Nexo : anatomie technique de notre SaaS multi-tenant — Laravel 12 + React + Inertia.js + Brain (agents IA)
Par l'équipe de Kiwop · Agence Digitale spécialisée en Développement Logiciel et Intelligence Artificielle appliquée pour clients mondiaux en Europe et aux États-Unis · Publié le 19 avril 2026 · Dernière mise à jour : 19 avril 2026
TL;DR — Nexo est le SaaS opérationnel de Kiwop (RH, CRM, projets, facturation, paie) sur Laravel 12 + React + Inertia.js, avec des agents IA propres (Brain). Trois décisions le définissent : hiérarchie Organization → Workspace → Member avec toggles de modules par workspace, Inertia.js comme pont entre monolithe et SPA, et coexistence contrôlée entre routes legacy (Blade) et nouvelles (Inertia) via un middleware gardien qui bloque les écritures anciennes.

Chez Kiwop nous construisons depuis des années du logiciel sur mesure pour des clients en Europe et aux États-Unis, mais Nexo est différent : c'est le produit que nous utilisons chaque jour nous-mêmes pour opérer l'agence, et en même temps le SaaS que nous offrons comme cas de réussite à des entreprises B2B mid-market qui ont besoin de centraliser RH, CRM, projets et facturation sur une seule plateforme. Quand vous construisez quelque chose que votre propre équipe utilise au quotidien, l'architecture cesse d'être un exercice théorique : chaque décision se paie ou se récolte chaque lundi matin.
Cet article entre dans le détail technique. C'est la documentation de l'état réel du système à avril 2026 — décisions, trade-offs et choses que nous ferions différemment. Il s'insère dans le même cluster que notre post sur la reconstruction d'un assistant personnel avec Claude Code et MCP, le guide pour construire votre PA avec Claude Code, les patrons et antipatrons d'agents IA en production et les protocoles MCP, WebMCP et A2A en 2026. Si ces posts traitent d'agents en dehors de l'app, Nexo est la démonstration de comment mettre des agents à l'intérieur d'une application qui a déjà un domaine riche, des données réelles et un tenancy sérieux.
Qu'est-ce que Nexo et pourquoi nous l'avons construit
Nexo naît d'un problème récurrent dans les entreprises B2B d'entre dix et deux cents employés : l'opérationnel quotidien vit dispersé dans une demi-douzaine d'outils déconnectés. Contrôle horaire dans une app, CRM dans une autre, projets dans ClickUp, facturation dans un ERP, paie chez le comptable, docs dans Notion. Chaque outil fonctionne bien séparément, mais personne ne voit l'opération comme un tout, les données clients se dupliquent entre systèmes, et chaque rapport exige d'exporter des CSV de quatre endroits et de les croiser à la main.
Chez Kiwop nous souffrions de ce problème. Nous avons construit Nexo d'abord pour nous et ensuite nous l'avons converti en produit. Aujourd'hui il couvre cinq modules :
- RH : contrôle horaire (pointages avec géolocalisation et traçabilité légale de quatre ans), gestion des vacances et absences, fiches d'employés, équipes et jours fériés.
- CRM : entreprises, contacts, leads avec pipeline, activités commerciales et campagnes outbound.
- Projects : projets, tâches avec temps enregistrable, commentaires, pièces jointes et sessions de temps.
- Billing : contrats, jalons de facturation, cautions d'appels d'offres, synchronisation bidirectionnelle avec Holded ERP.
- Payroll : paie avec calcul légal espagnol, support pour plusieurs conventions collectives (TIC, Commerce Catalogne), export SILTRA.
Au-dessus de tout cela vivent deux pièces qui le séparent d'un SaaS opérationnel classique : un sous-système d'extraction de contrats avec IA (vous téléchargez un PDF de contrat, l'IA remplit l'inscription) et un moteur d'agents IA propre appelé Brain, qui permet de configurer des protocoles multi-étapes pour que la plateforme exécute un travail autonome sur les données du workspace.
Nexo tourne en production sur nexo.kiwop.com avec des dizaines de workspaces actifs. Ce ne sont pas des milliers : c'est un SaaS B2B mid-market, pas une app grand public. Et il est présenté sur notre site comme cas de réussite même si c'est notre propre produit, car l'histoire technique est exactement la même que celle que nous raconterions si le client était externe.
Pourquoi Laravel + Inertia.js + React (et pas une SPA pure)
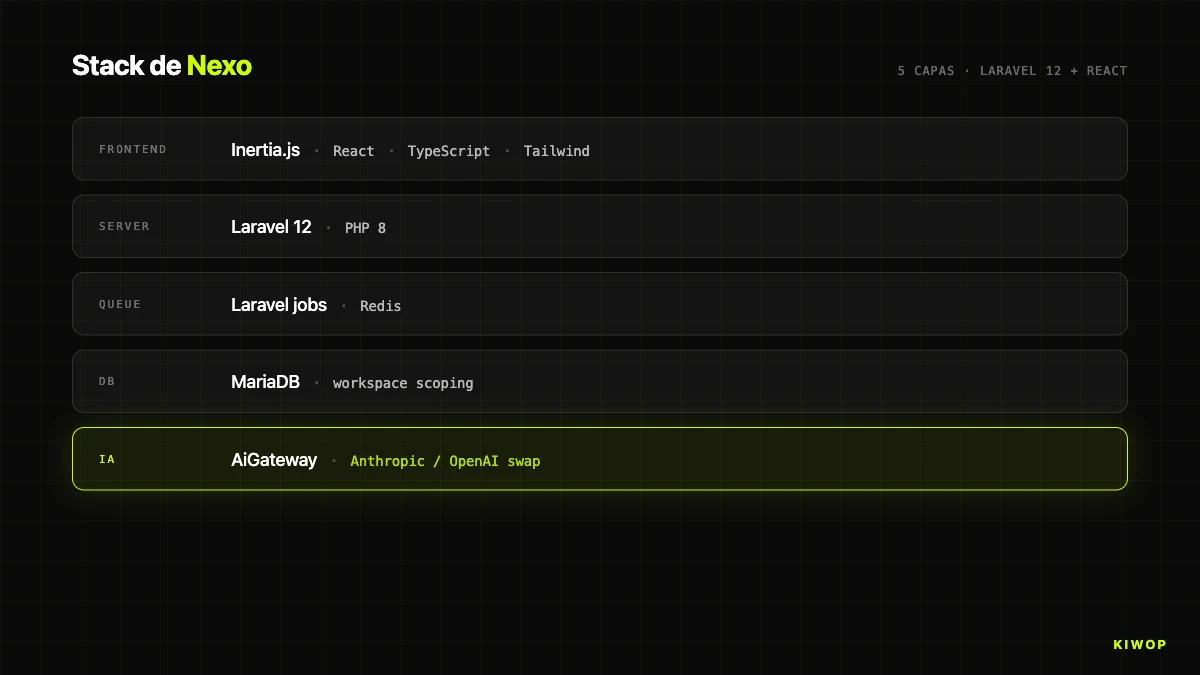
La première grande décision a été le squelette du frontend. En 2025 le consensus par inertie était « SPA en React/Vue consommant une API REST ou GraphQL ». Nous avons choisi une autre voie : Laravel 12 sur le backend, React 18 + TypeScript sur le frontend, et Inertia.js comme pont. Pas une SPA séparée. Un monolithe moderne avec des vues React rendues depuis des contrôleurs Laravel.
