Par l'équipe Kiwop · Agence digitale spécialisée en Développement logiciel et Intelligence artificielle appliquée pour clients globaux en Europe et aux États-Unis · Publié le 20 avril 2026 · Dernière mise à jour : 20 avril 2026
TL;DR — Une architecture API-First conçoit le système à partir de ses contrats lisibles par machine avant toute interface humaine. Lorsque le consommateur principal n'est plus un navigateur mais un agent IA, cela sépare les produits qui survivent de ceux qui ne survivent pas. Ce guide rassemble les six principes, les patterns qui fonctionnent, les quatre antipatterns qui tuent l'adoption, et le cas réel de Nexo — notre SaaS qui expose MCP comme contrat natif.
 agents IA — diagramme du stack headless Kiwop avec MCP, OpenAPI, API Gateway et event-driven" width="800" height="450" loading="lazy" />
agents IA — diagramme du stack headless Kiwop avec MCP, OpenAPI, API Gateway et event-driven" width="800" height="450" loading="lazy" />Chaque semaine, le même appel arrive depuis un comité technique : « Nous voulons ouvrir notre produit aux agents IA, mais notre backend a été conçu pour une SPA ». La réponse honnête n'est jamais « montez un endpoint REST et voilà ». La bonne réponse commence par une question : votre architecture est-elle pensée pour qu'un consommateur principal soit une machine, ou pour que ce soit un humain avec une souris ? Si c'est la seconde option, chaque nouvel agent que vous connecterez paiera la taxe du mismatch — latence, scraping fragile, retries mal gérés, comptes partagés entre humains et bots. API-First n'est pas un style de code ; c'est la décision architecturale qui élimine cette taxe dès le premier jour.
Qu'est-ce que l'architecture API-First (définition opérationnelle)
Une architecture API-First est celle dans laquelle chaque contrat lisible par machine — son shape, sa version, son authentification, son observabilité — est conçu et validé avant toute interface utilisateur qui le consomme. Le backend n'expose pas « ce dont la SPA a besoin aujourd'hui » ; il expose un contrat public, typé, versionné, documenté et découvrable, à partir duquel n'importe quel client (web, mobile, tiers, agents IA) consomme ce qui l'intéresse.
La distinction clé n'est pas technique mais de séquence. En API-First, le contrat est l'artefact primaire — il est revu en PR, publié en OpenAPI ou AsyncAPI, versionné comme librairie indépendante. L'UI vient après et l'agent vient après. Tous sont clients du même citoyen de première classe.
API-First vs API-Design-First vs Code-First
Trois termes utilisés de manière interchangeable mais qui signifient des choses différentes :
- Code-First : le code vient en premier. Le contrat (OpenAPI, gRPC, GraphQL schema) est généré à partir du code. Rapide pour démarrer, coûteux à maintenir. Le contrat reste toujours un pas en arrière.
- API-Design-First : le contrat est conçu comme document lisible par l'humain avant d'écrire le code. Utile pour coordonner de grandes équipes, mais ne garantit pas que le consommateur principal soit une machine.
- API-First : le contrat lisible par machine est l'artefact premier, dernier et toujours. Il est conçu comme produit avec sa propre roadmap, son SLA, son changelog et son support. L'UI est un client parmi d'autres.
Notre recommandation pour toute plateforme souhaitant s'exposer aux agents IA : API-First avec API-Design-First comme rituel d'équipe. Le contrat vit dans son propre repo ou package, est revu en PR, est publié en versioning sémantique.
Pourquoi avec les agents IA, l'API EST l'UI
Historiquement, l'UI était le produit et l'API un extra. Les entreprises investissaient dans le design d'interaction, les tests A/B de boutons, les flux d'onboarding visuels. L'API existait comme porte dérobée pour les intégrations ou SDKs, mais le budget produit était sur l'écran.
Avec les agents IA, cette hiérarchie s'inverse. Un agent ne voit pas votre header, ne clique pas votre CTA, n'apprécie pas votre animation de loading. Ce qu'il voit seulement, c'est le contrat — et si le contrat est ambigu, mal versionné ou comporte des endpoints qui retournent du HTML quand ils devraient retourner du JSON, l'agent échoue silencieusement ou pire, invente des réponses.
L'API n'est plus une porte dérobée. C'est la porte d'entrée. Tout le budget produit qui allait autrefois polir l'UI doit maintenant aller polir le contrat : noms de champs clairs, exemples dans la doc, erreurs structurées, pagination cohérente, idempotence explicite. Un produit avec une mauvaise API mais une bonne UI pouvait encore se vendre à des humains. Un produit avec une mauvaise API dans un monde d'agents n'atteint pas la première intégration.
Pourquoi les agents IA cassent le paradigme UI-first
Les agents ne naviguent pas, ils invoquent des contrats typés
Un humain qui navigue découvre votre produit par le flux : il entre par la home, lit une feature, clique sur « commencer », remplit un formulaire, confirme par email. Chaque étape lui donne du contexte pour la suivante.
Un agent IA fait exactement l'inverse : il part d'une intention concrète (« réserve une réunion avec Marta jeudi »), énumère les outils disponibles, choisit celui qui convient le mieux, construit les paramètres et appelle. Il n'y a pas de flux. Il y a invocation directe. Cela signifie que chaque endpoint doit être autocontenu : sa description dans OpenAPI doit suffire à un modèle pour comprendre ce qu'il fait, quand l'utiliser et avec quels paramètres, sans avoir vu aucun écran préalable.
La conséquence architecturale est brutale. Les endpoints qui, dans une SPA, faisaient partie d'un flux guidé (« d'abord POST /cart, puis POST /cart/items, puis POST /checkout ») doivent être repensés ou explicitement documentés comme séquence, avec des erreurs qui indiquent clairement l'étape suivante. Les « étapes implicites » que l'humain faisait mentalement, c'est désormais le protocole qui doit les faire.
