Pela equipa da Kiwop · Agência Digital especializada em Desenvolvimento de Software e Inteligência Artificial aplicada · Publicado a 7 de maio de 2026 · Última atualização: 7 de maio de 2026
TL;DR — RAG é a resposta quando o LLM precisa de conhecimento dinâmico que não esteve no seu treino: bases de dados internas, documentos atualizados, catálogos. Fine-tuning é a resposta quando precisas de mudar o comportamento, o estilo ou o domínio de raciocínio do modelo de forma persistente, e tens o dataset para o justificar. MCP é a resposta quando o agente precisa de agir, não apenas de recordar: executar, ler, escrever, chamar APIs. Combinar dois ou os três é frequente e, em muitos casos, a arquitetura correta. Escolher apenas um sem avaliar os outros é o antipadrão mais caro que vemos em produção.

Cada semana recebemos a mesma pergunta de equipas técnicas que estão a desenhar as suas primeiras aplicações LLM em produção: "Montamos RAG ou antes fazemos fine-tuning?". E a resposta honesta é que a pergunta está quase sempre mal formulada. RAG, fine-tuning e MCP não são alternativas na mesma dimensão: resolvem problemas distintos em camadas distintas do stack.
A confusão é compreensível. As três técnicas são apresentadas juntas em tutoriais, papers e pitch decks de fornecedores como se fossem abordagens intercambiáveis para "fazer o LLM saber mais coisas". Não são. Uma equipa que faz fine-tuning quando precisa de RAG desperdiça semanas e dezenas de milhares de euros. Uma equipa que monta RAG quando precisa de MCP constrói um sistema de recuperação de informação sofisticado que no final não consegue executar nada.
Este post é o framework de decisão que nos teria poupado vários ciclos de arquitetura há dois anos. Está baseado na nossa experiência real a implementar agentes IA em produção, a construir o SaaS Nexo, e a montar o assistente pessoal PA sobre MCP com Claude Code. Não é teoria: é o que aprendemos quando algo falha em produção e temos de diagnosticar porquê.
Porque é que um LLM sozinho nunca é suficiente
Um modelo de linguagem no estado puro tem quatro limitações estruturais que nenhum aumento de parâmetros resolve completamente.
Conhecimento congelado no tempo. Os dados de treino têm uma data de corte. GPT-4o tem corte em abril de 2024. Claude 3.5 Sonnet em abril de 2024. Tudo o que aconteceu depois não existe para o modelo, exceto o que lhe colocares no contexto. Se a tua aplicação precisa de dados de hoje, da semana passada, ou do catálogo atualizado de ontem, o modelo sozinho não te consegue ajudar.
Conhecimento que nunca lá esteve. Os modelos são treinados com dados públicos da internet. A tua documentação interna, os teus contratos, os teus tickets de suporte, a tua base de conhecimento corporativa: nada disso está no modelo base. E não deveria lá estar, por razões de privacidade tanto quanto de segurança.
Alucinações estruturais. Quando o modelo não sabe algo, nem sempre o diz. Por vezes inventa-o com a mesma confiança com que diz algo verdadeiro. O problema não é a ignorância; é a falsa confiança na ignorância. A única solução real é dar ao modelo acesso à fonte de verdade no momento da inferência.
Sem capacidade de ação. O modelo gera texto. Não consegue ler a tua base de dados, não consegue escrever no teu CRM, não consegue enviar um email. Para que um LLM atue no mundo, precisa de ferramentas externas. Isso é uma camada de infraestrutura diferente do conhecimento.
Estas quatro limitações geram três famílias de soluções: RAG para as duas primeiras, fine-tuning para certos casos da segunda (domínio de raciocínio), e MCP para a quarta. Cada uma toca uma dimensão distinta do problema.
As três estratégias para ligar um LLM ao teu mundo
Antes de entrar em detalhe, uma definição curta de cada uma que depois expandiremos:
RAG (Retrieval-Augmented Generation): o modelo recebe, no momento da inferência, fragmentos de documentos recuperados de uma base de dados vetorial ou de um motor de pesquisa. Não muda o modelo; muda o que o modelo vê.
Fine-tuning: o modelo é re-treinado sobre dados específicos do domínio, ajustando os seus pesos. Não muda o que o modelo vê em cada inferência; muda o que o modelo é.
MCP (Model Context Protocol): o agente tem acesso a ferramentas tipadas — APIs, bases de dados, sistemas externos — que pode invocar durante a geração. Não é apenas conhecimento; é capacidade de ação.
A distinção fundamental: RAG é memória declarativa, fine-tuning é aprendizagem processual, MCP é agência. Os três são ortogonais. Podem combinar-se sem que um substitua o outro.