Quand vous séparez backend et frontend en deux dépôts connectés par API, vous gagnez une chose et en perdez cinq. Vous gagnez la liberté de mettre un autre frontend demain (une app mobile, une autre marque avec la même API). Vous perdez : authentification unifiée, validation partagée, SEO trivial, déploiement atomique, état de session server-side, et la capacité d'itérer une feature en un seul commit. Pour une application authentifiée interne comme Nexo, ces cinq choses pèsent beaucoup plus que la flexibilité théorique.
Inertia résout l'adéquation. Les contrôleurs Laravel, au lieu de Blade ou de JSON, retournent Inertia::render('NomPage', $props). Cela rend un composant React concret (resources/js/Pages/Workspace/Dashboard.tsx) avec les props que le backend a déjà calculées. Naviguer est un fetch interne qui échange composant et props sans recharger : UX de SPA, vérité sur le serveur, authentification par cookies et middleware Laravel classique.
Le middleware HandleInertiaRequests partage des props globales (utilisateur, workspace, rôle, flags) à toutes les pages, ainsi aucun composant ne demande cet état à chaque page et nous ne montons pas un Redux/Zustand pour quelque chose que le serveur sait déjà. Déploiement unique : git pull, composer install, npm run build, nettoyage des caches, sans fenêtres d'incohérence entre API et client.
Le coût est qu'en ouvrant Nexo à des intégrateurs externes nous avons besoin d'une API formelle parallèle. Nous l'avons montée tôt : REST API `/api/v1` avec Laravel Sanctum (tâches, projets, registres, docs, leads, billing, webhooks), vivant à côté des routes Inertia. Frontend propre par Inertia, intégrateurs par REST avec tokens.
Le modèle multi-tenant : Organization → Workspace → Member
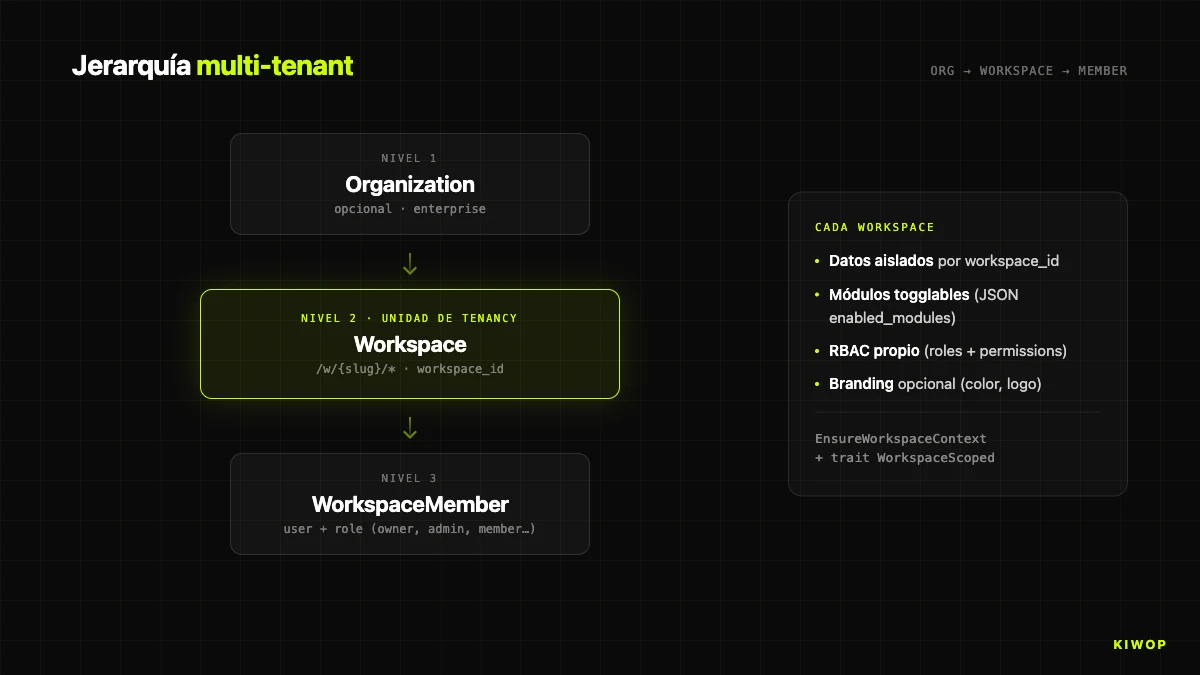
La seconde décision structurelle est comment on fait le multi-tenancy. Deux écoles opposées : shared database avec colonne de tenant contre schema per tenant. Nous avons choisi la première, avec une hiérarchie à trois niveaux.