Le coût réel du scraping vs l'API bien conçue
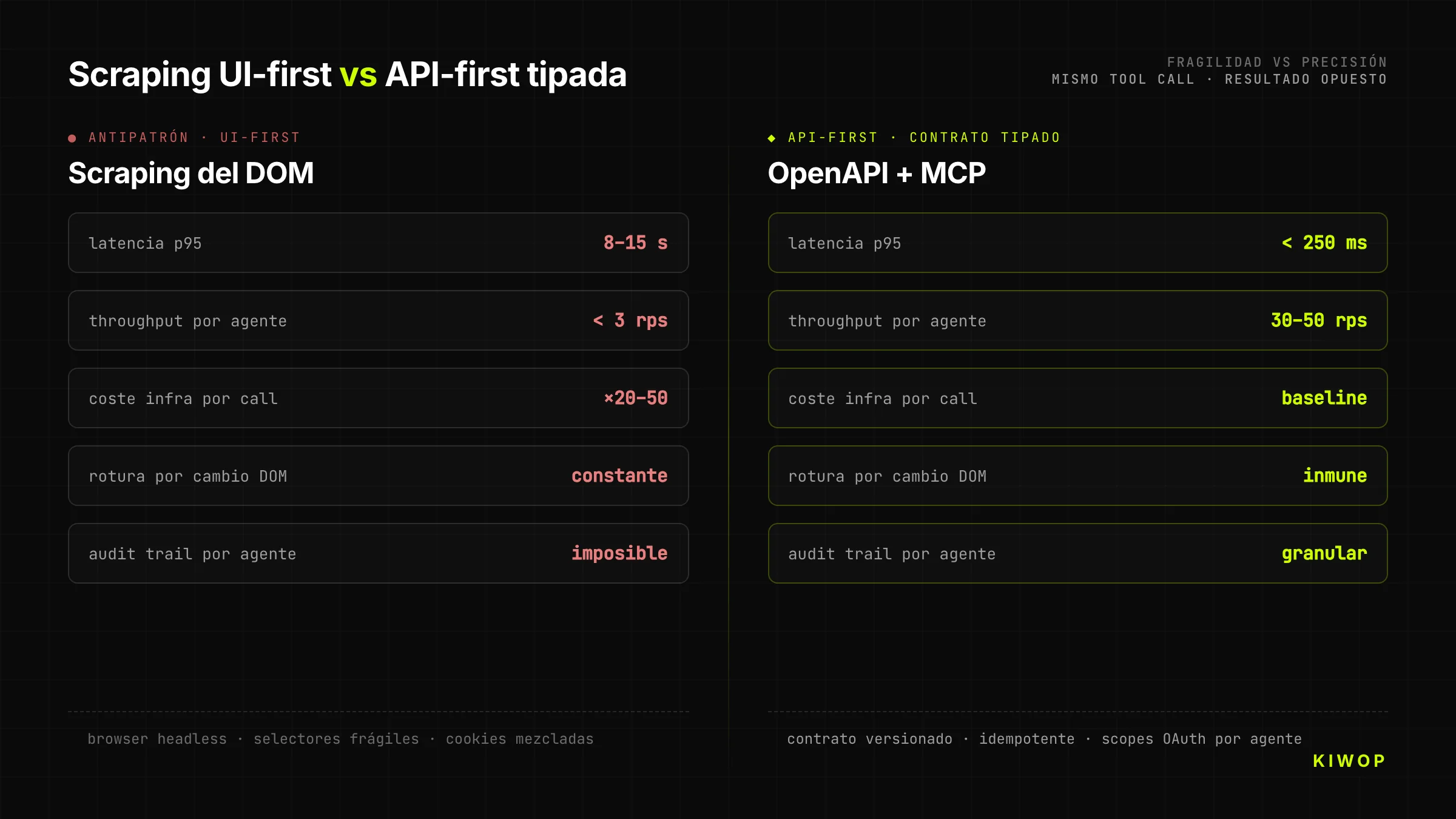
La tentation est évidente : puisque le site web existe et fonctionne, pourquoi construire une nouvelle API ? On met un browser-use ou un puppeteer devant et on laisse l'agent cliquer. C'est bon marché, rapide, sans toucher au backend. C'est aussi la décision qui détruit les projets.
Le scraping-as-backend a trois coûts qui n'apparaissent que des mois plus tard. Premièrement, c'est fragile : tout changement dans le DOM casse l'agent, et comme l'équipe frontend ne sait pas qu'il y a des agents qui dépendent du DOM, les changements sont constants. Deuxièmement, c'est lent : un tool call contre une API bien conçue se résout en 200-400 ms ; la même étape via browser prend 8-15 secondes à charger CSS, JS et à attendre que les sélecteurs apparaissent. Troisièmement, c'est cher : faire tourner un navigateur headless par requête multiplie par 20-50 le coût d'infrastructure par rapport à servir du JSON.
Une API conçue pour des agents coûte plus cher en phase de design, mais s'amortit dès la première intégration réelle. Les entreprises qui arrivent chez Kiwop après un an de « solution temporaire » avec scraping arrivent toujours avec le même symptôme : le coût de maintenance a rejoint le coût estimé pour construire l'API correctement dès le départ.
Le pivot de Salesforce après presque trois décennies
En février 2026, Marc Benioff, CEO de Salesforce, l'a dit sans détour : « APIs are the new UI ». Vingt-sept ans après avoir fondé une entreprise qui a défini ce qu'était « le SaaS », Salesforce reconnaît publiquement que le navigateur n'est plus le point de contact principal de son produit. Son focus se déplace vers des agents IA qui consomment directement ses données, ses workflows, ses tâches — via API.
Ce n'est pas une déclaration disruptive, c'est une confirmation tardive. Les entreprises qui construisent aujourd'hui de nouvelles plateformes tiennent déjà pour acquis que la première intégration réelle sera avec un agent, pas avec un humain. Le mouvement de Salesforce est le signal que même les incumbents les plus grands acceptent la même réalité. Si en 2028 un produit SaaS a encore sa meilleure DX derrière le navigateur, c'est qu'il arrivera en retard sur le cycle.
