By the Kiwop team · Digital agency specialized in Software Development and Applied Artificial Intelligence for global clients across Europe and USA · Published April 20, 2026 · Last updated: April 20, 2026
TL;DR — An API-First architecture designs the system from its machine-readable contracts before any human interface. When the primary consumer is no longer a browser and becomes an AI agent, that separates products that survive from those that don't. This guide covers the six principles, the patterns that work, the four antipatterns that kill adoption, and the real case of Nexo — our SaaS that exposes MCP as a native contract.
 AI agents — diagram of Kiwop's headless stack with MCP, OpenAPI, API Gateway and event-driven" width="800" height="450" loading="lazy" />
AI agents — diagram of Kiwop's headless stack with MCP, OpenAPI, API Gateway and event-driven" width="800" height="450" loading="lazy" />Every week the same call comes in from a technical committee: "We want to open our product to AI agents, but our backend was designed for a SPA". The honest answer is never "just set up a REST endpoint and you're done". The correct answer starts with a question: is your architecture designed for the primary consumer to be a machine, or a human with a mouse? If it's the latter, every new agent you connect will pay the mismatch tax — latency, fragile scraping, poorly handled retries, accounts shared between humans and bots. API-First is not a coding style; it's the architectural decision that eliminates that tax from day one.
What API-First architecture is (operational definition)
An API-First architecture is one in which every machine-readable contract — its shape, its version, its authentication, its observability — is designed and validated before any user interface that consumes it. The backend does not expose "what the SPA needs today"; it exposes a public, typed, versioned, documented and discoverable contract from which any client (web, mobile, third parties, AI agents) consumes what it needs.
The key distinction is not technical but sequential. In API-First, the contract is the primary artifact — it is reviewed in PR, published as OpenAPI or AsyncAPI, versioned as an independent library. The UI comes later and the agent comes later. They are all clients of the same first-class citizen.
API-First vs API-Design-First vs Code-First
Three terms used interchangeably that mean different things:
- Code-First: code comes first. The contract (OpenAPI, gRPC, GraphQL schema) is generated from the code. Fast to start, expensive to maintain. The contract is always one step behind.
- API-Design-First: the contract is designed as a human-readable document before writing code. Useful for coordinating large teams, but doesn't guarantee that the primary consumer is a machine.
- API-First: the machine-readable contract is the artifact first, last and always. It's designed as a product with its own roadmap, SLA, changelog and support. The UI is just another client.
Our recommendation for any platform that wants to expose itself to AI agents: API-First with API-Design-First as a team ritual. The contract lives in its own repo or package, is reviewed in PR, and is published semantically versioned.
Why with AI agents the API IS the UI
Historically the UI was the product and the API was an extra. Companies invested in interaction design, A/B testing of buttons, visual onboarding flows. The API existed as a backdoor for integrations or SDKs, but the product budget was on the screen.
With AI agents that hierarchy flips. An agent doesn't see your header, doesn't click your CTA, doesn't appreciate your loading animation. All it sees is the contract — and if the contract is ambiguous, poorly versioned or has endpoints that return HTML when they should return JSON, the agent silently fails or, worse, hallucinates responses.
The API is no longer a backdoor. It's the front door. All the product budget that used to go to polishing the UI must now go to polishing the contract: clear field names, examples in docs, structured errors, consistent pagination, explicit idempotency. A product with a bad API but a good UI could still be sold to humans. A product with a bad API in a world of agents won't even make it to the first integration.
Why AI agents break the UI-first paradigm
Agents don't navigate, they invoke typed contracts
A human navigating discovers your product by the flow: lands on the home, reads a feature, clicks "get started", fills out a form, confirms by email. Each step provides context for the next.
An AI agent does exactly the opposite: it starts from a concrete intent ("book a meeting with Marta on Thursday"), enumerates available tools, picks the one that best fits, builds the parameters and calls. There's no flow. There's direct invocation. That means every endpoint has to be self-contained: its description in OpenAPI must be enough for a model to understand what it does, when to use it and with what parameters, without having seen any previous screen.
The architectural consequence is brutal. Endpoints that in a SPA were part of a guided flow ("first POST /cart, then POST /cart/items, then POST /checkout") must be rethought or explicitly documented as a sequence, with errors that make the next step clear. The "implicit steps" that the human made mentally now have to be made by the protocol.