- Organization : regroupement optionnel pour comptes enterprise avec plusieurs workspaces sous une même marque.
- Workspace : l'unité réelle de tenancy. Données, configuration, modules et identité visuelle propres. Identifié par
slugdans l'URL :/w/kiwop/dashboard. - WorkspaceMember : table pivot qui connecte utilisateurs et workspaces avec un rôle (owner, admin, commercial, operations, member, viewer).
Nous avons choisi shared database avec colonne workspace_id pour trois raisons pragmatiques : faire évoluer le modèle sans migrer N schémas, analytics croisés de produit sans fédérer de queries, et une opération de backup/restore unique. Le coût est qu'un bug qui omettrait un filtre par workspace_id peut, en théorie, croiser les données entre tenants. Nous l'atténuons avec deux pièces.
La première est le middleware `EnsureWorkspaceContext`, qui résout le slug de l'URL vers le modèle Workspace, vérifie l'adhésion de l'utilisateur et, si le workspace appartient à une organisation, aussi l'adhésion dans celle-ci. Il échoue avec 403 si quelque chose ne cadre pas. Il tourne sur toutes les routes sous /w/{workspaceSlug}/*.
La seconde est le trait `WorkspaceScoped` appliqué aux modèles Eloquent sensibles (BrainProtocol, BrainProtocolRun, etc.), de sorte que toute query applique par défaut where workspace_id = ?. Le désactiver requiert de le faire explicitement, et cela se voit en code review.
Il y a un détail opérationnel que nous documentons comme règle absolue : les contrôleurs de workspace doivent inclure string $workspaceSlug comme second paramètre (après Request $request) avant tout autre. Laravel injecte les paramètres positionnellement, et omettre le slug fait que le paramètre suivant ($id) reçoit le slug et la requête meurt dans un 404 silencieux très difficile à diagnostiquer. La route index fonctionne, ce qui fait que le bug n'apparaît qu'en ouvrant le premier détail.
Le tableau suivant résume les décisions architecturales structurantes que nous avons prises dans Nexo, avec la raison et le trade-off assumé. Si vous concevez un système similaire, ce tableau est probablement la partie de l'article qu'il vous convient de copier-coller dans un document interne.
Module toggle system : activer/désactiver des features par workspace
Chaque workspace active ou désactive des modules de manière indépendante. Le mécanisme : une colonne JSON enabled_modules dans la table workspaces qui mappe module à booléen. La liste est fermée et vit dans le code comme constante Workspace::MODULES (nous ne laissons pas l'utilisateur créer de nouveaux modules à l'exécution). Elle inclut les blocs core (dashboard toujours actif, fichaje, registros, solicitudes), analytique (rentabilidad, informes), travail (projects, tasks), ventes (leads, outbound, licitaciones), finances (billing_contracts, billing, contabilidad), outils (booking, decision_requests, chat), connaissance (docs), settings (branding, notifications, settings), RH (employees, practicas, personal_documents, payroll) et modules plus récents comme chatbot, pulse_surveys, proactive_agents, capacity_planner, project_pulses et meetings.
Deux points consultent le toggle : la méthode isModuleEnabled('leads') du modèle, et surtout le middleware `EnsureModuleEnabled` appliqué aux groupes de routes :
Le middleware vérifie deux choses dans l'ordre : (1) si le module est activé pour le workspace, et (2) si le rôle de l'utilisateur dans ce workspace peut accéder au module. Face à tout échec, il retourne 404 (pas 403, pour ne pas filtrer l'existence de la route). C'est une petite mesure de security through obscurity qui, combinée aux autres couches, élève le niveau de reconnaissance pour un attaquant interne.
Pourquoi nous n'utilisons pas de feature flags classiques (LaunchDarkly, Unleash, Flagsmith) : nos toggles ne sont pas des expériences A/B ni des roll-outs graduels, ce sont de la configuration de produit par tenant. Un client sans module Payroll ne l'aura pas tant qu'il ne l'aura pas contracté. Mettre un SaaS externe pour gérer cela serait de la complexité gratuite.
Le module branding mérite une mention à part : quand il est actif, le workspace peut personnaliser sa couleur primaire (variable CSS --workspace-primary), téléverser un logo et adapter l'identité visuelle. Utile pour white-label ou clients enterprise qui veulent la marque interne. Le CSS de base se maintient, seul l'accent change.
RBAC : rôles + permissions sans bibliothèques externes
Pour l'autorisation, Nexo n'utilise pas Spatie Laravel-permission ni aucune autre bibliothèque. Nous avons un système RBAC propre : tables roles, permissions et role_permissions, avec les rôles fixes (owner, admin, comercial, operations, member, viewer) et permissions granulaires définies dans RbacSeeder. Trois raisons pour ne pas utiliser de bibliothèque.
Premièrement, le domaine des permissions est couplé à des concepts propres : workspace, organisation, modules, actions sur des entités. Ce n'est pas « utilisateur peut faire X », mais « cet utilisateur, dans ce workspace, avec ce rôle, peut faire X sur Y ». Avec une bibliothèque générique nous aurions fini par réécrire la moitié des couches par-dessus.
Deuxièmement, le Gate de Laravel résout déjà l'autorisation. Nous définissons des gates dans AuthServiceProvider pointant vers des policies (DocumentationPolicy::viewCategory) et utilisons Gate::allows(...) ou @can(...) dans les vues. La seule chose que nous ajoutons est la résolution du rôle de workspace : $workspace->getUserRole($user) et $workspace->canRoleAccessModule($role, 'leads'), cachée dans $request->attributes pendant le cycle de vie de la request.