Les six principes d'une API-First prête pour les agents
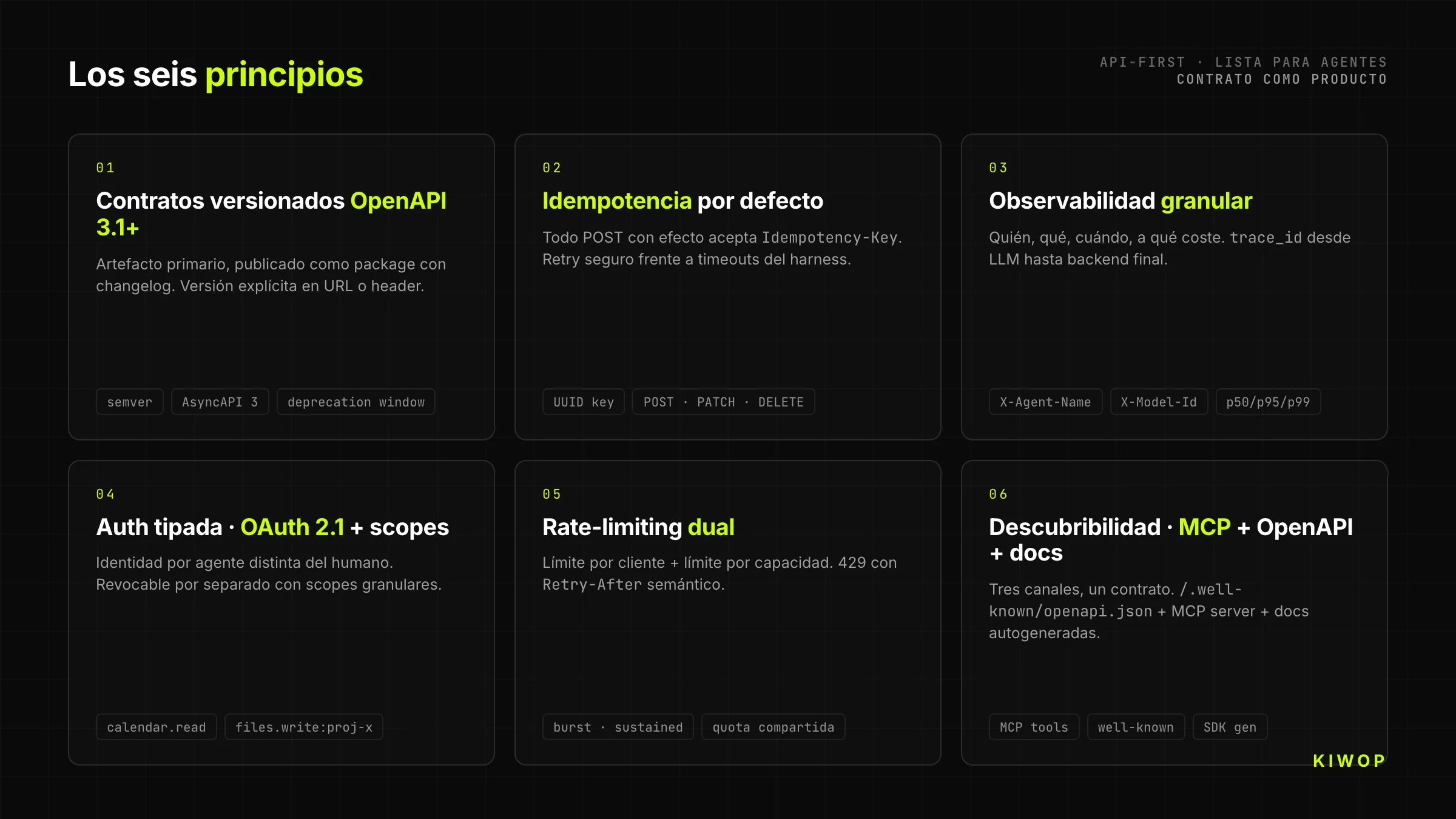
1. Contrats versionnés avec OpenAPI 3.1+
Toute API-First commence par un contrat OpenAPI 3.1 (ou AsyncAPI 3 pour l'event-driven) publié comme artefact versionné sémantiquement. Pas un PDF généré en fin de sprint. Pas un fichier flottant dans Confluence. Un package publié avec changelog, que n'importe quel consommateur peut figer sur une version concrète et mettre à jour avec intention.
La version va dans l'URL (/v2/...) ou dans le header (Accept-Version) ; peu importe le mécanisme pourvu qu'il soit explicite et que le serveur puisse servir deux versions en parallèle pendant la deprecation window. Pour les agents IA, c'est critique : un modèle appris sur la v1 de votre API ne doit pas casser parce que vous avez ajouté un champ en v2.
2. Idempotence par défaut
Les agents retrient. Beaucoup. À cause des timeouts, de la saturation de contexte, des politiques de retry du harness lui-même. Une API-First suppose l'idempotence comme contrat : tout POST qui génère un effet de bord accepte un header Idempotency-Key (UUID généré par le client) et garantit que deux appels avec la même key produisent un seul effet.
La règle s'étend aux PATCH, DELETE et opérations coûteuses. Sans idempotence, le premier timeout réseau crée une commande en double, un email envoyé deux fois ou une réservation dupliquée. Avec idempotence, l'agent peut retrier sereinement et votre logique métier ne dépend pas de la chance.
3. Observabilité granulaire : qui, quoi, quand, à quel coût
Quand le trafic principal n'est plus humain, les dashboards classiques (« utilisateurs actifs ») ne représentent plus rien. Ce qui compte, c'est : quel agent a appelé quel tool, avec quels paramètres, combien de temps il a pris, combien de tokens il a consommés dans le modèle qui l'a appelé, et si le résultat a été utile (l'agent a retryé ou a poursuivi).
Les headers User-Agent, X-Agent-Name, X-Model-Id sont désormais obligatoires, pas optionnels. Le logging structuré inclut un trace_id qui se propage depuis le LLM jusqu'au backend final. Et les métriques par tool — p50, p95, p99 de latence, taux d'erreur, taux de retry — sont l'équivalent nouveau des KPI produit.
4. Authentification typée : OAuth + scopes par agent
Chaque agent qui consomme votre API doit avoir sa propre identité distincte de celle de l'humain qui l'a autorisé. Cela s'implémente avec OAuth 2.1 + scopes granulaires : l'humain délègue à son agent un sous-ensemble explicite de permissions (calendar.read, calendar.write:2026-05, files.read:project-x), et chaque token reste traçable jusqu'à la paire (humain, agent, timestamp).
La conséquence pratique : deux agents du même humain sont deux identités distinctes. L'un peut être révoqué sans casser l'autre. Et les logs du backend peuvent répondre à la question que personne ne se posait il y a deux ans — « quel agent de quel humain a fait cette action à 3 h du matin ? ».
5. Rate-limiting double : par client et par capacité
Le rate-limiting classique (X requêtes par minute par token) ne fonctionne pas avec les agents car un agent bien fait peut générer des rafales légitimes de centaines de tool calls en quelques secondes pour accomplir une tâche complexe. L'API doit combiner deux limites : une limite par client (pour protéger l'agent des boucles) et une limite par capacité (pour protéger le backend de la somme de tous les agents).
