Vom Kiwop-Team · Digitale Agentur spezialisiert auf Softwareentwicklung und angewandte Künstliche Intelligenz · Veröffentlicht am 7. Mai 2026 · Letzte Aktualisierung: 7. Mai 2026
TL;DR — RAG ist die Antwort, wenn das LLM dynamisches Wissen benötigt, das nicht in seinem Training enthalten war: interne Datenbanken, aktuelle Dokumente, Kataloge. Fine-Tuning ist die Antwort, wenn Du das Verhalten, den Stil oder die Reasoning-Domäne des Modells dauerhaft verändern musst — und das Dataset hast, um das zu rechtfertigen. MCP ist die Antwort, wenn der Agent handeln muss, nicht nur erinnern: ausführen, lesen, schreiben, APIs aufrufen. Zwei oder alle drei zu kombinieren ist häufig und in vielen Fällen die richtige Architektur. Sich ohne Abwägung für nur eine zu entscheiden ist das teuerste Antimuster, das wir in Produktion sehen.

Jede Woche erhalten wir dieselbe Frage von technischen Teams, die ihre ersten LLM-Anwendungen in Produktion entwerfen: „Bauen wir RAG auf oder machen wir lieber Fine-Tuning?". Und die ehrliche Antwort ist, dass die Frage fast immer falsch gestellt ist. RAG, Fine-Tuning und MCP sind keine Alternativen auf derselben Dimension: Sie lösen verschiedene Probleme auf verschiedenen Schichten des Stacks.
Die Verwechslung ist verständlich. Alle drei Techniken werden in Tutorials, Papers und Anbieterpitch-Decks zusammen präsentiert, als wären sie austauschbare Ansätze, um „das LLM mehr Dinge wissen zu lassen". Das sind sie nicht. Ein Team, das Fine-Tuning macht, wenn es RAG braucht, verschwendet Wochen und zehntausende Euro. Ein Team, das RAG aufbaut, wenn es MCP braucht, konstruiert ein ausgefeiltes Informationsabrufsystem, das am Ende nichts ausführen kann.
Dieser Post ist das Entscheidungs-Framework, das uns vor zwei Jahren einige Architekturzyklen erspart hätte. Er basiert auf unserer echten Erfahrung mit dem Deployment von KI-Agenten in Produktion, dem Aufbau des SaaS Nexo und dem Einrichten des persönlichen Assistenten PA auf MCP mit Claude Code. Das ist keine Theorie: Es ist das, was wir lernen, wenn etwas in Produktion versagt und wir diagnostizieren müssen, warum.
Warum ein LLM allein niemals ausreicht
Ein Sprachmodell im Reinzustand hat vier strukturelle Einschränkungen, die kein Parameteraufbau vollständig behebt.
Wissen eingefroren in der Zeit. Die Trainingsdaten haben einen Stichtag. GPT-4o hat April 2024 als Stichtag. Claude 3.5 Sonnet ebenfalls April 2024. Alles, was danach passiert ist, existiert für das Modell nicht, außer was Du in den Kontext einfügst. Wenn Deine Anwendung heutige Daten, Daten der letzten Woche oder den aktuellen Katalog von gestern benötigt, kann Dir das Modell allein nicht helfen.
Wissen, das nie da war. Modelle werden mit öffentlichen Internetdaten trainiert. Deine interne Dokumentation, Deine Verträge, Deine Support-Tickets, Deine Unternehmens-Wissensbasis: Nichts davon ist im Basismodell. Und das sollte es auch nicht sein, aus Datenschutz- wie auch Sicherheitsgründen.
Strukturelle Halluzinationen. Wenn das Modell etwas nicht weiß, sagt es das nicht immer. Manchmal erfindet es es mit derselben Überzeugung, mit der es etwas Wahres sagt. Das Problem ist nicht die Unwissenheit; es ist das falsche Vertrauen in die Unwissenheit. Die einzige echte Lösung ist, dem Modell zum Zeitpunkt der Inferenz Zugriff auf die Wahrheitsquelle zu geben.
Keine Handlungsfähigkeit. Das Modell generiert Text. Es kann Deine Datenbank nicht lesen, nicht in Dein CRM schreiben, keine E-Mail senden. Damit ein LLM in der Welt handeln kann, braucht es externe Werkzeuge. Das ist eine andere Infrastrukturschicht als Wissen.
Diese vier Einschränkungen generieren drei Lösungsfamilien: RAG für die ersten beiden, Fine-Tuning für bestimmte Fälle der zweiten (Reasoning-Domäne) und MCP für die vierte. Jede berührt eine andere Problemdimension.
Die drei Strategien, ein LLM mit Deiner Welt zu verbinden
Bevor wir ins Detail gehen, eine kurze Definition jeder Strategie, die wir dann ausbauen:
RAG (Retrieval-Augmented Generation): Das Modell erhält zum Zeitpunkt der Inferenz Dokumentenfragmente, die aus einer Vektordatenbank oder einer Suchmaschine abgerufen wurden. Das Modell ändert sich nicht; was das Modell sieht, ändert sich.
Fine-Tuning: Das Modell wird auf domänenspezifischen Daten neu trainiert, wobei seine Gewichte angepasst werden. Was das Modell bei jeder Inferenz sieht, ändert sich nicht; was das Modell ist, ändert sich.
MCP (Model Context Protocol): Der Agent hat Zugriff auf typisierte Werkzeuge — APIs, Datenbanken, externe Systeme — die er während der Generierung aufrufen kann. Das ist nicht nur Wissen; das ist Handlungsfähigkeit.
Die grundlegende Unterscheidung: RAG ist deklaratives Gedächtnis, Fine-Tuning ist prozedurales Lernen, MCP ist Handlungsfähigkeit. Die drei sind orthogonal. Sie lassen sich kombinieren, ohne dass eines das andere ersetzt.