Troisièmement, nous avons un mécanisme de simulation (« voir l'app comme un autre utilisateur », utile en support) qui interagit avec le RBAC de manière spécifique : quand l'admin simule, le bypass habituel « admin peut tout » se désactive à dessein, et vous voyez l'app telle que la voit l'utilisateur simulé. Cela vit dans EnsureModuleEnabled avec $request->attributes->get('is_simulating', false). Par-dessus une bibliothèque externe cela aurait été fragile.
Legacy coexistence : Blade ancien + Inertia nouveau en parallèle
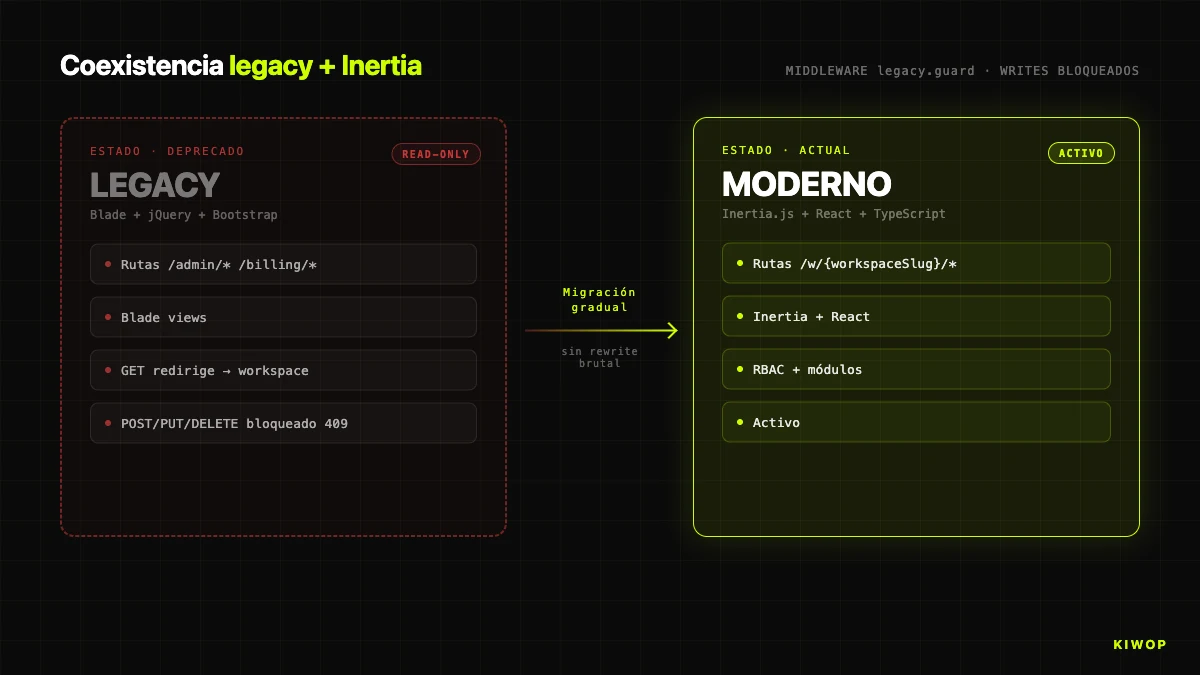
Nexo a une histoire antérieure. La version originale de l'application était construite sur Laravel 10 avec Blade + jQuery + Bootstrap. Le frontend Inertia/React est postérieur. La migration ne s'est pas faite d'un coup : il reste encore du code Blade vivant en production. Cette coexistence est la réalité de toute application réelle qui a plusieurs années en production.
La question est comment éviter que cette coexistence devienne un problème. Notre réponse est le middleware `LegacyRouteGuard`, enregistré comme legacy.guard, appliqué à toutes les routes anciennes. Il fait trois choses :
- Logue tout accès aux routes legacy dans
storage/logs/legacy-routes-*.log. Télémétrie réelle de quelles routes anciennes restent vivantes, guide la priorisation. - Bloque POST/PUT/PATCH/DELETE avec 409 Conflict et message « Legacy interface is read-only ». Aucun changement de données ne passe par la voie ancienne.
- Redirige les GET vers l'équivalente nouvelle quand il y a un mapping défini. Le
redirectMapassocie route legacy à route workspace ('admin.horarios' => 'workspace.registros.index', etc.) et résout les paramètres (workspaceSlug,articleId,contract) sur le moment.
La règle clé est « GETs ouverts, writes fermés ». Si vous bloquez tout, vous cassez les bookmarks et les liens anciens dans les e-mails. Si vous permettez les writes, vous avez deux chemins pour modifier les mêmes données et vous ne pouvez pas garantir que les validations, événements et logs d'audit du nouveau chemin se déclenchent. La combinaison « lis par la voie ancienne, écris seulement par la nouvelle » permet de ne pas casser les bookmarks pendant que nous migrons les vues une à une sans crainte.
Il y a une exception : les routes de simulation d'admin (/admin/simulate-employee, /admin/stop-simulation, /admin/toggle-view-mode) n'emportent pas le gardien, car ce sont des portes légitimes de support. Le reste, oui.
C'est un pattern reproductible : si vous avez une app Laravel de 2019 avec Blade et que vous voulez migrer vers Inertia sans arrêter six mois le business, ajoutez un middleware gardien, bloquez les writes, loguez les accès, mappez les redirects, et attaquez la migration par fréquence d'accès réelle (pas par ordre alphabétique ni par goût esthétique).
Brain — le système d'agents IA de Nexo
Ici entre la pièce la plus propre à Nexo : Brain, un moteur d'agents IA multi-étapes qui vit à l'intérieur de l'application. Ce n'est pas un wrapper de LangChain ni un framework générique. C'est un moteur conçu pour exécuter des automatisations sur les données d'un workspace, avec des limites explicites et une traçabilité totale.
Le domaine est composé de deux modèles : `BrainProtocol` (définition : nom, description, étapes, configuration) et `BrainProtocolRun` (exécution : contexte, résultats étape par étape, état, tokens). Les deux vivent sous workspace_id avec le trait WorkspaceScoped, donc ils ne se croisent jamais entre tenants.