Les erreurs 429 Too Many Requests doivent inclure Retry-After et distinguer clairement entre « réessaye dans 2 secondes » et « cette opération est bloquée pour toi pendant 10 minutes pour abus ». Cette différence est ce qui permet à l'agent de raisonner sur la façon de s'adapter.
6. Découvrabilité : MCP + OpenAPI + docs autogénérées
Une API-First moderne devrait être découvrable par trois canaux complémentaires. OpenAPI publié sur un endpoint prévisible (/.well-known/openapi.json) pour la consommation par les outils dev et les SDKs. MCP server exposant les mêmes capacités comme tools prêts à connecter avec Claude, ChatGPT ou n'importe quel agent qui parle le protocole. Et docs pour humains autogénérées à partir du même contrat, pour quand le developer de l'autre côté a besoin de regarder avec des yeux humains.
Les trois canaux consomment le même contrat. Si la docs et l'OpenAPI se désynchronisent, c'est qu'il y a quelque chose qui cloche architecturalement — le contrat n'est pas l'artefact primaire.
La couche spécifique aux agents — MCP, WebMCP, A2A
OpenAPI vous donne la base, mais pour qu'un agent consomme votre produit avec zéro friction, il existe une couche de protocoles spécifique. MCP (Model Context Protocol) est le standard pour exposer des tools à un agent qui tourne dans un harness (Claude, ChatGPT, Cursor). WebMCP fait la même chose depuis le navigateur, pour que votre web publique expose des actions à l'agent de l'utilisateur. A2A (Agent-to-Agent) orchestre la communication entre agents, pas entre agent et tools.
Ils ne concurrencent pas OpenAPI : ils le complètent. En production, OpenAPI est la vérité du backend ; MCP et WebMCP sont des adaptateurs fins qui traduisent ce contrat au format que les harnesses attendent. Nous couvrons la comparaison technique et quand utiliser chacun dans MCP, WebMCP et A2A : quel protocole choisir pour vos agents IA.
Patterns architecturaux qui fonctionnent
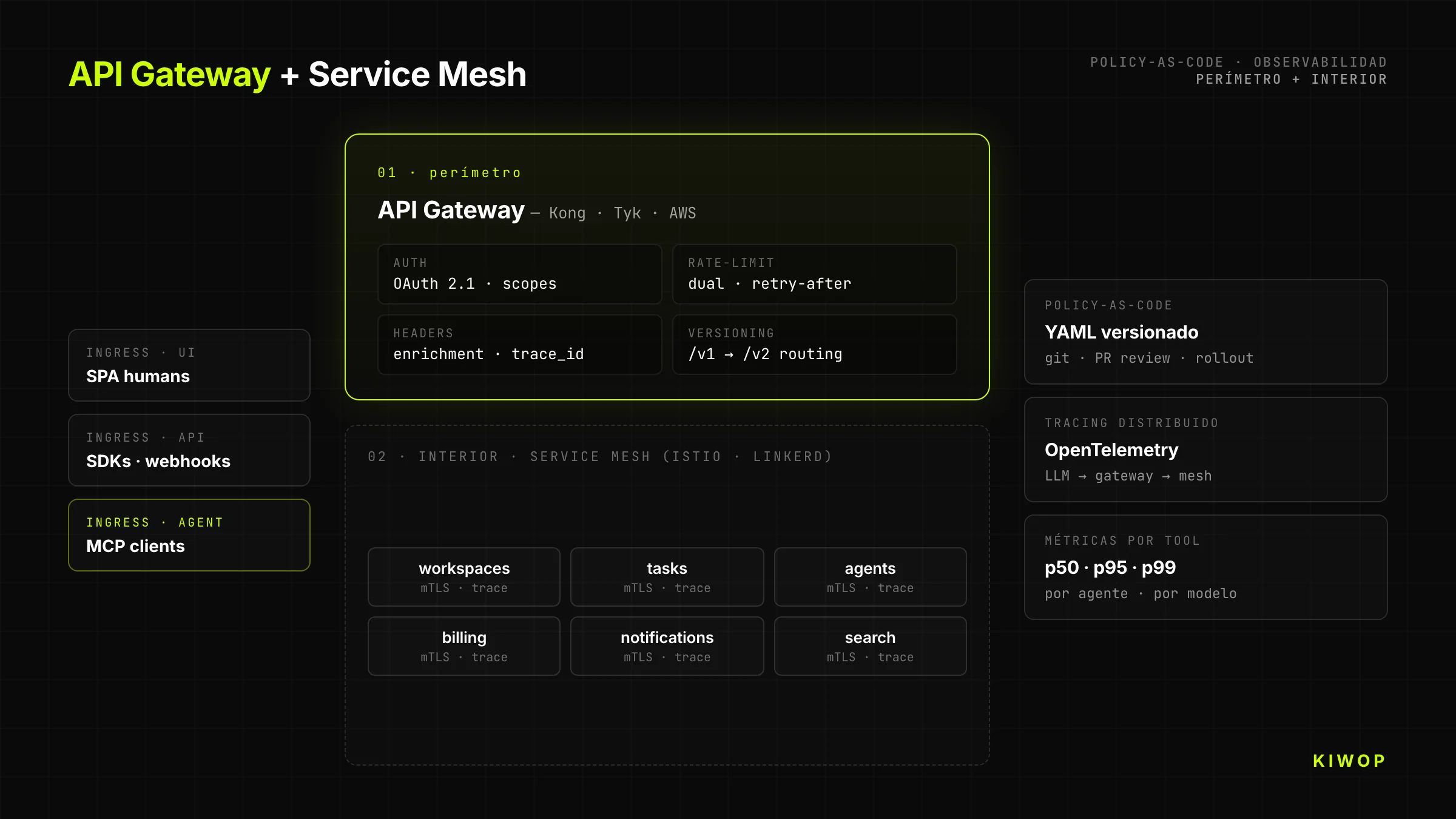
API Gateway + Service Mesh avec policy-as-code
Toute API-First sérieuse passe par un gateway qui applique des politiques avant d'atteindre le backend : authentification, rate-limiting, observabilité, enrichissement de headers, transformation entre versions. Notre stack recommandée : Kong, Tyk ou AWS API Gateway pour le périmètre ; Istio ou Linkerd pour le service mesh interne. Les politiques sont définies comme code (YAML versionné dans git), pas comme clics dans la console du vendor.
La séparation compte : le gateway se préoccupe de « quel client peut appeler quel endpoint » ; le mesh se préoccupe de « quel service peut parler à quel service à l'intérieur du cluster ». Mélanger les deux responsabilités est le chemin le plus court vers une architecture que personne ne comprend plus au bout de six mois.