RAG — Retrieval-Augmented Generation
Was es ist und wie es funktioniert
RAG wurde im Paper von Lewis et al. (Facebook AI Research, 2020) formalisiert und wurde zum dominanten Muster für die Verbindung von LLMs mit proprietären Wissensbasen. Die Idee ist täuschend einfach: Wenn eine Nutzerfrage eintrifft, rufst Du vor dem Modellaufruf die relevantesten Fragmente Deines Korpus ab, fügst sie als Kontext in den Prompt ein, und das Modell generiert die Antwort, verankert in diesen Quellen.
Die moderne Implementierung hat drei Komponenten:
- Ingestion-Pipeline: Dokumente werden verarbeitet, in Chunks aufgeteilt (typischerweise 512-1024 Tokens mit Überlappung), in Embeddings encodiert und in einer Vektordatenbank gespeichert (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval: Bei der Inferenz wird die Nutzerfrage in ein Embedding umgewandelt und eine Ähnlichkeitssuche (Kosinus oder Skalarprodukt) durchgeführt, um die Top-K relevantesten Chunks zu finden.
- Augmentation: Die abgerufenen Chunks werden in den System-Prompt zusammen mit der Frage eingefügt, und das Modell generiert die Antwort.
Ausgefeiltere Varianten fügen Re-Ranking hinzu (ein zweites Modell ordnet die Retrieval-Ergebnisse nach tatsächlicher Relevanz, nicht nur Vektorähnlichkeit), HyDE (Hypothetical Document Embeddings, das vor der Suche ein hypothetisches Dokument generiert) und hybrides RAG (Vektorsuche + lexikalisches BM25 kombiniert). Laut dem RAG-Survey auf arXiv von Gao et al. (2024) ist Re-Ranking der einzelne Faktor, der die Antwortqualität im Enterprise-RAG am stärksten verbessert.
Optimale Einsatzfälle
RAG glänzt genau in diesen Situationen:
- Unternehmens-Wissensbasis: interne Dokumentation, technische Handbücher, HR-Verfahren, Unternehmensrichtlinien. Der Korpus wird häufig aktualisiert; Du kannst das Modell nicht jede Woche neu trainieren.
- Kundensupport mit eigenem Produkt: Der Assistent muss Fragen zu Deinem spezifischen Produkt beantworten, nicht zu generischen Marktprodukten.
- Ad-hoc-Dokumentenanalyse: Der Nutzer lädt Verträge, Berichte oder PDFs hoch und stellt Fragen. Der Inhalt variiert in jeder Sitzung.
- Compliance und Audit: Die Antwort muss auf ein konkretes Fragment eines Quelldokuments zurückgeführt werden können — Zitat, Artikel, Klausel. RAG ist das einzige Muster, das das strukturell ermöglicht.
- Daten mit hoher Aktualisierungsfrequenz: Produktkataloge, Preise, Lagerbestände. Alles, was sich schneller ändert, als Du ein Modell aktualisieren würdest.
Bei Kiwop implementieren wir RAG als Basis des Enterprise-RAG-Systems für Kunden in den Bereichen Recht, Immobilien und Fintech, wo die Rückverfolgbarkeit zum Quelldokument nicht optional ist.
Wann RAG NICHT verwenden
RAG ist nicht die Lösung, wenn das Problem nicht Wissen, sondern Verhalten ist. Wenn das Basismodell Antworten in einem falschen Format, in einem unpassenden Sprachregister oder mit einem Reasoning-Stil produziert, der nicht zu Deiner Domäne passt — das repariert man nicht mit mehr Kontext. Ein besserer Prompt vielleicht; RAG nicht.
Es ist auch nicht die Lösung, wenn die Latenz kritisch ist. Eine typische RAG-Pipeline fügt der Gesamtlatenz 200-600ms hinzu: die Embedding-Zeit der Abfrage, das Vektorretrieval und die Prompt-Erweiterung. Für Hochfrequenz-Interfaces mit Erwartung sofortiger Antwort kann dieser Overhead inakzeptabel sein.
Und es ist nicht die Lösung, wenn der Korpus zu klein ist. Wenn Deine Dokumente komfortabel ins Kontextfenster passen (sagen wir, weniger als 50 A4-Seiten), ist das einfachere Muster, das gesamte Dokument direkt in den Kontext zu stecken. Du kannst monate-lange Datentechnik-Arbeit einsparen.
Reale Kosten: Vektordatenbank, Infrastruktur, Latenz
Ein funktionsfähiges Enterprise-RAG hat drei Kosten, die Tutorials selten quantifizieren.
Vektordatenbank: Pinecone Starter (kostenlos bis 2 GB) reicht für Prototypen. Ein mittlerer Unternehmenskorpus (50.000 Dokumente mit Embeddings von 1536 Dimensionen) liegt bei 500 MB bis 2 GB an Vektoren — das Limit wird früher als erwartet erreicht. Pinecone Standard beginnt bei 70 $/Monat. Weaviate Cloud auf dem Produktionstier ist vergleichbar. Wenn Du pgvector in Deinem bestehenden PostgreSQL nutzt, sind die Speicherkosten marginal, aber die Skalierbarkeit bei gleichzeitigen Abfragen erfordert mehr Verwaltung.
Embedding bei der Ingestion: Ein Korpus von 100.000 Chunks mit text-embedding-3-small von OpenAI (0,02 $/1M Tokens) kostet beim ersten Mal weniger als 5 $. Die eigentlichen Kosten entstehen beim Reprozessieren, wenn Du das Embedding-Modell wechselst — etwas Unvermeidliches, wenn bessere Modelle erscheinen — und bei der Infrastruktur der Ingestion-Pipeline (Worker, Queue, Deduplizierung, Versionierung).