The real cost of scraping vs a well-designed API
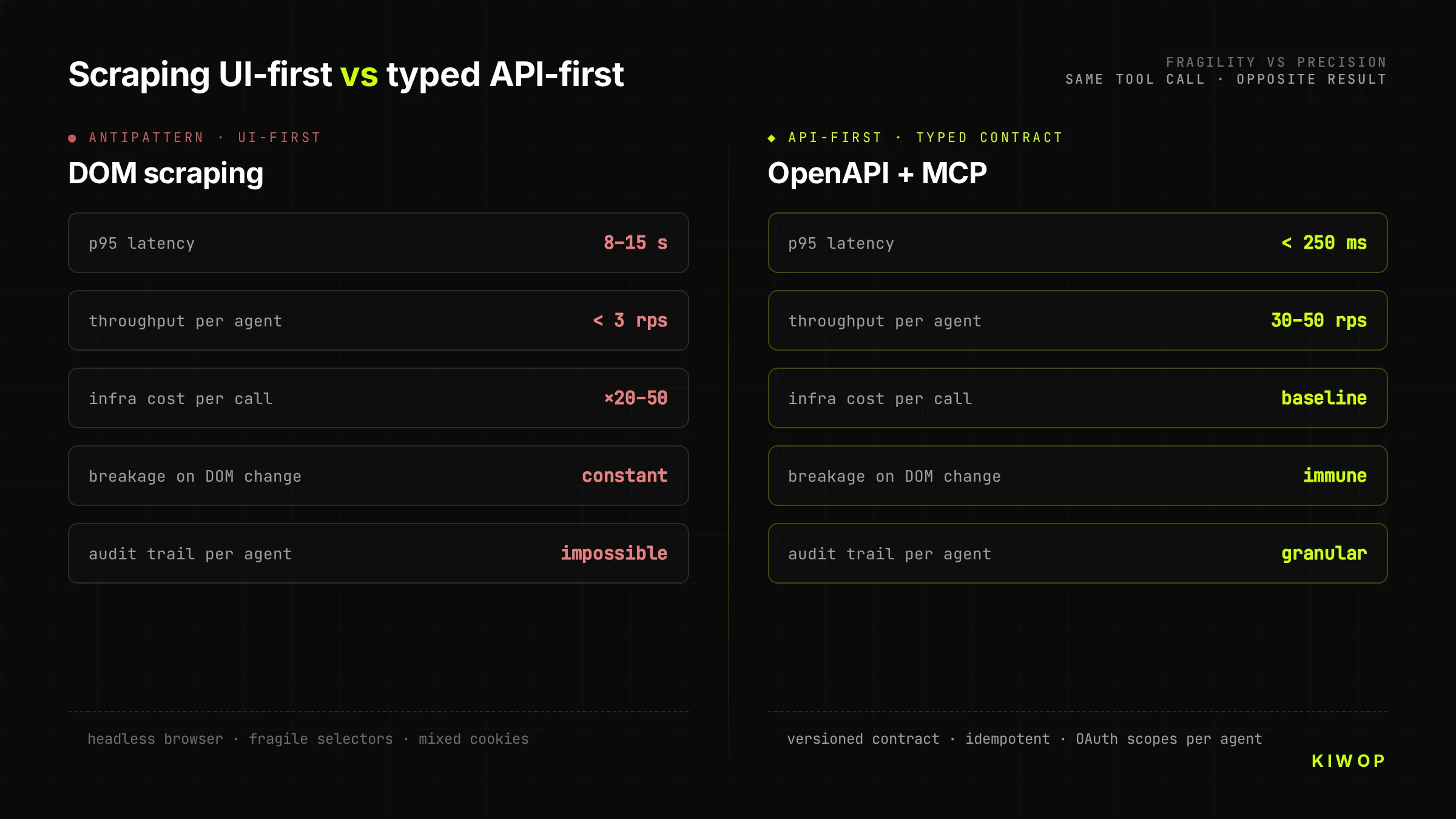
The temptation is obvious: since the website exists and works, why build a new API? We put a browser-use or a puppeteer in front and let the agent click around. It's cheap, fast, doesn't require touching the backend. It's also the decision that destroys projects.