RAG — Retrieval-Augmented Generation
O que é e como funciona
RAG foi formalizado no paper de Lewis et al. (Facebook AI Research, 2020) e tornou-se o padrão dominante para ligar LLMs a bases de conhecimento proprietárias. A ideia é enganosamente simples: quando chega uma pergunta do utilizador, antes de chamar o modelo, recuperas os fragmentos mais relevantes do teu corpus, inseres-os no prompt como contexto, e o modelo gera a resposta ancorada nessas fontes.
A implementação moderna tem três componentes:
- Pipeline de ingestão: os documentos são processados, divididos em chunks (tipicamente 512-1024 tokens com sobreposição), codificados em embeddings, e armazenados numa base de dados vetorial (Pinecone, Weaviate, pgvector, Qdrant).
- Retrieval: na inferência, a pergunta do utilizador é convertida em embedding e faz-se pesquisa por similaridade (cosseno ou produto escalar) para recuperar os top-K chunks mais relevantes.
- Augmentation: os chunks recuperados são inseridos no prompt do sistema juntamente com a pergunta, e o modelo gera a resposta.
As variantes mais sofisticadas acrescentam re-ranking (um segundo modelo ordena os resultados do retrieval por relevância real, não apenas similaridade vetorial), HyDE (Hypothetical Document Embeddings, que gera um documento hipotético antes de pesquisar), e RAG híbrido (pesquisa vetorial + BM25 léxico combinados). Segundo o survey sobre RAG do arXiv de Gao et al. (2024), o re-ranking é o fator individual que mais melhora a qualidade de resposta em RAG empresarial.
Casos de uso ótimos
RAG brilha exatamente nestas situações:
- Base de conhecimento empresarial: documentação interna, manuais técnicos, procedimentos de RH, políticas de empresa. O corpus atualiza-se frequentemente; não podes re-treinar o modelo todas as semanas.
- Suporte ao cliente com produto próprio: o assistente precisa de responder sobre o teu produto específico, não sobre produtos genéricos do mercado.
- Análise de documentos ad-hoc: o utilizador faz upload de contratos, relatórios, ou PDFs e faz perguntas. O conteúdo varia em cada sessão.
- Compliance e auditoria: a resposta deve poder ser rastreada a um fragmento concreto de um documento fonte — citação, artigo, cláusula. RAG é o único padrão que o faz estruturalmente.
- Dados com alta frequência de atualização: catálogos de produto, preços, disponibilidade de inventário. Qualquer coisa que muda mais rápido do que atualizarias um modelo.
Na Kiwop implementamos RAG como base do sistema de RAG empresarial para clientes nos setores jurídico, imobiliário e fintech, onde a rastreabilidade ao documento fonte não é opcional.
Quando NÃO usar RAG
RAG não é a solução quando o problema não é de conhecimento mas de comportamento. Se o modelo base produz respostas num formato incorreto, num registo de língua inapropriado, ou com um estilo de raciocínio que não encaixa com o teu domínio — isso não se resolve com mais contexto. Um prompt melhor talvez sim; RAG, não.
Também não é a solução quando a latência é crítica. Um pipeline RAG típico acrescenta 200-600ms à latência total: o tempo de embedding da query, o retrieval vetorial, e o alargamento do prompt. Para interfaces de alta frequência com expectativa de resposta imediata, esse overhead pode ser inaceitável.
E não é a solução quando o corpus é demasiado pequeno. Se os teus documentos cabem facilmente na janela de contexto (digamos, menos de 50 páginas A4), o padrão mais simples é colocar todo o documento no contexto diretamente. Podes poupar meses de trabalho de engenharia de dados.
Custos reais: vector DB, infra, latência
Um RAG empresarial funcional tem três custos que os tutoriais raramente quantificam.
Base de dados vetorial: Pinecone Starter (gratuito até 2GB) é suficiente para protótipos. Um corpus empresarial médio (50K documentos com embeddings de 1536 dimensões) ronda os 500MB-2GB vetoriais — o limite alcança-se antes do esperado. Pinecone Standard começa nos $70/mês. Weaviate Cloud no seu tier de produção é comparável. Se usas pgvector no teu PostgreSQL existente o custo de armazenamento é marginal, mas a escalabilidade de queries concorrentes requer mais gestão.
Embedding na ingestão: um corpus de 100K chunks com text-embedding-3-small da OpenAI ($0,02/1M tokens) custa menos de $5 na primeira vez. O custo real é o reprocessamento quando mudas o modelo de embeddings — algo inevitável quando surgem modelos melhores — e a infraestrutura do pipeline de ingestão (worker, queue, deduplicação, versionamento).
Latência operativa: em produção, com re-ranking incluído, espera 400-800ms de overhead acrescentado. Se o teu LLM já demora 1-2s a responder, o total pode roçar os 3s — acima do limiar de perceção de "resposta lenta" para interfaces conversacionais.
Fine-tuning — treinar o modelo no teu domínio
O que é (LoRA, QLoRA, full fine-tune)
Fine-tuning é ajustar os pesos de um modelo pré-treinado sobre um dataset específico, de forma a que o modelo internalize padrões, formatos, ou conhecimentos que não estão suficientemente representados no seu treino base.
