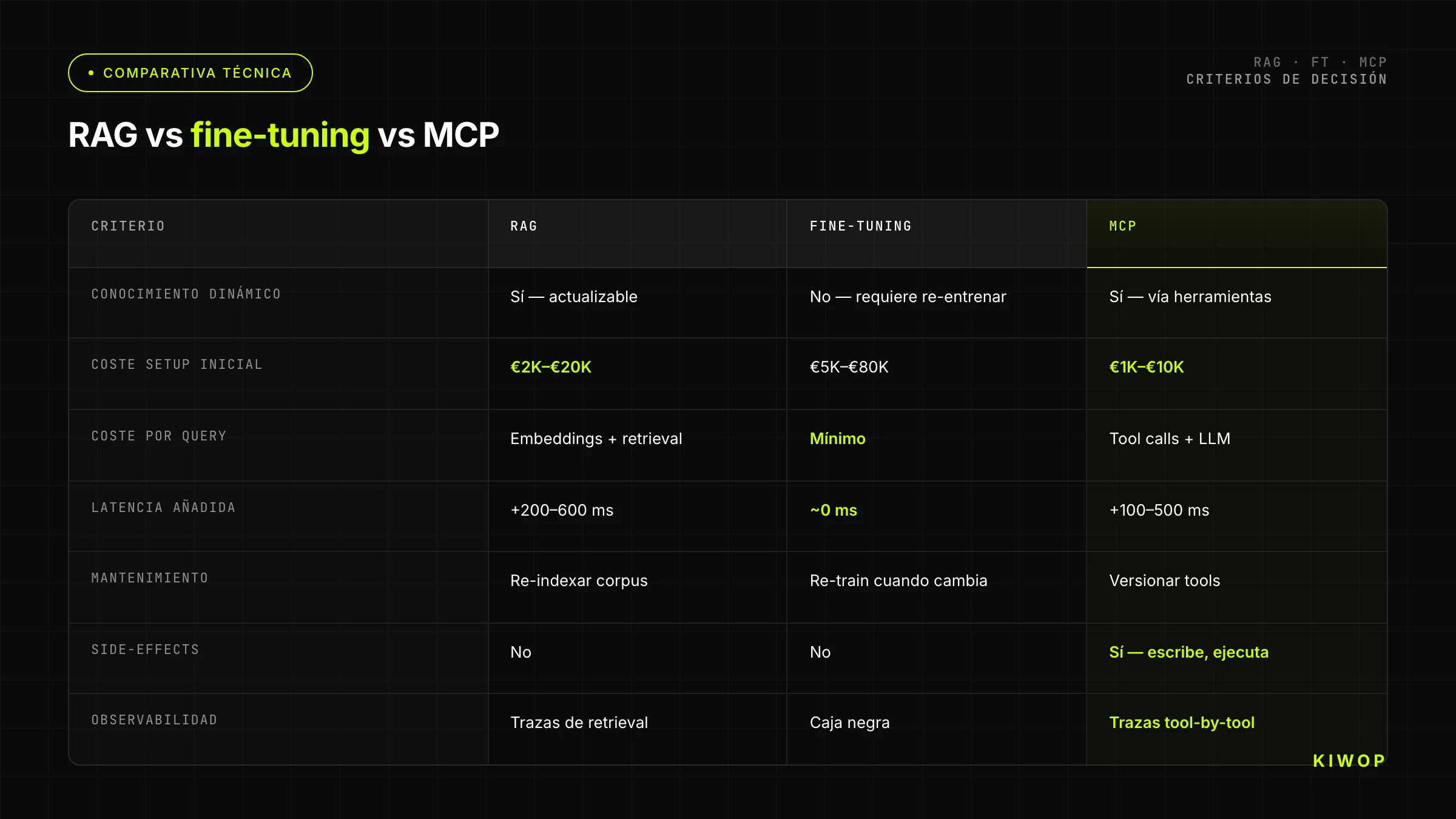
Tableau comparatif : RAG vs fine-tuning vs MCP
Arbre de décision : que choisir ?