Operative Latenz: In Produktion mit Re-Ranking eingerechnet, erwarte 400-800 ms zusätzlichen Overhead. Wenn Dein LLM ohnehin 1-2 s für Antworten braucht, kann das Gesamtergebnis an 3 s kratzen — oberhalb der Wahrnehmungsschwelle von „langsame Antwort" bei Konversationsinterfaces.
Fine-Tuning — das Modell in Deiner Domäne trainieren
Was es ist (LoRA, QLoRA, Full Fine-Tune)
Fine-Tuning bedeutet, die Gewichte eines vortrainierten Modells auf einem spezifischen Dataset anzupassen, sodass das Modell Muster, Formate oder Wissen internalisiert, die in seinem Basistraining nicht ausreichend repräsentiert sind.
Es gibt drei Hauptvarianten je nach Kosten und Kapazität:
Full Fine-Tuning: Alle Modellgewichte werden aktualisiert. Maximale Anpassungskapazität, höchste Kosten. Für Modelle mit 7B Parametern sind GPUs mit 80 GB VRAM erforderlich (mindestens zwei A100). Für Modelle mit 70B sprechen wir bereits von Clustern mit 8+ GPUs. In der Praxis ist es nur mit Referenzinstanzen für sehr spezifische Domänen sinnvoll oder mit proprietären Modellen, bei denen der Anbieter das Computing verwaltet (OpenAI Fine-Tuning API, Google Vertex AI Tuning).
LoRA (Low-Rank Adaptation): Anstatt alle Gewichte zu aktualisieren, werden Matrizen niedrigen Rangs hinzugefügt, die das Delta lernen. Die PEFT-Bibliothek von Hugging Face implementiert LoRA als Standard; laut der offiziellen PEFT-Dokumentation kann LoRA die Anzahl der trainierbaren Parameter um mehr als 10.000x reduzieren und dabei in vielen Aufgaben eine mit Full Fine-Tuning vergleichbare Qualität erhalten. Ein 7B-Modell mit LoRA trainiert auf einer GPU A10 mit 24 GB VRAM.
QLoRA: LoRA auf einem auf 4-Bit quantisierten Modell. Ermöglicht das Training von 70B-Modellen auf einer einzelnen A100 GPU mit 80 GB, auf Kosten von etwas Qualität gegenüber LoRA full-precision. Das ist die Referenzvariante für Experimente mit großen Modellen ohne Cluster-Zugang.
Die Fine-Tuning-Dokumentation von OpenAI deckt den vollständigen Prozess für ihre Modelle (GPT-4o mini, GPT-4o) ab. Das Fine-Tuning von GPT-4o mini kostet 3 $/1M Tokens beim Training und 0,30 $/1M Tokens bei der Inferenz (30% mehr als das Basismodell). Anthropic bietet kein öffentliches Fine-Tuning seiner Modelle an; Google bietet Tuning auf Gemini Pro über Vertex AI an.
Optimale Einsatzfälle
Fine-Tuning löst genau diese Probleme:
- Striktes und komplexes Ausgabeformat: Wenn das Modell JSON mit einem sehr spezifischen Schema, Code in einem unternehmenseigenen Stil oder Dokumente mit fester Struktur produzieren muss, fixiert Fine-Tuning dieses Muster besser als jede Prompt-Anweisung.
- Sehr spezifisches Sprachregister und Ton: Assistenten, die genau wie die Markenstimme des Unternehmens klingen müssen, mit eigenem Vokabular, branchenspezifischen Höflichkeitsformen oder sehr engem technischem Fachjargon.
- Reasoning in sehr spezialisierter Domäne: Medizin, Recht, spezifisches industrielles Prozess-Engineering. Das Basismodell hat allgemeines Domänenwissen; Fine-Tuning schärft es auf die Besonderheiten der eigenen Domäne.
- Reduzierte Latenz via kurze Prompts: Ein fein abgestimmtes Modell kann sich so verhalten, als hätte es einen langen System-Prompt, ohne diesen bei jedem Aufruf zu benötigen — die Gewichte internalisieren die Anweisungen bereits. Das reduziert Input-Tokens und damit Kosten und Latenz.
- Repetitive Klassifizierung und Extraktion: Wenn Du eine sehr definierte Aufgabe hast (E-Mails nach Kategorie klassifizieren, Entitäten aus Rechnungen extrahieren, Adressen normalisieren) mit Tausenden von annotierten Beispielen, übertrifft Fine-Tuning RAG und Prompt Engineering in Präzision und Konsistenz.
Wann NICHT fine-tunen
Das ist der Teil, den die meisten Projekte ignorieren.
Fine-tune nicht, um sachliches Wissen hinzuzufügen, das sich mit der Zeit ändert. Das Modell lernt das Wissen als statische Gewichte; wenn dieses Wissen veraltet, musst Du neu trainieren. RAG löst das Problem strukturell besser.
Fine-tune nicht, um Halluzinationen durch fehlendes Wissen zu beheben. Wenn das Modell halluziniert, weil es etwas nicht weiß, kann das Fine-Tuning mit mehr Beispielen dieses Wissens die Halluzination bei Trainingsbeispielen reduzieren, eliminiert sie aber nicht strukturell — und kann sie in nicht gesehenen Fällen sogar erhöhen. Die richtige Lösung ist RAG mit Quellanker.
Fine-tune nicht ohne Qualitätsdataset. Das reale Minimum, um eine Verbesserung zu sehen, liegt zwischen 100 und 1.000 hochwertigen, korrekt formatierten Beispielen. „Wir haben 50 Beispiele" reicht fast nie. Und die Beispiele müssen die tatsächliche Fallverteilung abdecken, nicht nur Erfolgsfälle.
Fine-tune nicht als erstes Experiment. Vor dem Fine-Tuning schöpfe fortgeschrittenes Prompt Engineering aus (Few-Shot-Beispiele, Chain-of-Thought, detaillierte System-Prompts). In den meisten Fällen liefert ein gut konstruierter Prompt 80-90% des Ergebnisses bei 0% der Fine-Tuning-Kosten.