Há três variantes principais segundo custo e capacidade:
Full fine-tuning: todos os pesos do modelo são atualizados. Máxima capacidade de adaptação, custo mais alto. Para modelos de 7B parâmetros requer GPUs com 80GB VRAM (dois A100 no mínimo). Para modelos de 70B já falamos de clusters de 8+ GPUs. Na prática, só faz sentido com instâncias de referência para domínio muito específico ou com modelos proprietários onde o fornecedor gere o cómputo (OpenAI fine-tuning API, Google Vertex AI Tuning).
LoRA (Low-Rank Adaptation): em vez de atualizar todos os pesos, acrescentam-se matrizes de baixo posto que aprendem o delta. A biblioteca PEFT da Hugging Face implementa LoRA como padrão; segundo a documentação oficial de PEFT, LoRA pode reduzir o número de parâmetros treináveis em mais de 10.000x mantendo uma qualidade comparável ao full fine-tuning em muitas tarefas. Um modelo de 7B com LoRA treina numa GPU A10 de 24GB VRAM.
QLoRA: LoRA sobre modelo quantizado a 4-bit. Permite treinar modelos de 70B numa única GPU A100 de 80GB, à custa de alguma qualidade face ao LoRA full-precision. É a variante de referência para experimentação com modelos grandes sem acesso a cluster.
A documentação de fine-tuning da OpenAI cobre o processo completo para os seus modelos (GPT-4o mini, GPT-4o). O fine-tuning do GPT-4o mini tem um custo de $3/1M tokens em treino e $0,30/1M tokens em inferência (30% superior ao modelo base). A Anthropic não oferece fine-tuning público dos seus modelos; a Google oferece tuning sobre Gemini Pro via Vertex AI.
Casos de uso ótimos
Fine-tuning resolve exatamente estes problemas:
- Formato de saída estrito e complexo: se o modelo deve produzir JSON com um schema muito específico, código num estilo da empresa, ou documentos com estrutura fixa, o fine-tuning fixa esse padrão melhor do que qualquer instrução no prompt.
- Registo de língua e tom muito específico: assistentes que devem soar exatamente como a voz de marca da empresa, com vocabulário próprio, formas de cortesia específicas do setor, ou terminologia técnica muito fechada.
- Raciocínio em domínio muito especializado: medicina, direito, engenharia específica de processo industrial. O modelo base tem conhecimento geral do domínio; o fine-tuning afina-o nas particularidades do domínio próprio.
- Latência reduzida via prompts curtos: um modelo fine-tuned pode comportar-se como se tivesse um system prompt longo sem precisar desse prompt em cada chamada — os pesos já internalizam as instruções. Isto reduz tokens de entrada e, portanto, custo e latência.
- Classificação e extração repetitiva: se tens uma tarefa muito definida (classificar emails por categoria, extrair entidades de faturas, normalizar moradas) com milhares de exemplos anotados, fine-tuning supera RAG e prompt engineering em precisão e consistência.
Quando NÃO fazer fine-tuning
Esta é a parte que mais projetos ignoram.
Não faças fine-tuning para acrescentar conhecimento factual que muda com o tempo. O modelo aprende o conhecimento como pesos estáticos; quando esse conhecimento caduca, tens de re-treinar. RAG resolve o problema estruturalmente melhor.
Não faças fine-tuning para resolver alucinações de conhecimento. Se o modelo alucina porque não sabe algo, dar-lhe mais exemplos desse conhecimento em fine-tuning pode reduzir a alucinação nos casos vistos durante o treino, mas não a elimina estruturalmente — e pode aumentá-la em casos não vistos. A solução correta é RAG com grounding na fonte.
Não faças fine-tuning sem dataset de qualidade. O mínimo real para ver melhoria está entre 100 e 1.000 exemplos de alta qualidade, anotados com o formato correto. "Temos 50 exemplos" quase nunca é suficiente. E os exemplos devem cobrir a distribuição real de casos, não apenas os casos felizes.
Não faças fine-tuning como primeiro experimento. Antes do fine-tuning, esgota o prompt engineering avançado (few-shot examples, chain-of-thought, system prompts detalhados). Na maioria dos casos, um prompt bem construído dá 80-90% do resultado com 0% do custo do fine-tuning.
Custos reais (cómputo, dataset, manutenção)
Os custos têm três dimensões que poucas pessoas calculam em conjunto.
Custo de treino: fine-tuning do GPT-4o mini com 1.000 exemplos de 500 tokens = aprox. $1-3. Fine-tuning do GPT-4o com o mesmo dataset = aprox. $30-90. LoRA sobre um modelo 7B open-source num A10G na AWS = $2-8/hora, uma corrida típica de 2-6 horas = $10-50. LoRA sobre um 70B em cluster de A100 = $20-80/hora. Estes são custos de primeira corrida; a experimentação (testar hiperparâmetros, rever erros, re-treinar) multiplica facilmente por 3-5x.