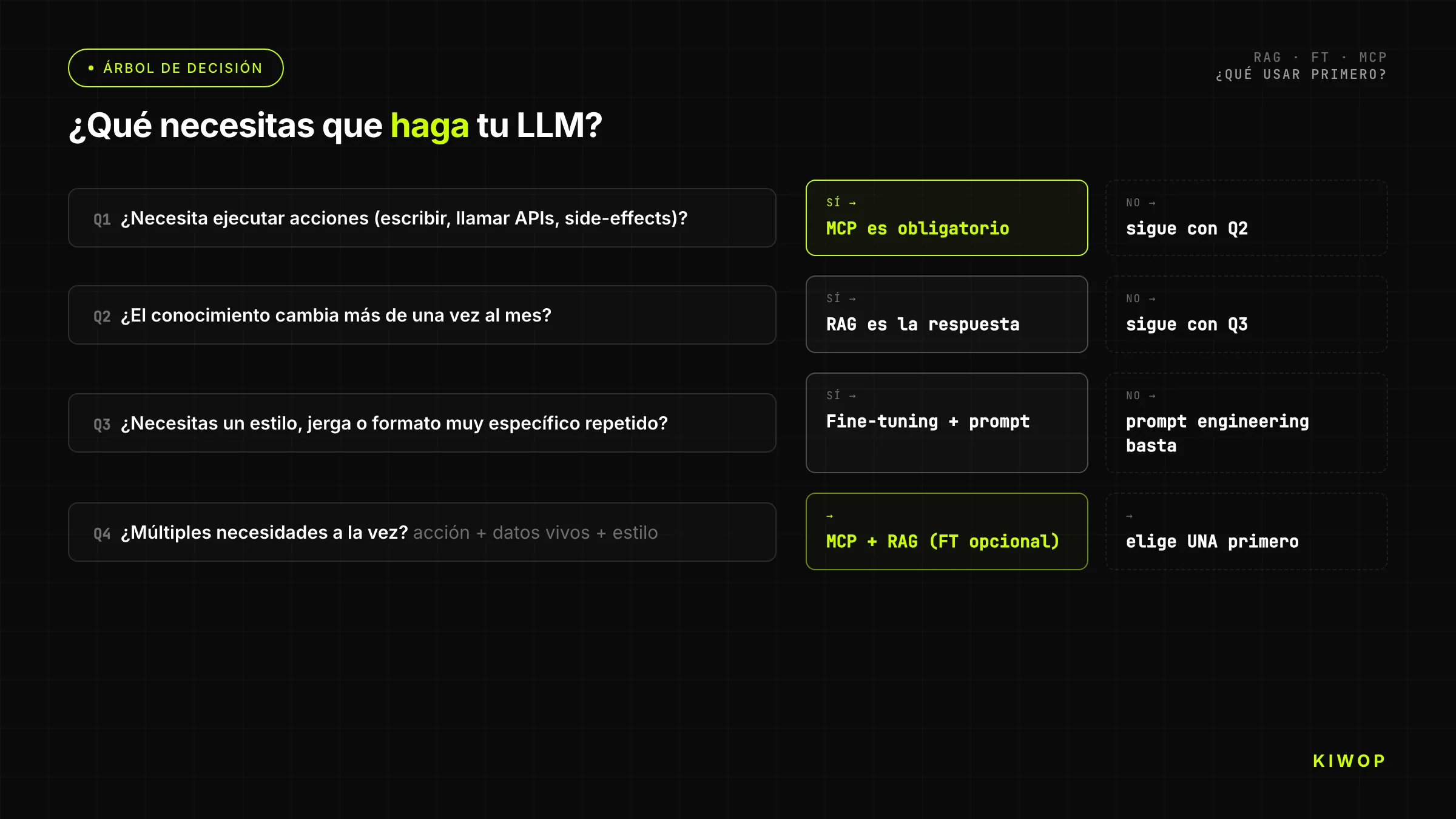
L'arbre simplifié pour les équipes qui ont besoin d'une réponse rapide :
Question 1 : l'agent a-t-il besoin d'exécuter des actions sur des systèmes externes (lire des APIs en temps réel, écrire des données, invoquer des processus) ?
- Oui → vous avez besoin de MCP. Avez-vous aussi besoin de connaissance documentaire ? Ajoutez RAG. Continuez l'arbre sur les autres dimensions.
- Non → continuez.
Question 2 : le LLM a-t-il besoin de répondre sur des documents, des données ou une connaissance absente de son entraînement ou qui change fréquemment ?