Reale Kosten (Computing, Dataset, Wartung)
Die Kosten haben drei Dimensionen, die kaum jemand gemeinsam kalkuliert.
Trainingskosten: Fine-Tuning von GPT-4o mini mit 1.000 Beispielen von 500 Tokens = ca. 1-3 $. Fine-Tuning von GPT-4o mit demselben Dataset = ca. 30-90 $. LoRA auf einem 7B Open-Source-Modell auf einem A10G auf AWS = 2-8 $/Stunde, ein typischer Lauf von 2-6 Stunden = 10-50 $. LoRA auf einem 70B auf einem A100-Cluster = 20-80 $/Stunde. Das sind Kosten des ersten Laufs; Experimente (Hyperparameter ausprobieren, Fehler überprüfen, neu trainieren) multiplizieren das leicht um den Faktor 3-5.
Datasetkosten: Die menschliche Annotation von Qualitätsbeispielen ist die größte versteckte Koste. Wenn Du 1.000 Beispiele medizinischer Klassifikation mit Facharzt-Annotation brauchst, können die Annotationskosten die Computing-Kosten um das 10-Fache übersteigen. Für viele Projekte ist das Dataset der eigentliche Engpass, nicht das Training.
Wartungskosten: Ein fein abgestimmtes Modell altert. Die Domäne ändert sich, Grenzfälle tauchen auf, das Basismodell wird aktualisiert (und das Fine-Tuning migriert nicht automatisch). Jeder Aktualisierungszyklus des Basismodells bedeutet potenziell, das Fine-Tuning zu wiederholen. Das macht Fine-Tuning zu einem langfristigen ML-Engineering-Engagement, nicht einem punktuellen Projekt.
MCP — Werkzeuge und Handlungsfähigkeit
Kurze Zusammenfassung
MCP (Model Context Protocol) ist der offene Standard — von Anthropic im November 2024 veröffentlicht und im Dezember 2025 an die Linux Foundation gespendet — zur Verbindung von LLM-Agenten mit externen Werkzeugen. Wir behandeln seine vollständige Architektur, einschließlich des Vergleichs mit WebMCP und A2A, im Post MCP, WebMCP und A2A: Welches Protokoll für Deine KI-Agenten wählen.
Die grundlegende Architektur: Ein MCP-Client (der Agent oder sein Host) verbindet sich mit einem oder mehreren MCP-Servern, entdeckt deren Tools über einen JSON-RPC-Handshake und ruft sie mit typisierten Parametern während der Generierung auf. Die Tools können alles tun, was eine API tun kann: Datenbanken lesen und schreiben, externe APIs aufrufen, Code ausführen, E-Mails senden, Dateien ändern.
Mit mehr als 10.000 öffentlichen MCP-Servern und 97 Millionen SDK-Downloads pro Monat ist MCP heute der De-facto-Standard für Agenten-Werkzeuge.
Wann MCP statt RAG verwenden
Die richtige Frage ist nicht „MCP oder RAG", sondern „Ist das Problem Wissen oder Handlung?".
Verwende MCP, wenn die Antwort das Lesen von Echtzeitdaten erfordert: Wenn der Nutzer fragt „Wie viele Einheiten von Produkt X sind noch auf Lager?", liegt die Antwort gerade jetzt in Deinem ERP, nicht in einem drei Tage alten indizierten Dokument. RAG mit aktualisiertem Korpus könnte funktionieren, aber MCP ist direkter: Der Agent ruft das Tool get_inventory(product_id="X") auf und erhält die exakte Antwort ohne Indexierungslatenz.
Verwende MCP, wenn die Antwort Schreiben oder Handeln erfordert: Einen Ticket erstellen, eine Benachrichtigung senden, einen Datensatz aktualisieren, einen Workflow genehmigen. Das ist niemals RAG-Territorium — RAG liest nur.
Verwende MCP, wenn die Wahrheitsquelle bereits eine API hat: Wenn Dein System bereits eine gut definierte API hat, ist es häufig einfacher, einen MCP-Server darüber zu bauen, als eine Ingestion- und Embedding-Pipeline mit Vektorstore zu errichten.
Verwende MCP, wenn die Daten strukturiert und relational sind: Abfragen mit Joins, Aggregationen oder komplexen Filtern über relationale Daten leben besser in SQL via einem MCP-Server als in semantischer Suche über Text-Chunks.
In unserer Architektur für den LLM-Integrationsdienst ist das Standardmuster, das wir empfehlen: MCP für den Zugriff auf Transaktionsdaten + RAG für Dokumentation und unstrukturiertes Wissen. Beide koexistieren ohne Konflikte.
Einschränkungen
MCP fügt die Latenz des Tool-Aufrufs hinzu (ein HTTP- oder stdin/stdout-Roundtrip pro Werkzeug). In Agenten, die viele Tools verketten, summiert sich die Wartezeit. Und die Beobachtbarkeit eines Agenten mit Tools ist substanziell komplexer als die eines einfachen LLM-Aufrufs: Du brauchst Tracing von Tool-Aufrufen, Logging von Parametern und Ergebnissen und Fehlerbehandlung in jedem Werkzeug. Wir behandeln diese Muster im Detail in KI-Agenten in Produktion: Muster und Antimuster.
MCP verändert auch nicht die Reasoning-Fähigkeiten des Modells. Wenn das Basismodell in Deiner Domäne schlecht reasont, behebt das Hinzufügen von Tools das nicht. Tools verstärken, was das Modell bereits kann; sie korrigieren nicht, was es falsch macht.