Le moteur `BrainProtocolEngine` traite les étapes séquentiellement avec un contexte mutable en mémoire. Chaque étape lit du contexte, exécute sa logique et écrit sous une output_key que les étapes suivantes peuvent lire. Il applique deux limites dures écrites à feu :
Un protocole avec plus de dix étapes se tronque à l'exécution. Si le contexte accumulé dépasse 300 000 caractères, nous loguons un warning et avant d'appeler le modèle nous le tronquons avec un marqueur [CONTEXTO TRUNCADO POR LÍMITE DE TAMAÑO]. Ces deux limites sont la barrière contre le risque le plus réel d'un agent : l'explosion combinatoire de contexte et de coût quand il itère sur ses propres outputs.
Brain supporte six types d'étapes :
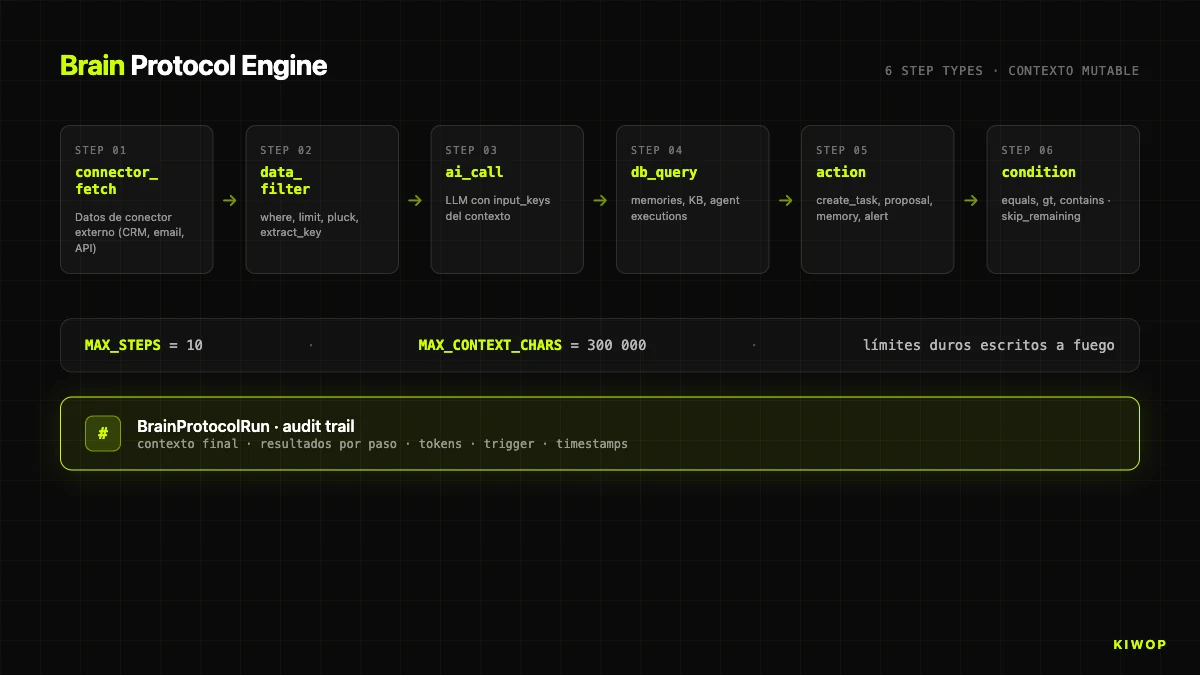
L'étape ai_call est celle qui fait le plus de travail. Elle lit les clés marquées comme input_keys, les sérialise en JSON sous des en-têtes ### clé et les ajoute à une section ## DATOS DISPONIBLES concaténée au prompt. Cela rend explicite le contrat prompt-contexte, évite que le modèle invente des données en dehors de la section, et facilite le debug : le contexte exact reste dans l'audit trail.
L'étape action est ce qui fait de Brain « un agent » et non un pipeline. Types supportés : create_task, create_proposal, save_memory, alert. Chacun résout les paramètres avec des templates {{key.subkey}} contre le contexte : le titre d'une tâche peut être {{ai_summary.content}} et le moteur le substitue avant d'exécuter. Connecte le raisonnement du modèle avec l'action réelle sur le domaine.
L'étape condition est le coupe-feu. Avec skip_remaining_if_false: true, si la condition n'est pas remplie, le reste du protocole est sauté et les étapes restent marquées comme skipped_remaining. Permet des protocoles du type « s'il n'y a rien à faire, ne dépense pas de tokens ».
Exemple : protocole d'onboarding de leads. (1) connector_fetch de nouveaux leads des dernières 24 h. (2) condition qui abandonne si la liste est vide. (3) data_filter qui ne garde que les leads avec score > 60, limite 20. (4) ai_call qui génère un premier brouillon de courriel. (5) action type create_proposal qui dépose la proposition dans la boîte du commercial — pas un courriel envoyé, car les actions à effet externe passent par une approbation humaine.
Tout est enregistré dans BrainProtocolRun : contexte final, résultats de chaque étape avec durée et état, tokens, utilisateur, source du trigger (manuel, schedule, connector_update, agent_alert) et timestamps. Cet audit trail est le tableau par lequel un compliance officer peut auditer ce que l'IA a fait sur les données du client. Sans lui, un SaaS avec des agents n'est pas auditable ; avec lui, il l'est au grain le plus fin. Brain est notre matérialisation interne de beaucoup des patrons que nous documentons dans agents IA en production : patrons et antipatrons pour 2026.
Extraction de contrats avec IA + anti-hallucination
L'autre pièce importante d'IA dans Nexo est antérieure à Brain et résout un cas concret : inscrire un contrat de facturation à partir de son PDF. Le travail manuel de copier nom du client, montant, dates, données e-Fact, cautions et jalons est collant et sujet aux erreurs.