- Oui → RAG est la première réponse. Le corpus a-t-il plus de 200 pages ? Confirmez que RAG scale pour votre cas. Le corpus tient-il dans la fenêtre de contexte ? Envisagez d'injecter le contexte directement sans RAG.
- Non → continuez.
Question 3 : le modèle de base produit-il des réponses dans le mauvais format/ton/style pour votre cas d'usage, et avez-vous plus de 500 exemples annotés correctement ?
- Oui → le fine-tuning est une option. Avez-vous épuisé le prompt engineering avancé ? Sinon, commencez par là.
- Non → réévaluez si le problème est vraiment de comportement du modèle ou de connaissance.
Question 4 : avez-vous les ressources et le temps pour maintenir le modèle fine-tuné tout au long du cycle de vie du modèle de base ?
- Oui → fine-tuning.
- Non → prompt engineering avancé + RAG pour la connaissance ; acceptez les limitations de comportement.
La plupart des applications LLM d'entreprise en production finissent avec RAG + MCP comme architecture de base. Le fine-tuning ajoute complexité et coût qui justifient rarement le bénéfice incrémental face à un prompt engineering bien fait.
Cas réels chez Kiwop
Nexo (SaaS multi-tenant) : MCP + RAG sélectif
Nexo est le workspace SaaS que nous construisons chez Kiwop. L'architecture complète est documentée dans le post sur l'architecture SaaS multi-tenant avec Laravel et Inertia.
L'agent Nexo a deux couches distinctes d'accès à l'information :
Couche MCP — pour les opérations transactionnelles : créer des tâches, mettre à jour des états de projet, lire des métriques du workspace du tenant, envoyer des notifications. Tout cela vit dans la base de données relationnelle du tenant et a une API interne bien définie. Monter un serveur MCP par tenant nous permet à l'agent d'opérer sur des données réelles en temps réel sans latence d'indexation.
Couche RAG sélective — pour la documentation et les notes non structurées : comptes rendus de réunion, spécifications de produit, documentation technique que les équipes uploadent dans le workspace. Ce corpus varie beaucoup entre tenants et n'a pas de structure fixe — c'est exactement le territoire de RAG. Nous utilisons Qdrant comme vector store avec partitionnement par tenant pour garantir l'isolation des données.
Fine-tuning : nous n'en avons fait aucun pour Nexo. Le modèle de base avec un system prompt bien construit couvre le comportement attendu. Le coût de maintenance d'un modèle fine-tuné pour un SaaS qui évolue chaque semaine serait prohibitif.
PA (assistant personnel) : MCP pur
L'assistant personnel PA que nous avons construit avec Claude Code, documenté en détail dans le post construisez votre PA avec Claude Code et MCP, utilise uniquement MCP stdio.
Le PA a besoin de lire et écrire Gmail, Calendar, Drive et Slack. Toute l'information vit dans des APIs bien définies avec des SDKs matures — exactement le cas d'usage optimal de MCP. Il n'y a pas de corpus de documents propriétaire à indexer (l'email se lit directement), pas de comportement à modifier (le modèle de base est suffisamment capable), et la latence est tolérable parce que les opérations sont asynchrones.
RAG ajouterait une couche de complexité inutile. Le fine-tuning ne résout aucun problème réel que nous avons. MCP pur est l'architecture la plus simple qui fonctionne — et c'est ce que nous utilisons.
Quand nous combinons les trois
Le seul cas où nous combinons RAG, MCP et fine-tuning simultanément, c'est dans des projets d'assistants pour des secteurs très spécifiques — juridique et médical, principalement — où les trois besoins sont réels :
- MCP pour accéder aux systèmes internes du client (dossiers, calendriers d'audiences, bases de données de jurisprudence propres).
- RAG sur la documentation juridique ou clinique (réglementation, protocoles, historique de cas anonymisés).
- Fine-tuning pour adapter le format de réponse à la terminologie exacte du secteur et au style communicatif interne du client.
Même dans ces cas, le fine-tuning est toujours ce que nous implémentons en dernier, après avoir épuisé RAG + prompt engineering. Et le cycle de maintenance du modèle fine-tuné est explicitement planifié et budgété dès le départ.