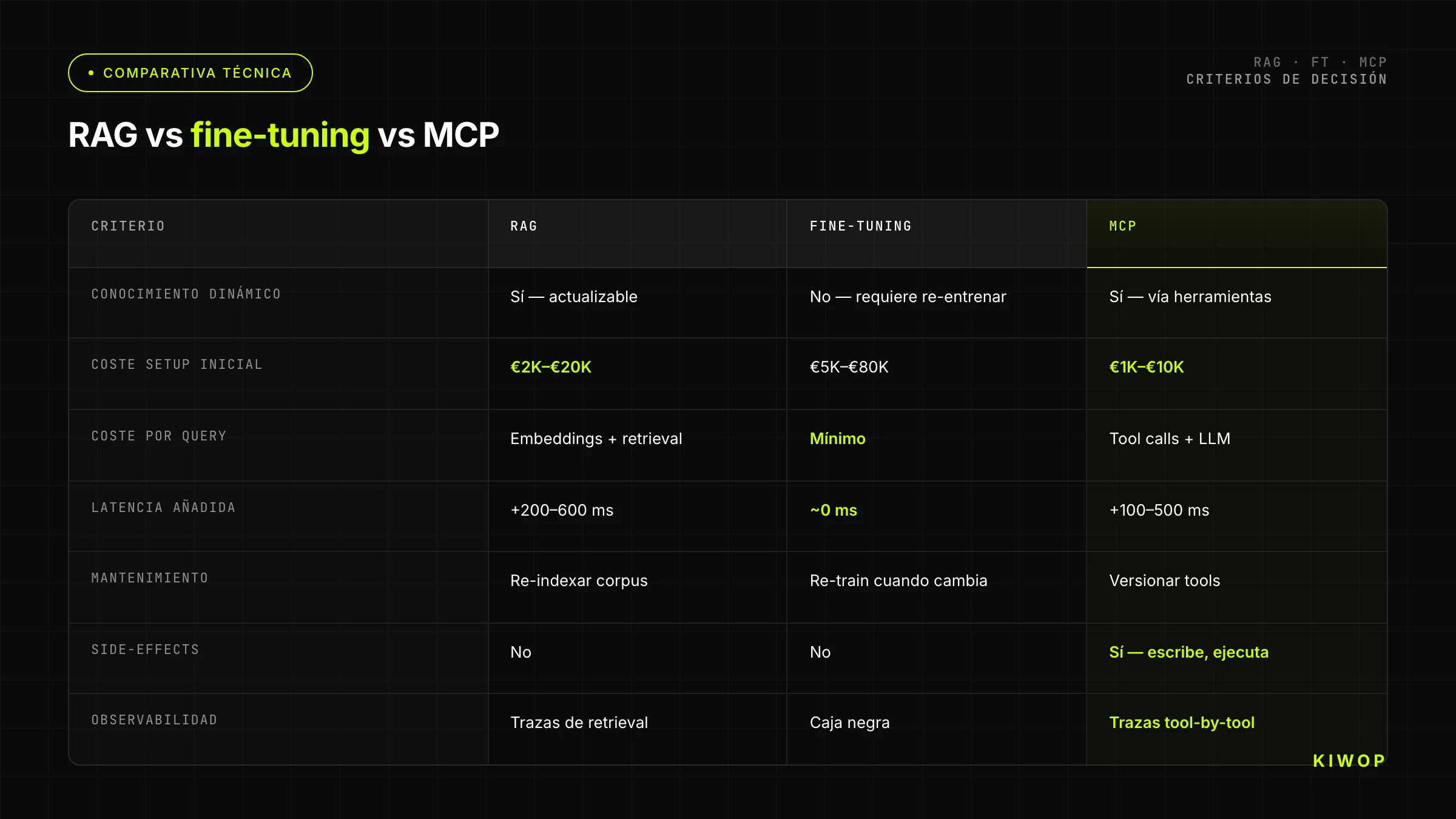
Vergleichstabelle: RAG vs. Fine-Tuning vs. MCP
Entscheidungsbaum: Was verwenden?
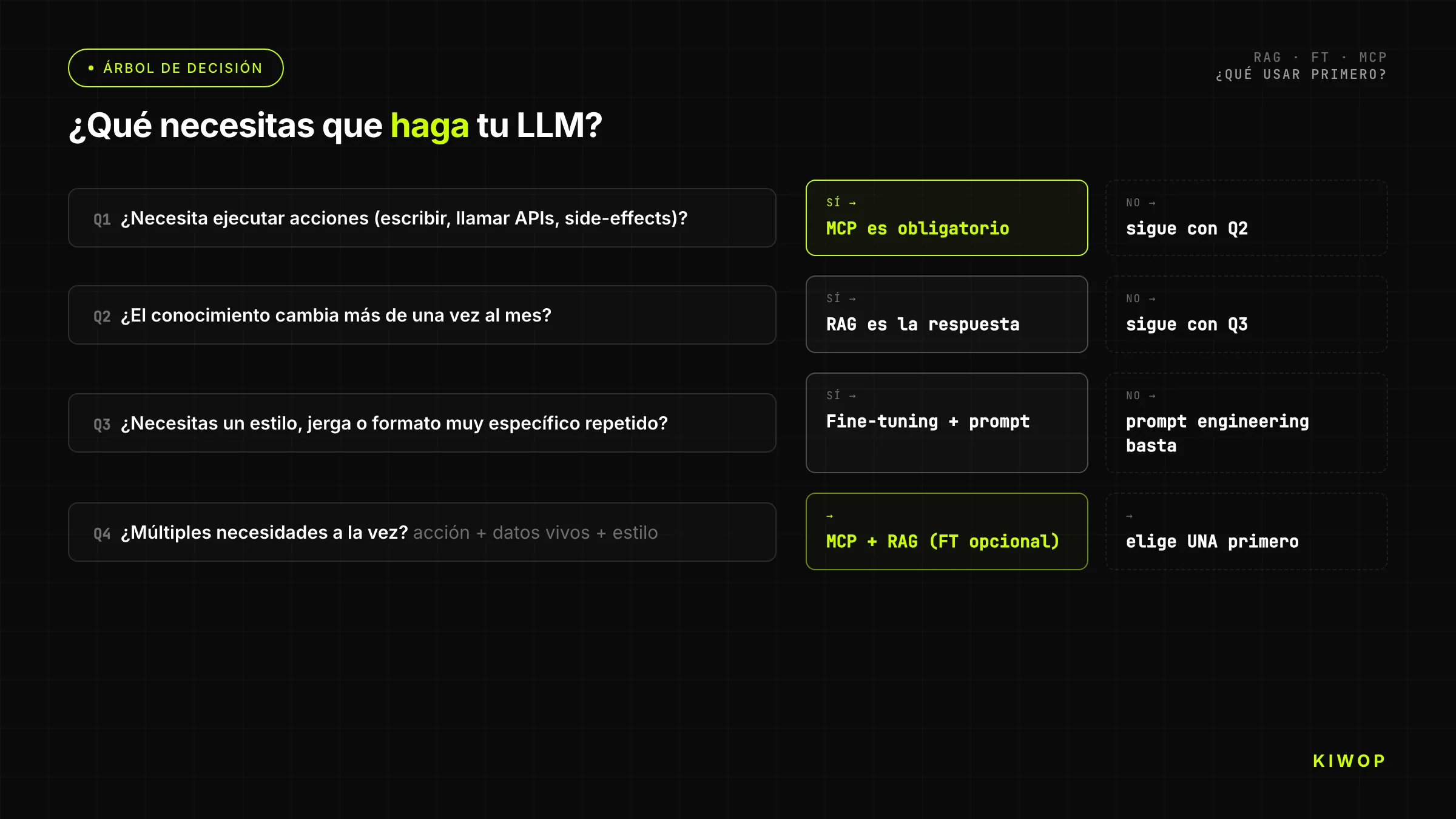
Der vereinfachte Baum für Teams, die eine schnelle Antwort brauchen:
Frage 1: Muss der Agent Aktionen auf externen Systemen ausführen (APIs in Echtzeit lesen, Daten schreiben, Prozesse aufrufen)?
- Ja → Du brauchst MCP. Brauchst Du auch Wissen aus Dokumenten? Füge RAG hinzu. Gehe den Baum für die anderen Dimensionen weiter.
- Nein → Weiter.
Frage 2: Muss das LLM über Dokumente, Daten oder Wissen antworten, das nicht in seinem Training war oder sich häufig ändert?
- Ja → RAG ist die erste Antwort. Hat der Korpus mehr als 200 Seiten? Bestätige, dass RAG für Deinen Fall skaliert. Passt der Korpus ins Kontextfenster? Erwäge, den Kontext direkt ohne RAG einzufügen.
- Nein → Weiter.
Frage 3: Produziert das Basismodell Antworten im falschen Format/Ton/Stil für Deinen Anwendungsfall, und hast Du mehr als 500 korrekt annotierte Beispiele?
- Ja → Fine-Tuning ist eine Option. Hast Du fortgeschrittenes Prompt Engineering ausgeschöpft? Wenn nicht, fang damit an.
- Nein → Überprüfe erneut, ob das Problem wirklich Modellverhalten oder Wissen ist.
Frage 4: Hast Du Ressourcen und Zeit, um das Fine-Tuned-Modell über den Lebenszyklus des Basismodells zu pflegen?
- Ja → Fine-Tuning.
- Nein → Fortgeschrittenes Prompt Engineering + RAG für Wissen; akzeptiere die Verhaltenseinschränkungen.
Die meisten Enterprise-LLM-Anwendungen in Produktion enden mit RAG + MCP als Basisarchitektur. Fine-Tuning fügt Komplexität und Kosten hinzu, die den inkrementellen Vorteil gegenüber gut gemachtem Prompt Engineering selten rechtfertigen.