Scraping-as-backend has three costs that don't show up until months later. First, it's fragile: any DOM change breaks the agent, and since the frontend team doesn't know there are agents depending on the DOM, changes are constant. Second, it's slow: a tool call against a well-designed API resolves in 200-400 ms; the same step via browser takes 8-15 seconds loading CSS, JS and waiting for selectors to appear. Third, it's expensive: running a headless browser per request multiplies infrastructure cost by 20-50x vs serving JSON.
An API designed for agents costs more in the design phase, but it pays off on the first real integration. Companies that come to Kiwop with a year of "temporary scraping solution" always arrive with the same symptom: maintenance cost has matched the estimated cost of building the API properly from the start.
Salesforce's pivot after nearly three decades
In February 2026, Marc Benioff, CEO of Salesforce, said it without hedging: "APIs are the new UI". Twenty-seven years after founding a company that defined what "SaaS" was, Salesforce publicly acknowledges that the browser is no longer the primary touchpoint of its product. Their focus is shifting to AI agents consuming their data, their workflows, their tasks directly — via API.
It's not a disruptive statement, it's a late confirmation. Companies building new platforms today already assume the first real integration will be with an agent, not a human. Salesforce's move is the signal that even the largest incumbents are accepting the same reality. If in 2028 a SaaS product still has its best DX behind the browser, it's because it will arrive late to the cycle.
The six principles of an API-First ready for agents
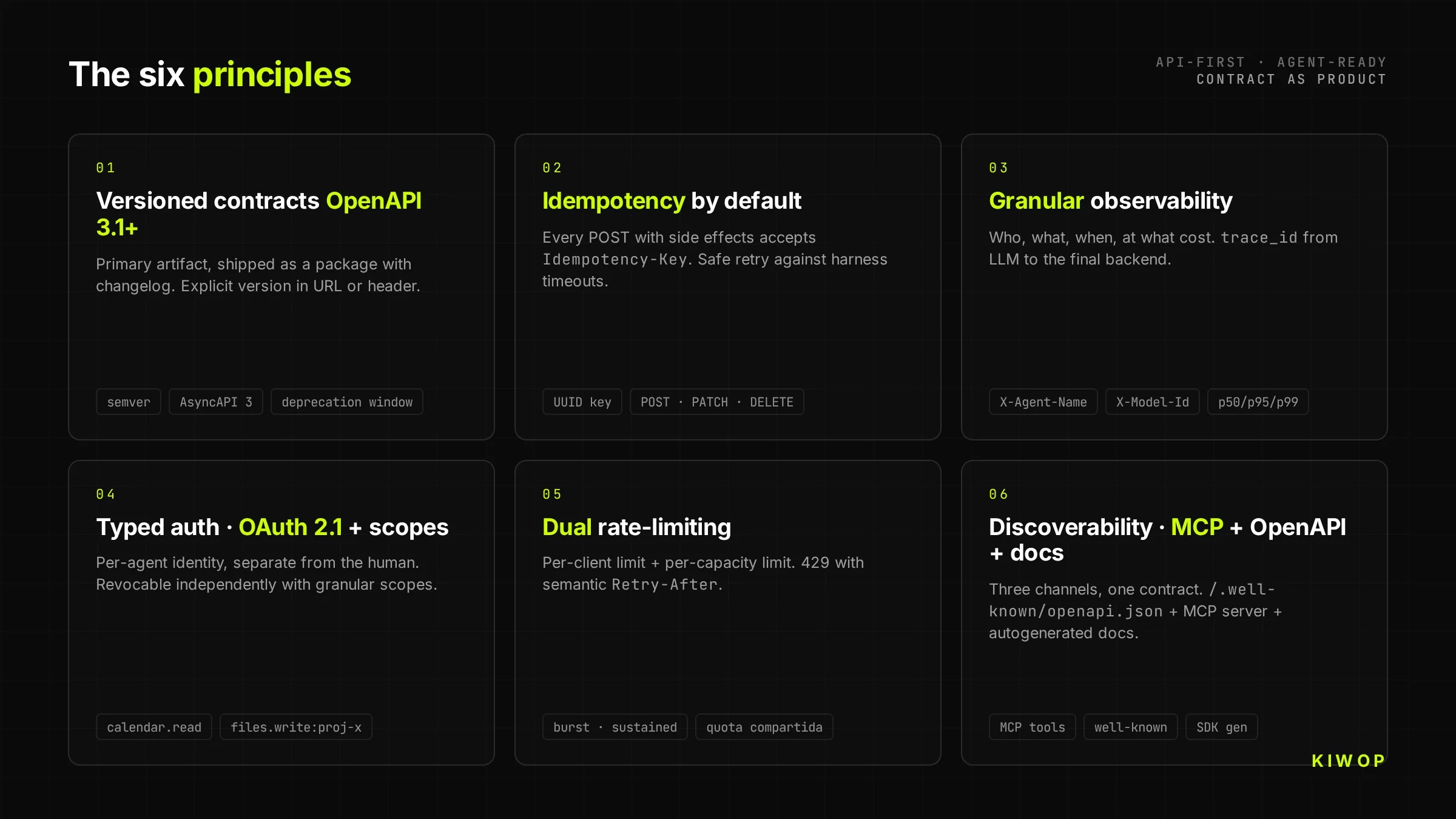
1. Versioned contracts with OpenAPI 3.1+
Every API-First starts with an OpenAPI 3.1 contract (or AsyncAPI 3 for event-driven) published as a semantically versioned artifact. Not as a PDF generated at the end of the sprint. Not as a floating file on Confluence. As a published package with changelog, that any consumer can pin to a specific version and upgrade intentionally.