Custo de dataset: a anotação humana de exemplos de qualidade é o custo oculto maior. Se precisas de 1.000 exemplos de classificação médica com etiquetagem de especialista, o custo de anotação pode superar em 10x o custo de cómputo. Para muitos projetos, o dataset é o verdadeiro gargalo, não o treino.
Custo de manutenção: um modelo fine-tuned envelhece. O domínio muda, os casos extremos emergem, o modelo base atualiza-se (e o fine-tuning não migra automaticamente). Cada ciclo de atualização do modelo base implica potencialmente repetir o fine-tuning. Isto converte o fine-tuning num compromisso de longo prazo de engenharia de ML, não um projeto pontual.
MCP — ferramentas e ação
Recap rápido
MCP (Model Context Protocol) é o padrão aberto — publicado pela Anthropic em novembro de 2024 e doado à Linux Foundation em dezembro de 2025 — para ligar agentes LLM a ferramentas externas. Cobrimos a sua arquitetura completa, incluindo a comparativa com WebMCP e A2A, no post MCP, WebMCP e A2A: que protocolo escolher para os teus agentes IA.
A arquitetura básica: um cliente MCP (o agente ou o seu host) liga-se a um ou vários servidores MCP, descobre as suas tools através de um handshake JSON-RPC, e invoca-as com parâmetros tipados durante a geração. As tools podem fazer tudo o que uma API pode fazer: ler e escrever em bases de dados, chamar APIs externas, executar código, enviar emails, modificar ficheiros.
Com mais de 10.000 servidores MCP públicos e 97 milhões de descargas mensais de SDK, MCP é hoje o padrão de facto para ferramentas de agentes.
Quando usar MCP em vez de RAG
A pergunta correta não é "MCP ou RAG" mas sim "o problema é de conhecimento ou de ação?".
Usa MCP quando a resposta requer ler dados em tempo real: se o utilizador pergunta "quantas unidades restam em armazém do produto X?" a resposta está no teu ERP agora mesmo, não num documento indexado há três dias. RAG com corpus atualizado poderia funcionar, mas MCP é mais direto: o agente chama a tool get_inventory(product_id="X") e obtém a resposta exata sem latência de indexação.
Usa MCP quando a resposta requer escrita ou ação: criar um ticket, enviar uma notificação, atualizar um registo, aprovar um workflow. Isto nunca é território de RAG — RAG apenas lê.
Usa MCP quando a fonte de verdade já tem API: se o teu sistema já tem uma API bem definida, construir um servidor MCP em cima é frequentemente mais simples do que montar um pipeline de ingestão + embedding + vector store.
Usa MCP quando os dados são estruturados e relacionais: queries que implicam joins, agregações ou filtros complexos sobre dados relacionais vivem melhor em SQL via um servidor MCP do que em pesquisa semântica sobre chunks de texto.
Na nossa arquitetura para o serviço de integração de LLMs, o padrão que recomendamos por defeito é MCP para acesso a dados transacionais + RAG para documentação e conhecimento não estruturado. Os dois coexistem sem conflito.
Limitações
MCP acrescenta latência de invocação de tool (um round-trip HTTP ou stdin/stdout por ferramenta). Em agentes que encadeiam muitas tools, o tempo de espera acumula-se. E a observabilidade de um agente com tools é substancialmente mais complexa do que a de uma simples chamada LLM: precisas de tracing de tool calls, logging de parâmetros e resultados, e gestão de erros em cada ferramenta. Cobrimos estes padrões em detalhe em agentes IA em produção: padrões e antipadrões.
MCP também não muda as capacidades de raciocínio do modelo. Se o modelo base raciocina mal no teu domínio, dar-lhe tools não corrige isso. As tools amplificam o que o modelo já sabe fazer; não corrigem o que faz mal.