Reale Fälle bei Kiwop
Nexo (Multi-Tenant-SaaS): MCP + selektives RAG
Nexo ist der Workspace-SaaS, den wir bei Kiwop bauen. Die vollständige Architektur ist im Post über die Multi-Tenant-SaaS-Architektur mit Laravel und Inertia dokumentiert.
Der Nexo-Agent hat zwei verschiedene Informationszugangsschichten:
MCP-Schicht — für Transaktionsoperationen: Aufgaben erstellen, Projektstatus aktualisieren, Workspace-Metriken des Tenants lesen, Benachrichtigungen senden. All das lebt in der relationalen Datenbank des Tenants und hat eine gut definierte interne API. Einen MCP-Server pro Tenant aufzusetzen ermöglicht dem Agenten, auf echte Daten in Echtzeit ohne Indexierungslatenz zu operieren.
Selektive RAG-Schicht — für Dokumentation und unstrukturierte Notizen: Besprechungsprotokolle, Produktspezifikationen, technische Dokumentation, die Teams in den Workspace hochladen. Dieser Korpus variiert stark zwischen Tenants und hat keine feste Struktur — das ist genau RAG-Territorium. Wir verwenden Qdrant als Vektorstore mit Partitionierung pro Tenant zur Garantie der Datenisolierung.
Fine-Tuning: Wir haben keines für Nexo gemacht. Das Basismodell mit gut konstruiertem System-Prompt deckt das erwartete Verhalten ab. Die Wartungskosten eines Fine-Tuned-Modells für einen SaaS, der sich wöchentlich weiterentwickelt, wären prohibitiv.
PA (Persönlicher Assistent): Reines MCP
Der persönliche Assistent PA, den wir mit Claude Code gebaut haben und der im Detail im Post Baue Deinen PA mit Claude Code und MCP dokumentiert ist, verwendet nur MCP stdio.