Le sous-système `AiContractExtraction` résout ce flux. Un endpoint POST /billing/contracts/ai-extract reçoit le PDF (maximum 10 Mo), le fait passer par PdfTextExtractor (basé sur smalot/pdfparser), et le livre à l'extracteur choisi par AiExtractorFactory. La factory choisit entre OpenAiContractExtractor (GPT-4o dans sa version stable la plus récente, configurable par OPENAI_MODEL) ou son équivalent Anthropic selon AI_PROVIDER. L'interface ContractExtractorInterface garantit que changer de fournisseur est un flag.
Le prompt est optimisé pour des contrats en espagnol, avec des règles anti-hallucination explicites. La réponse est du JSON structuré où chaque champ est un objet avec value, confidence (0-1) et evidence (citation littérale du texte du PDF). Cela change l'UX radicalement : le formulaire se remplit automatiquement seulement quand confidence >= 0.5, les champs remplis apparaissent avec une bordure bleu clair et un tooltip « Rempli par IA (confiance : 85 %) », et un accordéon « qu'est-ce que l'IA a trouvé ? » montre la preuve littérale. L'humain ne fait jamais confiance aveuglément : il révise, ajuste et sauvegarde.
Les règles anti-hallucination du system prompt sont le cœur de pourquoi cela fonctionne. Si l'IA ne trouve pas un champ, la valeur doit être null et confidence doit être 0. Si elle infère une valeur par contexte (supposer 21 % de TVA quand ce n'est pas détaillé), elle doit baisser la confidence et ajouter une entrée à warnings. Les warnings sont montrés avant de sauvegarder : « TVA non détaillée trouvée, supposant 21 % », « Date de fin non spécifiée clairement ». La combinaison confidence + evidence + warnings + révision humaine obligatoire est ce qui fait qu'une extraction avec LLM soit opérable dans un environnement où une erreur vous fait émettre une facture incorrectement.
Tout reste dans la table ai_contract_extractions : qui a téléchargé, quand, quel fichier (avec hash SHA256 ; nous ne stockons pas le texte complet, c'est important pour la confidentialité), quel fournisseur, quel modèle, tokens, coût estimé, résultat JSON, warnings, état. Si cinq mois plus tard quelqu'un demande « comment ces données sont-elles arrivées au contrat ? », la réponse est dans la base de données.
Le moteur général derrière — celui qui permet le swap entre OpenAI et Anthropic avec un flag, celui qui gère les limites de budget (AiBudgetGuard), celui qui résout quelle connexion utiliser selon le workspace (AiConnectionResolver) — est l'`AiGateway`, le même qu'utilisent les ai_call de Brain. Centraliser la sortie vers les LLMs donne trois choses : point unique pour rate limits et budgets, point unique pour loguer les tokens par feature (chat, agent, extraction), et point unique pour changer de fournisseur sans toucher au code métier. Si demain nous testons un Sonnet 5 ou un GPT-6, le changement vit dans une seule ligne.
Cette abstraction nous l'appliquons aussi dans des projets clients sous intégration de LLMs et développement d'agents IA. Centraliser la porte de sortie vers le modèle est un des premiers conseils que nous donnons à qui intègre de l'IA dans un produit en production.
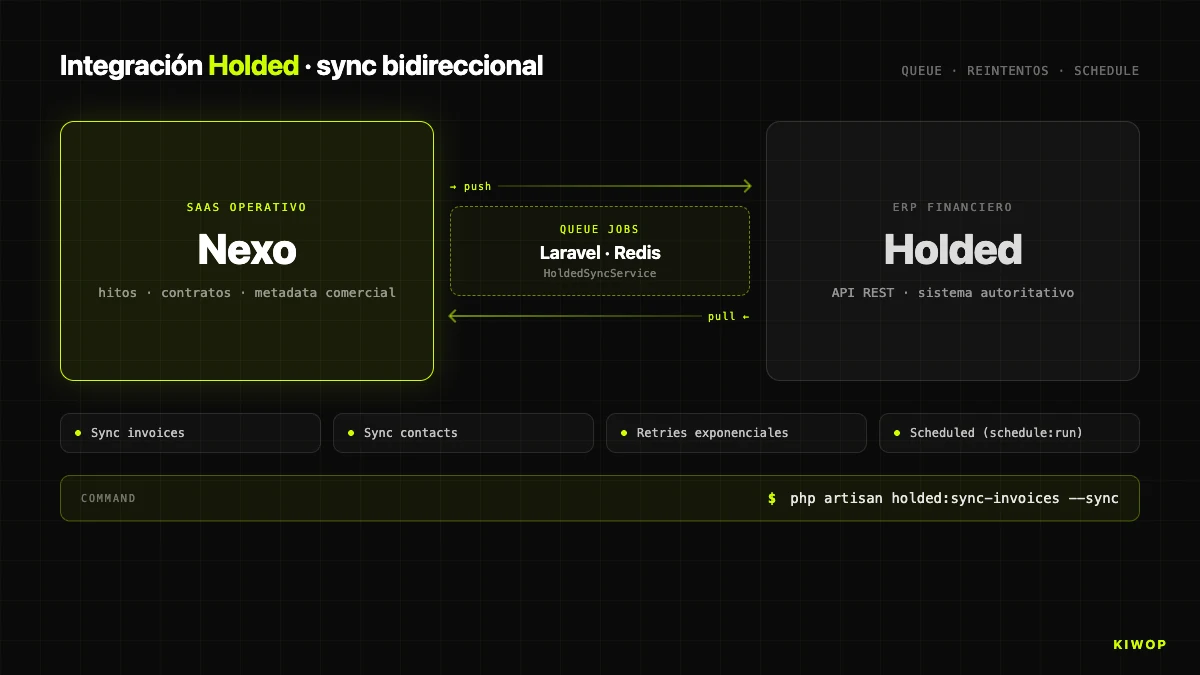
Intégration avec Holded ERP (bidirectionnelle)
Nexo ne remplace pas l'ERP de facturation. Il remplace le panneau de gestion qui regarde vers l'ERP. Pour la facturation réelle nous continuons d'utiliser Holded et nous synchronisons bidirectionnellement avec lui. L'intégration vit sous app/Services/Holded/ avec quatre pièces : HoldedClient (client HTTP), HoldedSyncService (orchestrateur), HoldedStatusMapper (mapping d'états) et SyncResult / BatchSyncResult (résultats typés).