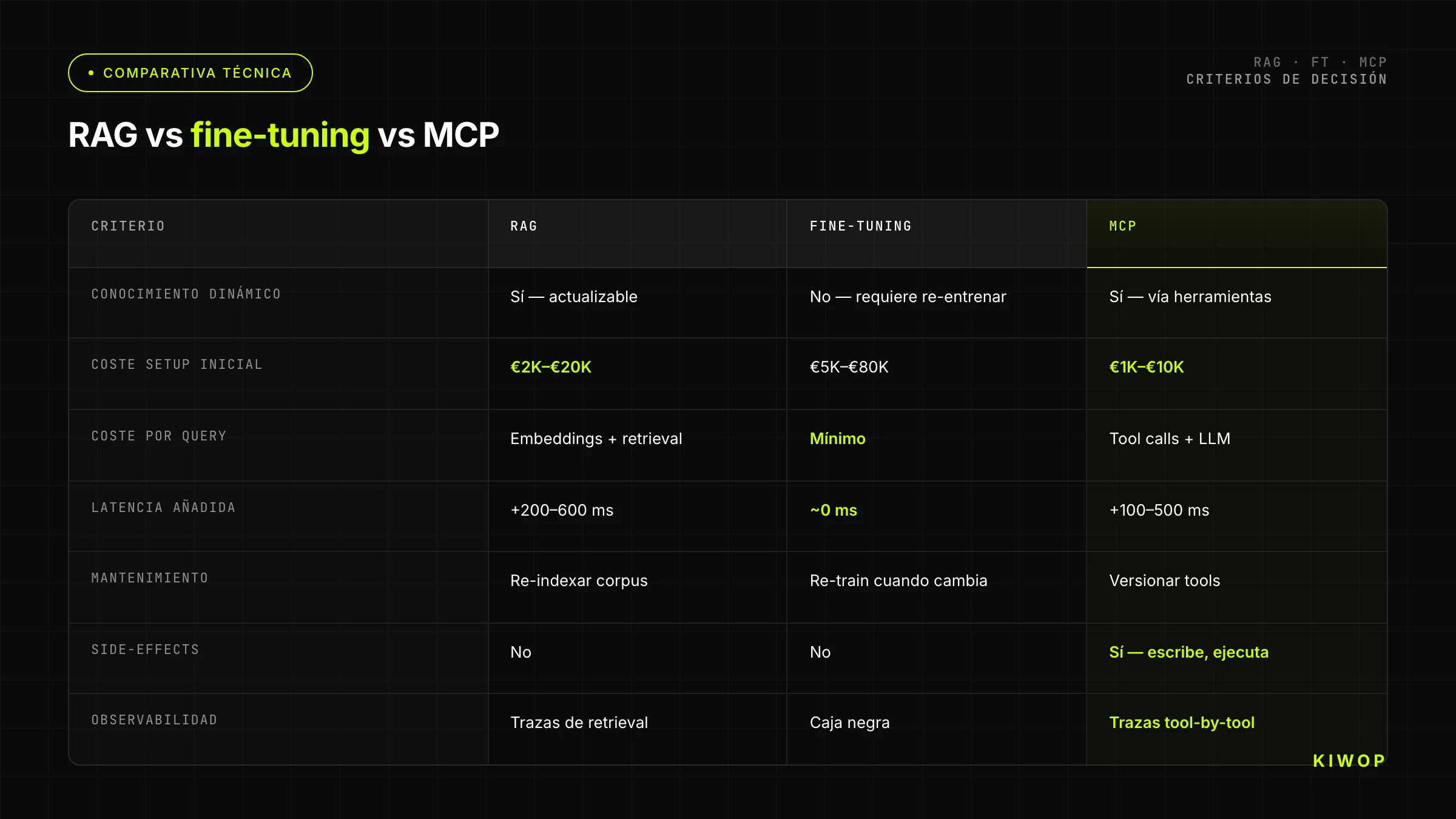
Tabela comparativa: RAG vs fine-tuning vs MCP
Árvore de decisão: o que usar?
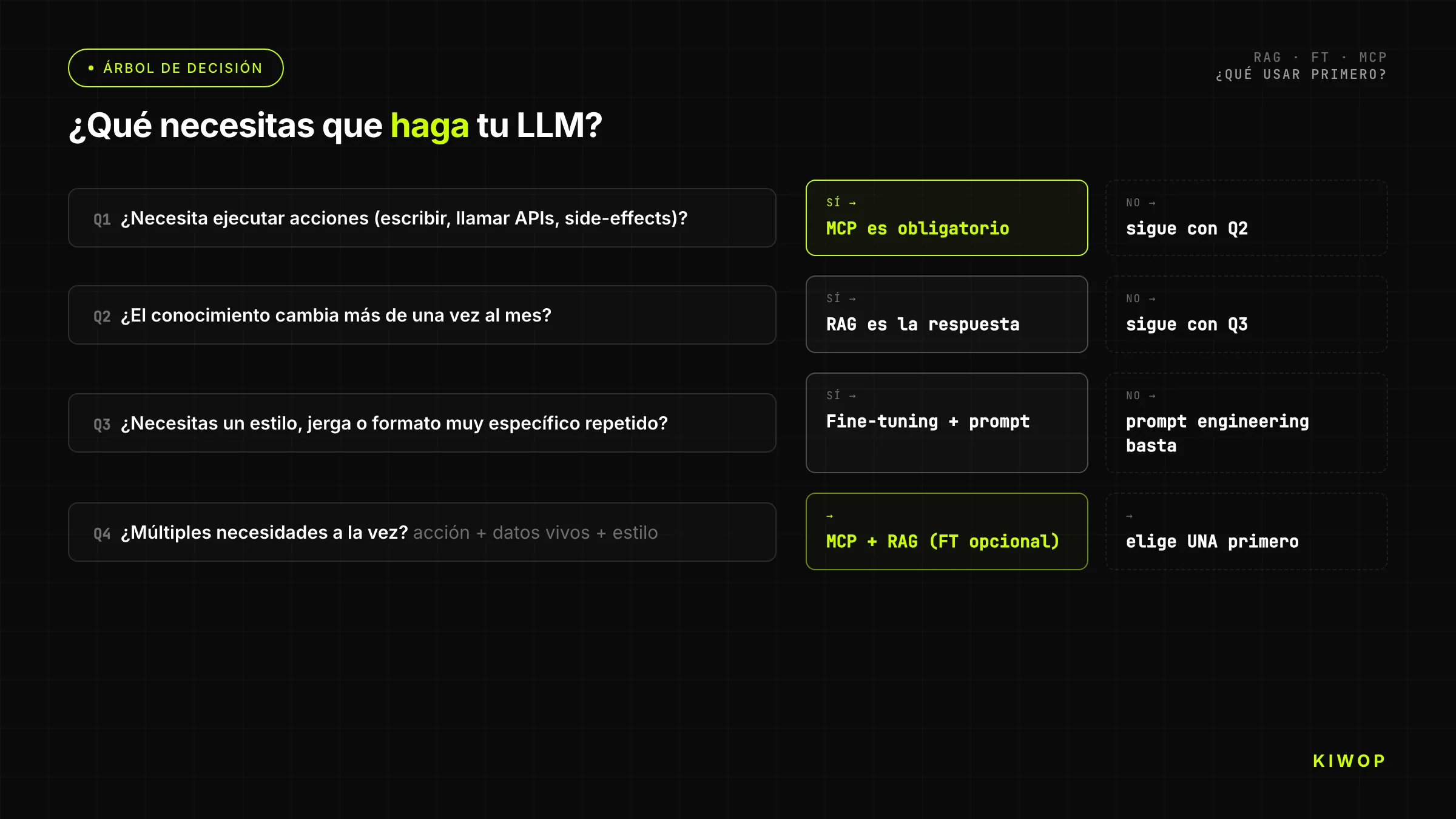
A árvore simplificada para equipas que precisam de uma resposta rápida:
Pergunta 1: o agente precisa de executar ações sobre sistemas externos (ler APIs em tempo real, escrever dados, invocar processos)?
- Sim → precisas de MCP. Também precisas de conhecimento de documentos? Acrescenta RAG. Continua pela árvore nas outras dimensões.
- Não → continua.
Pergunta 2: o LLM precisa de responder sobre documentos, dados ou conhecimento que não esteve no seu treino ou que muda frequentemente?
- Sim → RAG é a primeira resposta. O corpus tem mais de 200 páginas? Confirma que RAG escala para o teu caso. O corpus cabe na janela de contexto? Considera colocar o contexto diretamente sem RAG.
- Não → continua.
Pergunta 3: o modelo base produz respostas no formato/tom/estilo incorreto para o teu caso de uso, e tens mais de 500 exemplos anotados corretamente?
- Sim → fine-tuning é uma opção. Esgotaste o prompt engineering avançado? Se não, começa por aí.
- Não → volta a avaliar se o problema é realmente de comportamento do modelo ou de conhecimento.
Pergunta 4: tens recursos e tempo para manter o modelo fine-tuned ao longo do ciclo de vida do modelo base?
- Sim → fine-tuning.