Der PA muss Gmail, Calendar, Drive und Slack lesen und schreiben. Alle Informationen leben in gut definierten APIs mit reifen SDKs — genau der optimale Anwendungsfall für MCP. Es gibt keinen proprietären Dokumentenkorpus zu indexieren (E-Mails werden direkt gelesen), kein Verhalten zu ändern (das Basismodell ist ausreichend fähig) und die Latenz ist tolerierbar, weil die Operationen asynchron sind.
RAG würde eine unnötige Komplexitätsschicht hinzufügen. Fine-Tuning löst kein reales Problem, das wir haben. Reines MCP ist die einfachste Architektur, die funktioniert — und das ist es, was wir verwenden.
Wann wir alle drei kombinieren
Der einzige Fall, in dem wir RAG, MCP und Fine-Tuning gleichzeitig kombinieren, sind Projekte von Assistenten für sehr spezifische Sektoren — hauptsächlich Recht und Medizin — wo alle drei Bedürfnisse real sind:
- MCP für den Zugriff auf interne Systeme des Kunden (Akten, Verhandlungskalender, eigene Jurisprudenzdatenbanken).
- RAG über rechtliche oder klinische Dokumentation (Normen, Protokolle, anonymisierte Fallhistorien).
- Fine-Tuning zur Anpassung des Antwortformats an die genaue Fachterminologie des Sektors und den internen Kommunikationsstil des Kunden.
Selbst in diesen Fällen ist Fine-Tuning immer das Letzte, was wir implementieren, nachdem wir RAG + Prompt Engineering ausgeschöpft haben. Und der Wartungszyklus des Fine-Tuned-Modells ist explizit von Anfang an geplant und budgetiert.
5 Antimuster, die wir in Produktion sehen
1. Fine-Tunen, wenn RAG ausgereicht hätte
Das ist das häufigste und teuerste Antimuster. Das Team entscheidet sich für Fine-Tuning, weil es „das Modell seine Produkte kennen lassen will" — aber der Produktkatalog ändert sich monatlich. Nach Wochen der Annotation und des Trainings hat das Fine-Tuned-Modell vom ersten Tag an veraltete Informationen. Die von Anfang an richtige Lösung war RAG mit automatisch aktualisiertem Korpus.
Das Warnsignal: Wenn Du Dich fragst „Muss das Modell X wissen?" und X alles ist, was sich schneller ändert als Dein Neu-Trainierungszyklus, lautet die Antwort RAG, nicht Fine-Tuning.
2. RAG ohne Re-Ranking
Eine RAG-Pipeline ohne Re-Ranking ruft die Top-K vektoriell ähnlichsten Chunks ab — aber Vektorähnlichkeit ist nicht dasselbe wie echte Relevanz für die konkrete Frage. Das Modell erhält teilweise relevanten Kontext, mischt korrekte Informationen mit Rauschen, und die Antwortqualität ist mittelmäßig.
Re-Ranking mit einem Cross-Encoder (Modelle wie bge-reranker-v2-m3 oder Cohere Rerank) fügt 50-150 ms Latenz hinzu, kann aber die Antwortpräzision je nach Korpus um 20-40% verbessern. Es ist eine der investitionseffizientesten Maßnahmen in einer reifen RAG-Pipeline. Und dennoch haben die meisten Implementierungen, die wir in Produktion sehen, es nicht.
3. MCP ohne Sandboxing
Ein Agent mit MCP kann irreversible Aktionen ausführen: Datensätze löschen, Massen-E-Mails senden, Transaktionen ausführen. Ohne eine explizite Bestätigungsschicht für destruktive Operationen kann ein Agent, der eine Anweisung falsch interpretiert, echten Schaden anrichten.
Das richtige Muster: Zwischen Read-Only-Tools (die der Agent frei aufrufen kann) und Schreib- oder destruktiven Tools (die explizite menschliche Bestätigung vor der Ausführung erfordern) unterscheiden. MCP erzwingt das nicht auf Protokollebene — das liegt in der Verantwortung der Agentenarchitektur. Wir behandeln das in KI-Agenten in Produktion: Muster und Antimuster.
4. Alles „für alle Fälle" kombinieren
Die gefährlichste Architektur, die wir sehen, ist die, die RAG + Fine-Tuning + MCP ab Tag eins ohne Anwendungsfälle kombiniert, die jede Schicht rechtfertigen. Das Ergebnis ist ein System, das schwer zu debuggen ist (Kommt der Fehler aus dem Retrieval, den Fine-Tuned-Gewichten oder dem Tool-Aufruf?), teuer zu warten und mit mehreren unabhängigen Fehlerpunkten.
Das Engineering-Prinzip ist immer dasselbe: Beginne mit der einfachsten Architektur, die das Problem löst. Füge Komplexität nur hinzu, wenn es ein konkretes Problem gibt, das sie rechtfertigt. Eine RAG-Anwendung mit gutem Korpus und gutem Re-Ranking übertrifft häufig eine schlecht entworfene RAG+FT+MCP-Architektur in allen KPIs, die zählen.
5. Die Kosten der Korpuspflege ignorieren
Ein RAG-System in Produktion ist nicht „ich indexiere die Dokumente einmal und das war's". Der Korpus altert: Dokumente werden aktualisiert, neue kommen hinzu, einige werden obsolet. Wenn es keinen Aktualisierungsprozess für den Index gibt — idealerweise automatisiert — beginnt das Retrieval, veralteten Kontext zurückzugeben, und die Systemqualität degradiert still und leise.
Die Korpuspflege-Pipeline (Änderungserkennung, partielles Re-Indexieren, Qualitätsvalidierung des Retrievals) ist genauso wichtig wie die initiale Ingestion-Pipeline. Kalkuliere sie von Tag eins ins Budget, oder das System funktioniert gut im Demo und schlecht in der Produktion sechs Monate später.
Häufig gestellte Fragen
Ersetzt RAG Fine-Tuning?