La synchronisation suit le pattern classique d'intégration avec ERP externe : jobs en queue avec réessais, synchronisation programmée toutes les 15 minutes, et un Artisan command holded:sync-invoices --sync pour forcer un tour manuel. La direction bidirectionnelle signifie deux flux : de Nexo à Holded quand un jalon est marqué comme « émis » (la facture se crée) ou « payé » manuellement, et de Holded à Nexo quand un client paie une facture dans l'ERP et le changement d'état revient au tour suivant.
La gestion des conflits est où ces intégrations se salissent. Notre règle : « Holded gagne dans les états financiers, Nexo gagne dans les metadata commerciales ». L'état de paiement est décidé par Holded (système financier officiel). Les étiquettes internes, notes et liens vers projets sont décidés par Nexo. Cette division réduit les conflits à un sous-ensemble gérable où l'une des deux parties est toujours autoritaire.
HOLDED_ENABLED active ou désactive l'intégration par environnement. La configuration se fait au niveau du workspace, pas globalement — chaque workspace peut pointer vers sa propre instance de Holded avec sa propre clé.
Observabilité et opération en production
Si vous ne pouvez pas l'opérer, vous ne l'avez pas. Nexo tourne en production sous nexo.kiwop.com avec un stack simple : PHP 8.4 FPM avec pool dédié, MySQL/MariaDB 10.4, Node 20 via nvm pour le build frontend, et nginx devant. En développement, DDEV avec réplique du stack dans Docker. Parité dev/prod circonscrite (PHP 8.2 local vs 8.4 production).
L'observabilité quotidienne s'appuie sur trois sources. storage/logs/laravel.log est le log principal (erreurs, exceptions, warnings du moteur de Brain quand le contexte déborde). storage/logs/legacy-routes-*.log est le log dédié aux accès aux routes legacy, tourné par jour : si une route n'apparaît pas en deux semaines, elle est candidate à la suppression. Et BrainProtocolRun est l'audit trail structuré de chaque exécution d'agent, consultable par SQL.
Le déploiement suit ./scripts/deploy.sh : artisan down, backup de DB, git pull, composer install --no-dev, build de frontend si les deps ont changé, artisan migrate --force, caches, artisan up. Rollback : restaurer le dernier mysqldump et git checkout <sha>. Ratio de déploiements bas, révision humaine par déploiement.
Une pièce opérationnelle intéressante est le relay de Claude CLI (claude-relay.service). Certains workspaces utilisent une connexion IA par authentification CLI (style OpenClaw) au lieu d'API key, pour consommer un abonnement Claude Max dédié. Le relay est un daemon PHP sous systemd comme utilisateur proves (jamais root) qui traduit les requêtes HTTP internes en appels au CLI claude -p. Pattern pour découpler le coût d'IA de l'usage réel de la plateforme.
Scaling et leçons apprises
Il convient de s'arrêter et de raconter ce qui a fait mal, ce que nous ferions différemment et ce que nous ajouterions si nous commencions aujourd'hui.
Ce qui fait mal aujourd'hui. Les controllers de workspace requièrent de se rappeler la signature (Request $request, string $workspaceSlug, ...). Erreur humaine commise suffisamment de fois. Avec le recul, nous l'aurions résolu avec l'injection de dépendance du CurrentWorkspace DTO au lieu de lire le slug du paramètre de route — EnsureWorkspaceContext l'enregistre déjà, nous ne l'utilisons simplement pas consistamment comme porte unique. Migrer les controllers vers ce pattern est un travail en cours.
La coexistence Blade + Inertia a duré plus longtemps que prévu. Le plan initial était de migrer toute l'app en six mois. Aujourd'hui, avec le middleware gardien bloquant les writes depuis plus d'un an, il existe encore des vues Blade en lecture seule que personne n'a priorisé de migrer. Ce n'est pas un problème de sécurité mais bien de maintenance (deux stacks en parallèle) et de consistance UX. Leçon : la migration incrémentale avec gardien fonctionne, mais elle a besoin d'un calendrier explicite et d'un owner ; sans propriétaire clair, la migration se suspend.
Ce que nous n'ajouterions pas. Nous avons résisté à mettre un framework d'agents externe (LangChain, CrewAI, Haystack) pour Brain. Brain fait exactement ce dont nous avons besoin et un framework générique aurait multiplié la surface sans ajouter de capacité fonctionnelle. Pour un agent qui vit à l'intérieur d'une app Laravel avec domaine propre, un moteur sur mesure de peu de lignes bien comprises pèse moins qu'un framework de milliers de lignes que vous ne contrôlez pas.
Ce que nous ajouterions. Nous commençons à penser au WebMCP comme protocole externe pour exposer Brain à des agents tiers (Claude Code, Cursor, un PA du client). Si Brain exécute déjà du travail autonome sur le workspace avec audit trail complet, l'exposer comme serveur MCP permettrait à un agent externe d'exécuter les protocoles de Nexo comme tools natives. C'est le pattern que nous analysons dans l'article sur MCP, WebMCP et A2A. Travail des prochains mois.
Ce que nous n'avons pas publié. Nous ne donnons pas de chiffres concrets de workspaces actifs, d'utilisateurs, de tokens mensuels ni de runs de protocole par jour. Pas par secret : tout nombre devient obsolète en trois mois et nous préférons ne pas donner de métriques qui deviennent du « donné historique incorrect ». Si cela s'applique à une évaluation technique préalable à un projet, demandez-nous directement.