- Não → prompt engineering avançado + RAG para conhecimento; aceita as limitações de comportamento.
A maioria das aplicações empresariais LLM em produção acaba com RAG + MCP como arquitetura base. Fine-tuning acrescenta complexidade e custo que raramente justifica o benefício incremental face ao prompt engineering bem feito.
Casos reais na Kiwop
Nexo (SaaS multi-tenant): MCP + RAG seletivo
Nexo é o workspace SaaS que estamos a construir na Kiwop. A arquitetura completa está documentada no post sobre arquitetura SaaS multi-tenant com Laravel e Inertia.
O agente do Nexo tem duas camadas distintas de acesso a informação:
Camada MCP — para operações transacionais: criar tarefas, atualizar estados de projeto, ler métricas do workspace do tenant, enviar notificações. Tudo isto vive na base de dados relacional do tenant e tem uma API interna bem definida. Montar um servidor MCP por tenant permite-nos que o agente opere sobre dados reais em tempo real sem latência de indexação.
Camada RAG seletiva — para documentação e notas não estruturadas: atas de reunião, especificações de produto, documentação técnica que as equipas fazem upload para o workspace. Este corpus varia muito entre tenants e não tem estrutura fixa — é exatamente o território do RAG. Usamos Qdrant como vector store com partição por tenant para garantir isolamento de dados.