5 antipatterns observés en production
1. Faire du fine-tuning quand RAG suffisait
C'est l'antipatron le plus fréquent et le plus coûteux. L'équipe décide de faire du fine-tuning parce que « nous voulons que le modèle connaisse nos produits » — mais le catalogue de produits change chaque mois. Après des semaines d'annotation et d'entraînement, le modèle fine-tuné a des informations obsolètes dès le premier jour. La bonne solution dès le début était RAG avec un corpus mis à jour automatiquement.
Le signal d'alerte : si vous vous demandez « le modèle a-t-il besoin de savoir X ? » et que X est quelque chose qui change plus vite que votre cycle de ré-entraînement, la réponse est RAG, pas fine-tuning.
2. RAG sans re-ranking
Un pipeline RAG sans re-ranking récupère les top-K chunks les plus similaires vectoriellement — mais la similarité vectorielle n'est pas la même chose que la pertinence réelle pour la question concrète. Le modèle reçoit un contexte partiellement pertinent, mélange des informations correctes avec du bruit, et la qualité de réponse est médiocre.
Le re-ranking avec un cross-encoder (modèles comme bge-reranker-v2-m3 ou Cohere Rerank) ajoute 50-150 ms de latence mais peut améliorer la précision de réponse de 20-40 % selon le corpus. C'est l'un des investissements avec le meilleur ROI dans un pipeline RAG mature. Et pourtant, la majorité des implémentations que nous voyons en production ne l'ont pas.
3. MCP sans sandboxing
Un agent avec MCP peut exécuter des actions irréversibles : supprimer des enregistrements, envoyer des emails en masse, exécuter des transactions. Sans une couche de confirmation explicite pour les opérations destructives, un agent qui mal interprète une instruction peut causer des dommages réels.
Le bon pattern : distinguer entre les outils en lecture seule (que l'agent peut invoquer librement) et les outils d'écriture ou destructifs (qui nécessitent une confirmation humaine explicite avant d'être exécutés). MCP n'impose pas cela par protocole — c'est la responsabilité de l'architecture de l'agent. Nous couvrons cela dans agents IA en production : patterns et antipatterns.
4. Tout combiner « au cas où »
L'architecture la plus dangereuse que nous voyons est celle qui combine RAG + fine-tuning + MCP dès le premier jour sans cas d'usage qui justifient chaque couche. Le résultat est un système difficile à déboguer (l'erreur vient-elle du retrieval, des poids fine-tunés, ou du tool call ?), coûteux à maintenir, et avec plusieurs points de défaillance indépendants.
Le principe d'ingénierie est toujours le même : commencez avec l'architecture la plus simple qui résout le problème. Ajoutez de la complexité seulement quand il y a un problème concret qui la justifie. Une application RAG avec un bon corpus et un bon re-ranking surpasse fréquemment une architecture RAG+FT+MCP mal conçue sur tous les KPIs qui comptent.
5. Ignorer le coût de maintenance du corpus
Un système RAG en production ne se réduit pas à « j'indexe les documents une fois et c'est terminé ». Le corpus vieillit : les documents se mettent à jour, de nouveaux s'ajoutent, certains deviennent obsolètes. Sans un processus de mise à jour de l'index — idéalement automatisé — le retrieval commence à retourner un contexte obsolète et la qualité du système se dégrade silencieusement.
Le pipeline de maintenance du corpus (détection des changements, ré-indexation partielle, validation de la qualité du retrieval) est aussi important que le pipeline d'ingestion initial. Quantifiez-le dans le budget dès le premier jour, sinon le système fonctionne bien dans la démo et mal en production six mois après.
Questions fréquentes
RAG remplace-t-il le fine-tuning ?
Pas comme règle générale, mais RAG remplace le fine-tuning dans 80 % des cas où les équipes pensent en avoir besoin. Si l'objectif est que le modèle « en sache davantage », RAG est presque toujours la réponse correcte et plus maintenable. Le fine-tuning gagne quand l'objectif est que le modèle « se comporte différemment » — format, ton ou raisonnement différent — et quand vous disposez du dataset et du cycle de maintenance pour le soutenir.
Combien coûte la mise en place d'un RAG d'entreprise ?