Scale. Nexo n'est pas un SaaS massif : dizaines de workspaces B2B mid-market, chacun avec dizaines à bas centaines d'utilisateurs. L'architecture supporte largement un ordre de grandeur de plus sans refonte ; le goulot d'étranglement réel — dans l'ordre de milliers de workspaces — serait la synchronisation avec Holded (à cause du rate limit de l'API externe, pas de Nexo) et la couche de cache.
Questions fréquentes
Pourquoi Inertia.js au lieu d'une SPA séparée avec API REST ?
Parce que Nexo est une application authentifiée interne, pas un produit public massif. Inertia donne une UX de SPA avec déploiement atomique, auth unifiée, validation partagée et session server-side. Une SPA séparée n'a de sens que lorsque vous avez besoin de plusieurs frontends sur la même API ou quand frontend et backend vivent sur une infrastructure distincte, aucun des deux ne s'applique. Nous maintenons en même temps une API REST /api/v1 pour intégrateurs externes.
Partager une base de données avec colonne `workspace_id` est-il sûr face à un schema par tenant ?
C'est sûr si vous appliquez de la discipline : middleware qui résout le workspace à chaque requête, trait WorkspaceScoped qui applique le filtre par défaut, et code review qui bloque les désactivations du scope. Le coût de schema par tenant (migrations N fois, backups par tenant, analytics fédérés) ne compensait pas. Pour des charges très élevées ou des exigences réglementaires spécifiques (healthcare) le calcul change.
Que fait un `BrainProtocol` et comment se configure-t-il ?
Un protocole est une séquence allant jusqu'à 10 étapes typées (connector_fetch, data_filter, ai_call, db_query, action, condition) que le moteur exécute séquentiellement en partageant un contexte mutable. Il se configure depuis le panneau du workspace en choisissant le trigger (connector, schedule ou manuel), en définissant les étapes dans l'ordre et en marquant lesquelles sont critiques. Chaque run génère un BrainProtocolRun avec audit trail complet.
Combien coûte Brain en tokens par mois ?
Dépend de l'usage et du modèle. Les limites MAX_STEPS = 10 et MAX_CONTEXT_CHARS = 300000 sont les coupe-feu durs, et chaque ai_call inclut son propre max_tokens (par défaut 2000). Pour le profil d'usage actuel, le coût est une ligne mineure de frais opérationnels et se monitore par feature (chat, agent, extraction) à travers l'AiGateway.
Comment gérez-vous l'intégration avec Holded si Holded tombe ?
Les jobs de synchronisation sont en queue avec réessais. Si Holded est tombé, la synchronisation se dégrade sans casser Nexo : les jalons continuent de pouvoir être créés et modifiés, la création dans Holded reste en file et se réessaie quand l'API répond. L'état visible est « en attente de synchronisation ». Nous ne bloquons pas l'opération du workspace pour une chute de l'ERP.
Pourquoi avez-vous maintenu Blade ancien pendant plus d'un an ?
Parce qu'un big-bang rewrite d'une app en production avec des données réelles est un anti-pattern avec des histoires d'horreur. Le middleware legacy.guard bloque les writes depuis le jour un, éliminant le risque d'inconsistances. Migrer des vues en lecture seule est un travail sans date critique, guidé par les logs d'usage réel. L'alternative — arrêter les features six mois — aurait été bien pire commercialement.
Que se passe-t-il si un développeur oublie `string $workspaceSlug` dans un controller de workspace ?
La requête arrive au controller mais Laravel injecte le slug dans le paramètre suivant ($id), le lookup échoue et la requête retourne 404. Symptôme : 404 silencieux très difficile à diagnostiquer. La route index fonctionne, donc le bug n'apparaît qu'en ouvrant le premier détail. C'est documenté comme règle absolue et c'est la première chose que nous expliquons à tout développeur nouveau.
Peut-on exposer Brain comme serveur MCP pour qu'un agent externe l'utilise ?
Aujourd'hui non, c'est dans la roadmap. La pièce technique existe (moteur, audit trail, limites per-workspace) et le pas naturel est de l'envelopper dans un serveur MCP qui respecte RBAC et toggles de modules. Cela ouvre Nexo à des écosystèmes d'agents externes sans ouvrir la base de données. Si le cas d'usage vous intéresse pour votre propre SaaS, cela fait partie du développement d'agents IA et du conseil en IA.
Conclusion : construire un SaaS en 2026 n'est pas choisir une mode, c'est choisir la discipline
La conclusion honnête de convertir Nexo d'une app Laravel 10 avec Blade en une plateforme opérationnelle complète avec Laravel 12, Inertia + React et agents IA est que l'architecture technique pèse beaucoup moins que ce que les gens croient en choisissant le stack, et beaucoup plus que ce que les gens croient en le maintenant. Rien de ce que nous racontons ici n'est exotique : Laravel est mature depuis une décennie, Inertia est une pièce simple, le multi-tenancy avec colonne workspace_id est le pattern par défaut de l'écosystème PHP, le RBAC avec tables roles + permissions + role_permissions est dans n'importe quel cours de design de bases de données. La différence entre un SaaS qui scale et un qui bloque ne se trouve pas dans le nom du framework — elle est dans la discipline avec laquelle vous appliquez les middleware qui bloquent les accès croisés, dans les limites explicites que vous écrivez à feu quand vous mettez de l'IA dans le flux, et dans votre capacité à cohabiter avec du code legacy sans le transformer en bombe à retardement.
Nexo est le produit qui illustre le mieux comment nous travaillons. Si votre entreprise envisage de construire un SaaS multi-tenant, si elle a besoin d'introduire des agents IA de manière auditable dans une application qui a déjà des années en production, ou si vous évaluez Nexo directement comme plateforme opérationnelle, parlons-en. Nous sommes Kiwop, Agence Digitale spécialisée en Développement Logiciel et Intelligence Artificielle appliquée pour clients mondiaux en Europe et aux États-Unis, et nous offrons du développement sur mesure d'agents IA, du conseil en intelligence artificielle, de l'intégration de LLMs et du RAG d'entreprise pour des contextes de production. Vous pouvez voir le cas de réussite public de Nexo ou nous écrire directement.