Backend-for-Frontend ≠ Backend-for-Agent
Le pattern BFF (Backend-for-Frontend) est né pour que chaque UI (web, mobile, smart TV) ait son propre endpoint optimisé. La tentation est de l'appliquer aussi aux agents : construire un « BFA » (Backend-for-Agent) qui agrège les appels pour minimiser les round-trips.
Ne le faites pas sans y réfléchir à deux fois. Un agent n'est pas une UI avec une latence humaine ; c'est un client qui raisonne. Si vous agrégez trop, l'agent perd en granularité — il ne peut pas combiner les tools comme il le souhaite. Si vous agrégez trop peu, il gaspille du contexte en calls inutiles. La bonne décision dépend du cas : les tools de lecture peuvent bénéficier d'endpoints agrégés (GET /dashboard qui retourne utilisateur + permissions + dernières actions) ; les tools d'écriture doivent être atomiques et compositifs (POST /bookings isolé, sans side-effects cachés).
Event-driven avec Kafka, NATS ou Redis Streams
Les agents déclenchent des jobs qui prennent du temps. Générer un rapport, traiter une commande, entraîner un modèle — opérations de secondes à minutes. Les exposer comme REST synchrone oblige l'agent à maintenir la connexion et à consommer du contexte en attendant.
L'alternative est event-driven : l'agent envoie un POST /jobs qui retourne un job_id en moins de 100 ms, puis consulte l'état via GET /jobs/{id} ou s'abonne à un canal d'événements. Kafka ou NATS pour un volume élevé ; Redis Streams pour des setups légers. Le pattern libère l'agent du blocage et permet à votre backend d'absorber les pics sans tomber.
CQRS pour séparer l'écriture bruyante (agents) de la lecture critique (humains)
Quand les agents deviennent majoritaires dans le trafic d'écriture, les humains qui lisent le même produit commencent à souffrir de la contention : queries lentes, invalidations de cache constantes, dashboards qui tardent à charger. CQRS (Command Query Responsibility Segregation) sépare le modèle qui écrit du modèle qui lit : les agents envoient des commands vers un write-side optimisé pour la cohérence ; les humains consomment depuis un read-side optimisé pour la lecture rapide, alimenté par des événements depuis le write-side.
Ce n'est pas gratuit — cela ajoute de la complexité et de l'eventual consistency. Mais au-delà d'un certain volume de trafic agent, c'est la seule façon de maintenir intacte l'UX humaine.
Antipatterns qui tuent votre adoption par les agents
Antipattern 1 — Nous exposons l'UI avec cookies, « et voilà »
Le premier réflexe d'une équipe pressée est de déléguer à un browser-use ou Playwright les actions de l'agent. Ça marche en démo, ça échoue en production à la première rotation du DOM. Tout changement visuel du frontend (test A/B d'un bouton, refactor de sélecteurs) casse l'agent silencieusement. La dette est invisible jusqu'à ce qu'il soit trop tard — moment où le coût de reconstruire l'API « correctement » est triplé.