Fine-tuning: não fizemos nenhum para o Nexo. O modelo base com system prompt bem construído cobre o comportamento esperado. O custo de manutenção de um modelo fine-tuned para um SaaS que evolui semanalmente seria proibitivo.
PA (assistente pessoal): MCP puro
O assistente pessoal PA que construímos com Claude Code, documentado em detalhe no post constrói o teu PA com Claude Code e MCP, usa apenas MCP stdio.
O PA precisa de ler e escrever Gmail, Calendar, Drive e Slack. Toda a informação vive em APIs bem definidas com SDKs maduros — exatamente o caso de uso ótimo do MCP. Não há corpus de documentos proprietário para indexar (o email lê-se diretamente), não há comportamento para mudar (o modelo base é suficientemente capaz), e a latência é tolerável porque as operações são assíncronas.
RAG acrescentaria uma camada de complexidade desnecessária. Fine-tuning não resolve nenhum problema real que tenhamos. MCP puro é a arquitetura mais simples que funciona — e é o que usamos.
Quando combinamos os três
O único caso em que combinamos RAG, MCP e fine-tuning simultaneamente é em projetos de assistentes para setores muito específicos — jurídico e médico, principalmente — onde as três necessidades são reais:
- MCP para aceder a sistemas internos do cliente (processos, calendários de audiências, bases de dados de jurisprudência próprias).
- RAG sobre documentação legal ou clínica (regulamentação, protocolos, historial de casos anonimizados).
- Fine-tuning para adaptar o formato de resposta à terminologia exata do setor e ao estilo comunicativo interno do cliente.
Mesmo nesses casos, fine-tuning é sempre o último que implementamos, depois de esgotar RAG + prompt engineering. E o ciclo de manutenção do modelo fine-tuned está explicitamente planeado e orçamentado desde o início.
5 antipadrões que vemos em produção
1. Fazer fine-tuning quando RAG bastava
É o antipadrão mais frequente e o mais caro. A equipa decide fazer fine-tuning porque "queremos que o modelo conheça os nossos produtos" — mas o catálogo de produtos muda mensalmente. Após semanas de anotação e treino, o modelo fine-tuned tem informação desatualizada desde o primeiro dia. A solução correta desde o início era RAG com corpus atualizado automaticamente.
O sinal de alerta: se te perguntas "precisa o modelo de saber X?" e X é qualquer coisa que muda mais rápido do que o teu ciclo de re-treino, a resposta é RAG, não fine-tuning.
2. RAG sem re-ranking
Um pipeline RAG sem re-ranking recupera os top-K chunks mais similares vetorialmente — mas similaridade vetorial não é o mesmo que relevância real para a pergunta concreta. O modelo recebe contexto parcialmente relevante, mistura informação correta com ruído, e a qualidade de resposta é medíocre.
O re-ranking com um cross-encoder (modelos como bge-reranker-v2-m3 ou Cohere Rerank) acrescenta 50-150ms de latência mas pode melhorar a precisão de resposta em 20-40% segundo o corpus. É um dos investimentos com melhor ROI num pipeline RAG maduro. E no entanto, a maioria das implementações que vemos em produção não o têm.
3. MCP sem sandboxing
Um agente com MCP pode executar ações irreversíveis: apagar registos, enviar emails em massa, executar transações. Sem uma camada de confirmação explícita para operações destrutivas, um agente que interpreta mal uma instrução pode causar dano real.
O padrão correto: distinguir entre tools de leitura apenas (que o agente pode invocar livremente) e tools de escrita ou destrutivas (que requerem confirmação humana explícita antes de serem executadas). MCP não impõe isto por protocolo — é responsabilidade da arquitetura do agente. Cobrimos isso em agentes IA em produção: padrões e antipadrões.
4. Combinar tudo "por precaução"
A arquitetura mais perigosa que vemos é a que combina RAG + fine-tuning + MCP desde o dia um sem casos de uso que justifiquem cada camada. O resultado é um sistema difícil de debugar (o erro vem do retrieval, dos pesos fine-tuned, ou da tool call?), caro de manter, e com múltiplos pontos de falha independentes.
O princípio de engenharia é sempre o mesmo: começa com a arquitetura mais simples que resolve o problema. Acrescenta complexidade apenas quando há um problema concreto que a justifica. Uma aplicação RAG com bom corpus e bom re-ranking supera frequentemente uma arquitetura RAG+FT+MCP mal desenhada em todos os KPIs que importam.
5. Ignorar o custo de manter o corpus
Um sistema RAG em produção não é "indexo os documentos uma vez e está feito". O corpus envelhece: os documentos atualizam-se, acrescentam-se novos, alguns ficam obsoletos. Se não tens um processo de atualização do índice — idealmente automatizado — o retrieval começa a devolver contexto desatualizado e a qualidade do sistema degrada silenciosamente.