Nicht als allgemeine Regel, aber RAG ersetzt Fine-Tuning in 80% der Fälle, in denen Teams glauben, Fine-Tuning zu brauchen. Wenn das Ziel ist, dass das Modell „mehr Dinge weiß", ist RAG fast immer die richtige und wartbarere Antwort. Fine-Tuning gewinnt, wenn das Ziel ist, dass das Modell „sich anders verhält" — anderes Format, Ton oder Reasoning — und wenn Du das Dataset und den Wartungszyklus hast, um das aufrechtzuerhalten.
Was kostet ein Enterprise-RAG-Aufbau?
Ein funktionsfähiges RAG für einen Korpus von 10.000 Dokumenten mit Ingestion-Pipeline, Vektorstore in Pinecone oder Qdrant, Re-Ranking und einfachem Frontend kostet zwischen 2.000 und 8.000 € in der initialen Entwicklung (2-6 Wochen Engineering). Die monatlichen operativen Infrastrukturkosten (Vektor-DB + Embedding-API-Aufrufe + LLM-Aufrufe) liegen je nach Abfragevolumen typischerweise zwischen 200 und 2.000 €/Monat. Die Kosten der Korpuspflege hängen davon ab, wie häufig er aktualisiert wird und ob der Prozess manuell oder automatisiert ist.
Kann ich RAG und MCP gleichzeitig verwenden?
Ja, und es ist das Muster, das wir für die meisten Enterprise-Agenten empfehlen. Der Agent hat MCP-Tools für den Zugriff auf Transaktionsdaten in Echtzeit und einen RAG-Retriever für Antworten über Dokumente und unstrukturiertes Wissen. Die beiden werden zu verschiedenen Zeitpunkten des Reasonings aufgerufen und stören sich nicht gegenseitig. In der Tat kann ein MCP-Server den RAG-Retriever als Tool exponieren, was das Muster besonders sauber macht.
OpenAI oder Anthropic für Fine-Tuning?
Anthropic bietet heute kein Fine-Tuning seiner Modelle für externe Kunden an. Die kommerziellen Optionen sind OpenAI (GPT-4o mini und GPT-4o), Google Vertex AI (Gemini Pro) und für Open-Source-Modelle Anbieter wie Together AI, Replicate oder eigene Infrastruktur. OpenAI hat die reifste und am besten dokumentierte Fine-Tuning-Plattform auf dem Markt. Google ist wettbewerbsfähig für Anwendungsfälle im GCP-Ökosystem. Für die meisten neuen Projekte, wenn das Kandidatenmodell von Anthropic ist, ist die Alternative zum nicht verfügbaren Fine-Tuning, robusteres RAG zu bauen oder Prompt Caching zu nutzen, um die Kosten langer Prompts zu reduzieren.
Welche Vektordatenbank wählen?
Kommt auf den Kontext an. Wenn Du bereits PostgreSQL verwendest, ist pgvector der Einstiegspunkt mit dem geringsten operativen Aufwand. Wenn Du auf Millionen von Vektoren mit Submillisekunden-Latenz skalieren musst, hat Pinecone die beste Time-to-Production. Weaviate ist stark, wenn der Korpus sehr groß ist und Du hybride Suche (vektoriell + Keyword) mit mehreren Tenants brauchst. Qdrant ist Open-Source, schnell und die beste Option, wenn Du vollständige Kontrolle ohne Cloud-Lizenz willst. Für die meisten Enterprise-Fälle, die wir über Enterprise-RAG betreuen, beginnen wir mit pgvector im bestehenden PostgreSQL des Kunden und migrieren zu Qdrant, wenn das Volumen es rechtfertigt.
Fazit und nächste Schritte
Die Frage ist nicht „RAG, Fine-Tuning oder MCP?" — sie ist „Welche Dimension des Problems löse ich?". Dynamisches Wissen: RAG. Modellverhalten: Fine-Tuning, aber mit Kriterium und Wartungsplan. Handlung auf Systemen: MCP.
Die meisten LLM-Anwendungen in Produktion brauchen RAG + MCP als Basis. Fine-Tuning ist die dritte Ebene, die nur hinzugefügt wird, wenn RAG + gut konstruiertes Prompt Engineering nicht ausreicht, und wenn das Team die reale Kapazität hat, den Lebenszyklus des Modells zu unterhalten.
Die teuerste Falle ist, ohne Kriterien zu wählen und dann sechs Monate später zu entdecken, dass die Architektur nicht trägt. Wir haben Projekte gesehen, die zwei Monate Fine-Tuning benötigten, als RAG zwei Wochen gebraucht und besser funktioniert hätte. Wir haben RAG-Pipelines ohne Re-Ranking gesehen, die vollständig neu entworfen werden mussten, nachdem das System in Produktion ging und die Qualität nicht akzeptabel war.
Wenn Dein Team in diesem Entscheidungsprozess ist — bewertet, ob Ihr RAG, Fine-Tuning, MCP oder eine Kombination davon braucht — ist das genau die Arbeit, die wir bei Kiwop machen. Wir überprüfen die Architektur, den Anwendungsfall, die verfügbaren Ressourcen und entwerfen das minimale System, das das Problem mit den geringsten Wartungskosten löst. Unsere Dienste für Entwicklung von KI-Agenten, Enterprise-RAG und LLM-Integration sind für Teams gedacht, die mit soliden technischen Entscheidungen in Produktion gehen wollen, ohne den Preis zu zahlen, alles von Grund auf zu lernen. Schreib uns und wir bewerten es gemeinsam.
Wenn Dir der Post nützlich war, folge dem Faden mit dem vollständigen Cluster: MCP, WebMCP und A2A: Welches Protokoll für Deine KI-Agenten wählen, KI-Agenten in Produktion: Muster und Antimuster und Baue Deinen PA mit Claude Code und MCP.