Antipattern 2 — APIs sans versioning explicite
Avoir une API en /api/... sans préfixe de version fonctionne jusqu'au premier changement breaking. À partir de là, tous les agents en production cassent en même temps. Les équipes qui misent sur « toujours backwards compatible » finissent par accumuler 15 ans de dette sur le même endpoint. La bonne discipline est un versioning dès le premier commit, avec des deprecation windows documentées dans le changelog.
Antipattern 3 — Docs écrites uniquement pour humains
De jolies pages sur Mintlify ou ReadMe avec des gifs et des tutoriels sont inutiles pour un agent. L'agent consomme de l'OpenAPI brut, du JSON Schema, des types TypeScript ou une description MCP. Si cet artefact lisible par machine n'existe pas ou est obsolète, l'agent invente. La docs humaine se génère à partir du contrat ; pas l'inverse.
Antipattern 4 — Authentification mélangée : session humaine + token agent sur le même endpoint
Une erreur fréquente dans les équipes qui migrent depuis des produits humains : réutiliser la session cookie de l'utilisateur pour que son agent appelle l'API « comme s'il était lui ». Résultat : impossible de distinguer qui fait quoi dans les logs, impossible de révoquer un agent sans tuer la session humaine, impossible de limiter des scopes distincts par origine.
La séparation correcte : session humaine avec cookie HttpOnly pour l'UI ; tokens OAuth avec scopes pour les agents ; chacun avec son propre endpoint d'authentification et son propre audit trail.
Cas réel — Nexo comme serveur MCP
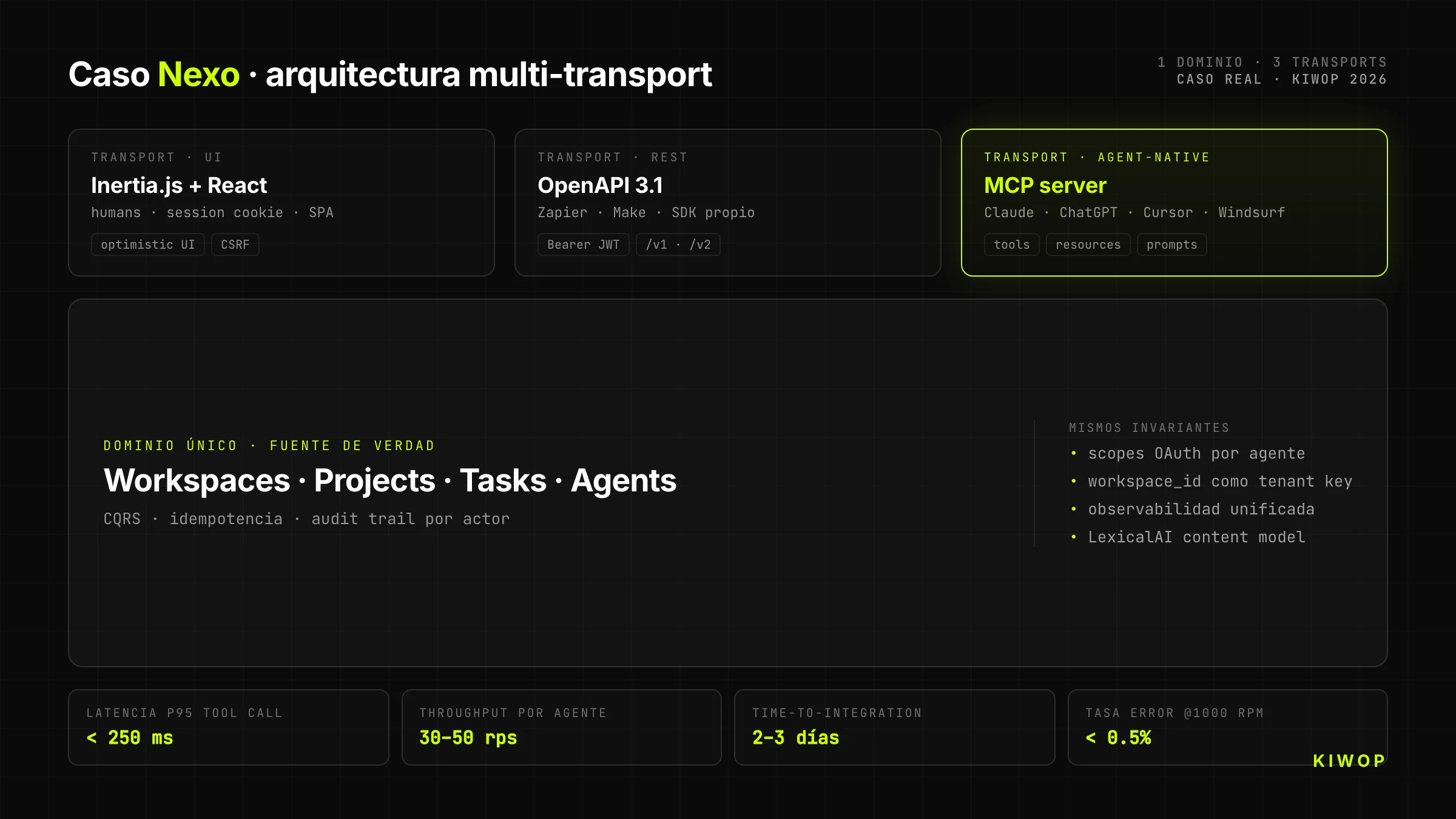
Nexo est notre SaaS propre de workspace pour équipes. Il a commencé comme une app Laravel + React + Inertia.js orientée humains (documentation technique : Nexo : anatomie technique de notre SaaS multi-tenant). Quand nous avons décidé de l'ouvrir aux agents IA, nous avons pris une décision architecturale qui a conditionné tout le reste : nous n'exposerions pas REST « et c'est tout » ; nous exposerions directement un serveur MCP au-dessus du même domaine qui servait déjà l'UI.
Architecture headless de Nexo
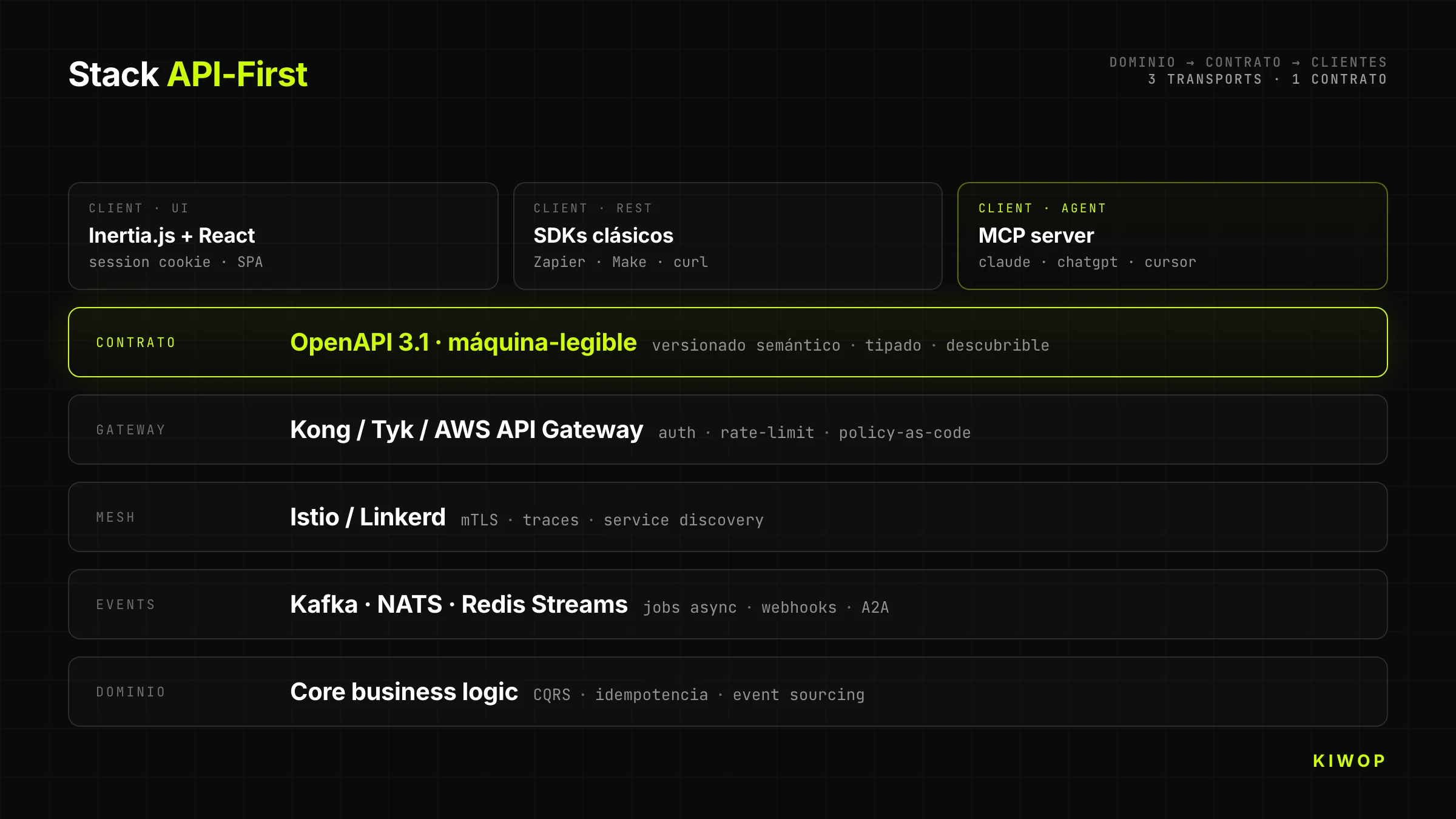
Le backend de Nexo a un seul domaine métier (workspaces, projets, tâches, notes, agents). Au-dessus de ce domaine tournent trois transports différents qui partagent le même contrat :
- Inertia.js + React pour l'UI humaine (session cookie, optimiste, client enrichi)
- REST + OpenAPI 3.1 pour les intégrations classiques (Zapier, Make, SDK propre)
- MCP server pour la consommation directe depuis Claude, ChatGPT et n'importe quel agent avec client MCP
Le domaine est le même. Ce qui change, c'est la couche de transport et l'identité du client. Cela signifie que quand un agent crée une tâche via MCP, cette tâche apparaît immédiatement dans l'UI humaine du même workspace, avec le bon utilisateur comme propriétaire et avec l'agent clairement étiqueté comme acteur.