Un RAG fonctionnel pour un corpus de 10 000 documents avec pipeline d'ingestion, vector store sur Pinecone ou Qdrant, re-ranking, et frontend basique coûte entre 2 000 et 8 000 € en développement initial (2-6 semaines d'ingénierie). Le coût mensuel opérationnel en infrastructure (vector DB + appels API d'embeddings + appels LLM) se situe généralement entre 200 et 2 000 €/mois selon le volume de requêtes. Le coût de maintenance du corpus dépend de la fréquence de mise à jour et du caractère manuel ou automatisé du processus.
Puis-je utiliser RAG et MCP en même temps ?
Oui, et c'est le pattern que nous recommandons pour la plupart des agents d'entreprise. L'agent dispose d'outils MCP pour accéder aux données transactionnelles en temps réel et d'un retriever RAG pour répondre sur les documents et la connaissance non structurée. Les deux sont invoqués à des moments différents du raisonnement et n'interfèrent pas l'un avec l'autre. En fait, un serveur MCP peut exposer le retriever RAG comme outil, rendant le pattern particulièrement propre.
OpenAI ou Anthropic pour le fine-tuning ?
Anthropic ne propose pas de fine-tuning de ses modèles à des clients externes à ce jour. Les options commerciales sont OpenAI (GPT-4o mini et GPT-4o), Google Vertex AI (Gemini Pro) et, pour les modèles open-source, des fournisseurs comme Together AI, Replicate, ou infrastructure propre. OpenAI a la plateforme de fine-tuning la plus mature et documentée du marché. Google est compétitif pour les cas d'usage dans l'écosystème GCP. Pour la plupart des nouveaux projets, si le modèle de base candidat est d'Anthropic, l'alternative au fine-tuning non disponible est de construire un RAG plus solide ou d'utiliser le prompt caching pour réduire les coûts des prompts longs.
Quelle base de données vectorielle choisir ?
Cela dépend du contexte. Si vous utilisez déjà PostgreSQL, pgvector est le point d'entrée avec le moins de friction opérationnelle. Si vous avez besoin de scaler à des millions de vecteurs avec des latences submilliseconde, Pinecone a le meilleur time-to-production. Weaviate est fort quand le corpus est très large et que vous avez besoin d'une recherche hybride (vectorielle + keyword) avec plusieurs tenants. Qdrant est open-source, rapide, et la meilleure option si vous souhaitez un contrôle total sans licence cloud. Pour la plupart des cas d'entreprise que nous gérons depuis RAG entreprise, nous commençons avec pgvector dans le même PostgreSQL du client et migrons vers Qdrant quand le volume le justifie.
Conclusion et prochaines étapes
La question n'est pas « RAG, fine-tuning ou MCP ? » — c'est « quelle dimension du problème suis-je en train de résoudre ? ». Connaissance dynamique : RAG. Comportement du modèle : fine-tuning, mais avec discernement et un plan de maintenance. Action sur les systèmes : MCP.
La plupart des applications LLM en production ont besoin de RAG + MCP comme base. Le fine-tuning est le troisième niveau que l'on ajoute seulement quand RAG + prompt engineering bien construit ne suffit pas, et quand l'équipe a la capacité réelle de soutenir le cycle de vie du modèle.
Le piège le plus coûteux est de choisir sans critère et de découvrir six mois plus tard que l'architecture ne tient pas. Nous avons vu des projets qui ont mis deux mois à faire du fine-tuning alors que RAG aurait pris deux semaines et aurait mieux fonctionné. Nous avons vu des pipelines RAG sans re-ranking qui ont été entièrement repensés après que le système soit arrivé en production et que la qualité ne soit pas acceptable.
Si votre équipe est dans ce processus de décision — en train d'évaluer si vous avez besoin de RAG, de fine-tuning, de MCP, ou d'une combinaison — c'est exactement le travail que nous faisons chez Kiwop. Nous examinons l'architecture, le cas d'usage, les ressources disponibles, et concevons le système minimal qui résout le problème avec le moindre coût de maintenance. Nos services de développement d'agents IA, RAG entreprise et intégration de LLMs sont pensés pour les équipes qui veulent arriver en production avec des décisions techniques solides, sans payer le prix d'apprendre tout depuis zéro. Écrivez-nous et nous l'évaluons ensemble.
Si ce post vous a été utile, suivez le fil avec le cluster complet : MCP, WebMCP et A2A : quel protocole choisir pour vos agents IA, agents IA en production : patterns et antipatterns et construisez votre PA avec Claude Code et MCP.