O pipeline de manutenção do corpus (deteção de mudanças, re-indexação parcial, validação da qualidade do retrieval) é tão importante quanto o pipeline de ingestão inicial. Quantifica-o no orçamento desde o primeiro dia, ou o sistema funciona bem na demo e mal em produção seis meses depois.
Perguntas frequentes
RAG substitui o fine-tuning?
Não como regra geral, mas RAG substitui o fine-tuning em 80% dos casos em que as equipas acham que precisam dele. Se o objetivo é que o modelo "saiba mais coisas", RAG é quase sempre a resposta correta e mais fácil de manter. Fine-tuning ganha quando o objetivo é que o modelo "se comporte de forma diferente" — diferente formato, tom, ou raciocínio — e quando tens o dataset e o ciclo de manutenção para o sustentar.
Quanto custa montar um RAG empresarial?
Um RAG funcional para um corpus de 10.000 documentos com pipeline de ingestão, vector store em Pinecone ou Qdrant, re-ranking, e frontend básico custa entre $2.000 e $8.000 em desenvolvimento inicial (2-6 semanas de engenharia). O custo mensal operativo em infra (vector DB + API calls de embeddings + LLM calls) costuma estar entre $200 e $2.000/mês segundo o volume de queries. O custo de manutenção do corpus depende de com que frequência se atualiza e se o processo é manual ou automatizado.
Posso usar RAG e MCP ao mesmo tempo?
Sim, e é o padrão que recomendamos para a maioria dos agentes empresariais. O agente tem tools MCP para aceder a dados transacionais em tempo real e um retriever RAG para responder sobre documentos e conhecimento não estruturado. Os dois são invocados em momentos distintos do raciocínio e não interferem entre si. De facto, um servidor MCP pode expor o retriever RAG como tool, tornando o padrão especialmente limpo.
OpenAI ou Anthropic para fine-tuning?
A Anthropic não oferece fine-tuning dos seus modelos a clientes externos hoje. As opções comerciais são OpenAI (GPT-4o mini e GPT-4o), Google Vertex AI (Gemini Pro) e, para modelos open-source, fornecedores como Together AI, Replicate, ou infraestrutura própria. A OpenAI tem a plataforma de fine-tuning mais madura e documentada do mercado. A Google é competitiva para casos de uso no ecossistema GCP. Para a maioria dos projetos novos, se o modelo base candidato é da Anthropic, a alternativa ao fine-tuning não disponível é construir RAG mais sólido ou usar prompt caching para reduzir custos de prompts longos.
Que base de dados vetorial escolher?
Depende do contexto. Se já usas PostgreSQL, pgvector é o ponto de entrada com menor fricção operativa. Se precisas de escalar a milhões de vetores com latências submilissegundo, Pinecone tem o melhor time-to-production. Weaviate é forte quando o corpus é muito grande e precisas de pesquisa híbrida (vetorial + keyword) com múltiplos tenants. Qdrant é open-source, rápido, e a melhor opção se queres controlo total sem licença cloud. Para a maioria dos casos empresariais que gerimos a partir do RAG empresarial, começamos com pgvector no mesmo PostgreSQL do cliente e migramos para Qdrant quando o volume o justifica.
Conclusão e próximos passos
A pergunta não é "RAG, fine-tuning ou MCP?" — é "que dimensão do problema estou a resolver?". Conhecimento dinâmico: RAG. Comportamento do modelo: fine-tuning, mas com critério e com plano de manutenção. Ação sobre sistemas: MCP.
A maioria das aplicações LLM em produção precisam de RAG + MCP como base. Fine-tuning é o terceiro nível que se acrescenta apenas quando RAG + prompt engineering bem construído não é suficiente, e quando a equipa tem capacidade real de sustentar o ciclo de vida do modelo.
A armadilha mais cara é escolher sem critério e descobrir seis meses depois que a arquitetura não se sustenta. Vimos projetos que demoraram dois meses a fazer fine-tuning quando RAG teria demorado duas semanas e teria funcionado melhor. Vimos pipelines RAG sem re-ranking que foram redesenhados completamente depois de o sistema chegar a produção e a qualidade não ser aceitável.
Se a tua equipa está neste processo de decisão — a avaliar se precisam de RAG, fine-tuning, MCP, ou alguma combinação — é exatamente o trabalho que fazemos na Kiwop. Revemos a arquitetura, o caso de uso, os recursos disponíveis, e desenhamos o sistema mínimo que resolve o problema com o menor custo de manutenção. Os nossos serviços de desenvolvimento de agentes IA, RAG empresarial e integração de LLMs estão pensados para equipas que querem chegar a produção com decisões técnicas sólidas, sem pagar o preço de aprender tudo do zero. Escreve-nos e avaliamos.
Se o post te foi útil, segue o fio com o cluster completo: MCP, WebMCP e A2A: que protocolo escolher para os teus agentes IA, agentes IA em produção: padrões e antipadrões e constrói o teu PA com Claude Code e MCP.