Pourquoi MCP au lieu de REST « et c'est tout »
Nous aurions pu exposer uniquement REST et laisser chaque intégrateur construire son propre wrapper MCP. Nous avons choisi d'exposer MCP nativement pour trois raisons :
- Le contrat MCP capture l'intention mieux que REST générique. Un tool MCP se décrit avec un nom, une description, des paramètres typés et des exemples — le LLM n'a pas à deviner lequel parmi vingt endpoints REST utiliser ; il le voit littéralement.
- L'écosystème MCP grandit plus vite que n'importe quel SDK propriétaire. Claude, ChatGPT, Cursor, Windsurf, VS Code, Cline — tous parlent MCP. Si nous exposons MCP, tous nous consomment dès le premier jour.
- L'observabilité est gratuite. Les harnesses MCP reportent déjà quel tool a été appelé et avec quel résultat. Nous économisons la construction de notre propre dashboard d'adoption par agent.
Métriques cibles (projections de design)
Les chiffres suivants sont des objectifs de design calibrés contre des implémentations comparables, pas encore des lectures en production à grande échelle. Nous les publions comme référence de ce qu'il est raisonnable d'attendre d'une architecture MCP-first bien faite :
Valeurs calibrées lors de tests internes et face à la littérature comparable ; elles seront affinées avec les données de production à mesure que nous passerons à l'échelle.
Leçons de première main
Ce que nous savons déjà après avoir conçu et opéré la couche MCP de Nexo, et qui n'était dans aucun paper quand nous avons commencé :
- Le coût architectural réel n'est pas d'écrire MCP ; c'est de refactorer votre backend pour que les endpoints soient granulaires, idempotents et compositifs. Le MCP server en soi fait ~600 lignes de TypeScript. Ce qui est dur, c'est que votre couche métier tienne face à ce que les agents lui demandent.
- L'audit trail par agent change les conversations avec les clients. Quand un client B2B voit dans son dashboard « ton agent Claude a changé le statut de 14 tâches vendredi », la conversation passe de « puis-je faire confiance à ça ? » à « je veux donner accès à plus d'agents ».
- Les scopes OAuth granulaires se vendent. La première objection technique en vente était toujours « et si l'agent se déchaîne ? ». Avoir une réponse typée — « cet agent ne peut que lire le projet X jusqu'au 31 mai » — débloque la signature.
Quand NE PAS migrer vers API-First
La migration vers API-First est coûteuse et ne compense pas toujours. Trois cas dans lesquels notre recommandation honnête est de ne pas le faire :
- Produit sans cas d'usage agentic réel. Si votre produit est un ERP interne utilisé par 30 employés et qu'aucun ne va construire d'agents, une migration API-first ne vous donnera pas de ROI. Investissez ailleurs.
- Volume insuffisant pour amortir l'overhead. Si votre trafic total est de 100 requêtes par jour, la complexité ajoutée (gateway, versioning, OpenAPI strict, MCP) pèse plus que le bénéfice. Validez d'abord qu'il y a de la demande.
- Équipe sans maturité DevEx. API-First exige une culture du contrat comme produit : changelog discipliné, tests de contract, SLA documentés. Sans cette culture, le contrat se désynchronise en six mois et tout le travail est perdu. Avant de migrer, investissez dans la culture.
Si vous tombez dans l'un des trois cas, mieux vaut continuer avec votre stack actuel et y revenir dans un an.
Roadmap de migration — par où commencer
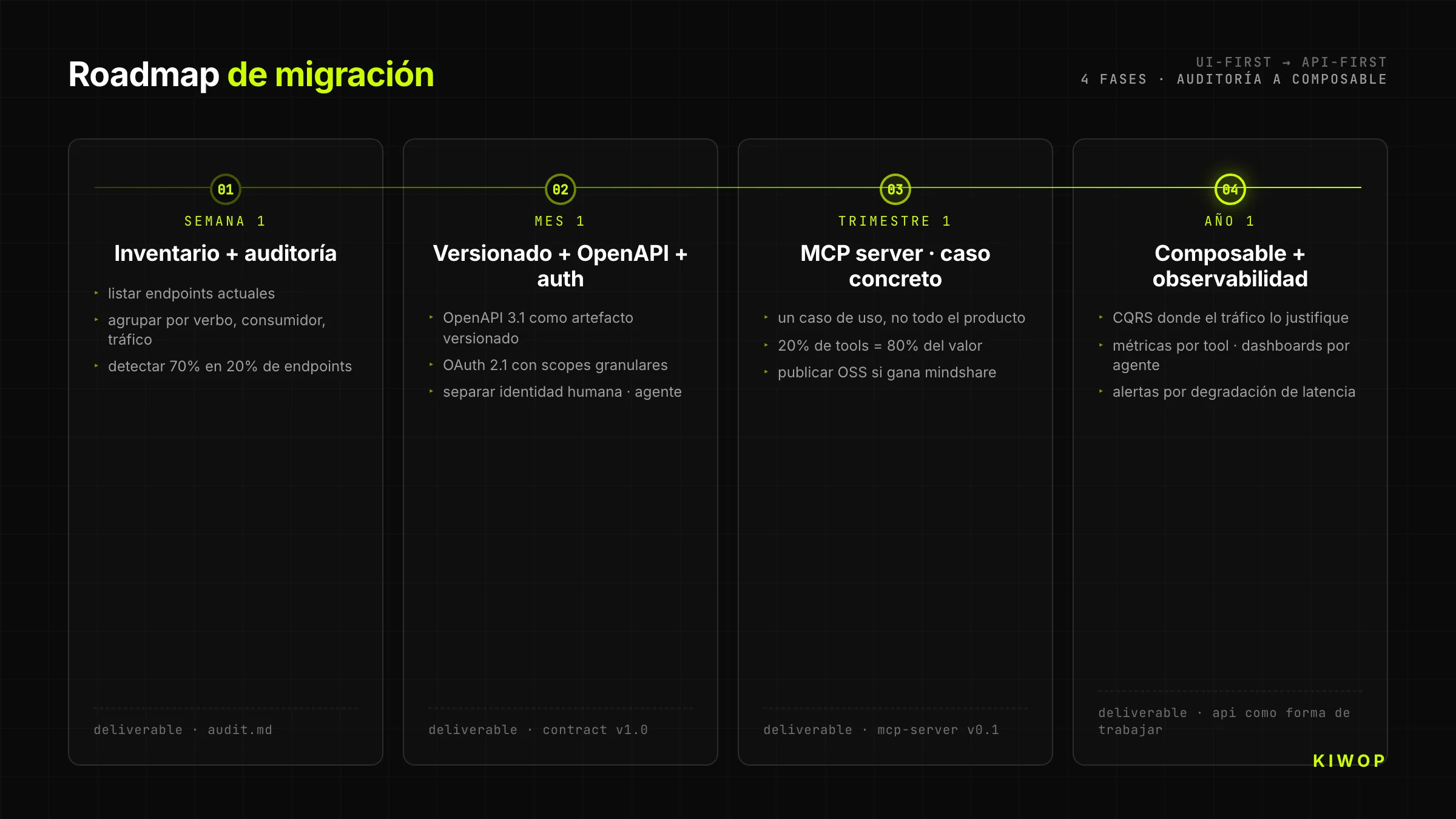
Semaine 1 — Inventaire et audit
Listez tous les endpoints actuels de votre backend. Regroupez-les par verbe HTTP, par consommateur (web, mobile, interne), par fréquence d'usage. Marquez ceux qui ont un versioning explicite, ceux qui retournent des erreurs structurées, ceux qui ont de l'idempotence. Cet audit révèle en général que 70 % du code vit dans 20 % des endpoints — ce sont les candidats prioritaires à convertir en API-first.
Mois 1 — Versioning + OpenAPI + auth propre
Publiez OpenAPI 3.1 comme artefact versionné pour les endpoints critiques. Migrez l'authentification vers OAuth 2.1 avec scopes granulaires. Séparez l'identité humaine de l'identité agent. N'essayez pas de tout réécrire ; commencez par un domaine circonscrit (par exemple, juste le module « réservations » ou « factures ») et traitez-le comme preuve.
Trimestre 1 — MCP server pour un cas d'usage
Choisissez un cas d'usage concret et construisez un MCP server qui l'expose. N'essayez pas de couvrir tout le produit ; couvrez les 20 % d'outils qui génèrent 80 % de la valeur. Publiez le MCP server en open-source si cela a du sens (gagnez du mindshare), ou fermé mais documenté.
Année 1 — Composable + observabilité complète
Migrez le reste du backend vers le modèle composable. Implémentez CQRS là où le trafic d'écriture agent le justifie. Instrumentez les métriques par tool, les dashboards d'adoption par agent, les alertes de dégradation de latence. À ce stade, l'architecture API-First cesse d'être un projet et devient la façon de travailler de l'équipe.
Questions fréquentes
Qu'est-ce qu'API-First en une ligne ?
Une architecture dans laquelle le contrat lisible par machine est conçu, versionné et publié avant toute interface humaine qui le consomme.
Est-ce la même chose que headless ?
Non. Headless signifie « sans couche de présentation couplée au backend » — c'est une propriété structurelle. API-First est une discipline de design : le contrat vient en premier. Toute architecture API-First est headless, mais toute headless n'est pas API-First (vous pouvez avoir du headless avec un contrat médiocre).
Ai-je besoin de MCP si j'ai déjà REST ?
Pas strictement, mais MCP accélère brutalement l'adoption par les agents. Si vos clients vont consommer votre produit via Claude, ChatGPT ou Cursor, exposer MCP nativement leur évite de construire leur propre adaptateur. La couverture technique est dans MCP, WebMCP et A2A : protocoles pour agents IA.
Comment monétise-t-on une API consommée par des agents ?
Le modèle classique (prix par utilisateur) ne colle pas — un agent n'est pas un utilisateur. Les modèles qui fonctionnent : prix par volume (requêtes ou tokens consommés), prix par valeur livrée (nombre d'actions complétées), prix par agent connecté (licence par bot). Certaines plateformes facturent par tier d'agent selon la criticité.
Combien coûte la migration de UI-First à API-First ?
Cela dépend du point de départ, mais une migration honnête pour une plateforme SaaS moyenne (50-200 endpoints) se situe entre 3 et 9 mois avec une équipe dédiée. Le coût principal n'est pas technique mais culturel — s'accorder sur le fait que le contrat est l'artefact primaire.
Que devient mon SEO si je n'ai plus d'UI ?
API-First ne signifie pas éliminer l'UI publique. L'UI reste pour les humains et le SEO ; ce que vous ajoutez, c'est la couche API/MCP pour les agents. L'intéressant, c'est qu'avec WebMCP vous pouvez exposer des actions directes aux agents IA qui visitent votre web, ce qui ouvre de nouvelles surfaces d'acquisition.
Conclusion
Une architecture API-First n'est pas un luxe technique ni une mode ; c'est la façon de construire un produit quand le consommateur principal n'est plus un humain mais un agent. Le pivot public de Salesforce en 2026 est la confirmation tardive de quelque chose que les équipes qui construisent aujourd'hui tiennent déjà pour acquis : l'API est la porte d'entrée et l'UI est un client parmi d'autres.
Chez Kiwop — Agence digitale spécialisée en Développement logiciel et Intelligence artificielle appliquée pour clients globaux en Europe et aux États-Unis — nous avons construit Nexo avec ce modèle dès le premier jour, et nous aidons les équipes techniques à diagnostiquer leur architecture actuelle et à tracer le chemin le plus court vers API-First sans casser ce qui fonctionne déjà. Si vous envisagez la migration, demandez un audit d'architecture API-first ou jetez un œil à nos services de développement d'agents IA, conseil en intelligence artificielle et intégration de LLM.
Et si la direction technique vous intéresse, poursuivez le fil avec les posts du cluster : MCP, WebMCP et A2A : protocoles pour agents IA, agents IA en production : patterns et antipatterns, Nexo : anatomie technique de notre SaaS multi-tenant et de OpenClaw à PA avec Claude Code et MCP.