The version goes in the URL (/v2/...) or in the header (Accept-Version); the mechanism doesn't matter as long as it's explicit and the server can serve two versions in parallel during the deprecation window. For AI agents this is critical: a model trained on v1 of your API shouldn't break because you've added a field in v2.
2. Idempotency by default
Agents retry. A lot. Because of timeouts, context saturation, retry policies of the harness itself. An API-First assumes idempotency as a contract: every POST that produces a side effect accepts an Idempotency-Key header (UUID generated by the client) and guarantees that two calls with the same key produce a single effect.
The rule extends to PATCH, DELETE and expensive operations. Without idempotency, the first network timeout creates a duplicate order, an email sent twice or a duplicated booking. With idempotency, the agent can retry calmly and your business logic doesn't depend on luck.
3. Granular observability: who, what, when, at what cost
When the primary traffic stops being human, classic dashboards ("active users") no longer represent anything. What matters is: which agent called which tool, with what parameters, how long it took, how many tokens the calling model consumed, and whether the result was useful (did the agent retry or move on).
The headers User-Agent, X-Agent-Name, X-Model-Id are now mandatory, not optional. Structured logging includes a trace_id that propagates from the LLM down to the backend. And per-tool metrics — p50, p95, p99 latency, error rate, retry rate — are the new equivalent of product KPIs.
4. Typed authentication: OAuth + scopes per agent
Every agent consuming your API must have its own identity, distinct from that of the human who authorized it. This is implemented with OAuth 2.1 + granular scopes: the human delegates to their agent an explicit subset of permissions (calendar.read, calendar.write:2026-05, files.read:project-x), and each token is traceable down to the tuple (human, agent, timestamp).
The practical consequence: two agents of the same human are two different identities. One can be revoked without breaking the other. And the backend logs can answer the question no one was asking two years ago — "which agent of which human performed this action at 3 a.m.?".
5. Dual rate-limiting: per client and per capacity
Classic rate-limiting (X requests per minute per token) doesn't work with agents because a well-built agent can generate legitimate bursts of hundreds of tool calls in seconds to complete a complex task. The API must combine two limits: a per-client limit (to protect the agent from loops) and a per-capacity limit (to protect the backend from the sum of all agents).
429 Too Many Requests errors must include Retry-After and clearly distinguish between "try again in 2 seconds" and "this operation is blocked for you for 10 minutes due to abuse". That difference is what allows the agent to reason about how to adapt.
6. Discoverability: MCP + OpenAPI + auto-generated docs
A modern API-First should be discoverable through three complementary channels. OpenAPI published at a predictable endpoint (/.well-known/openapi.json) for consumption by dev tools and SDKs. MCP server exposing the same capabilities as tools ready to connect with Claude, ChatGPT or any agent that speaks the protocol. And human-facing docs auto-generated from the same contract, for when the developer on the other side needs to look with human eyes.
The three channels consume the same contract. If the docs and the OpenAPI drift apart, it's because something is architecturally wrong — the contract is not the primary artifact.
The agent-specific layer — MCP, WebMCP, A2A
OpenAPI gives you the baseline, but for an agent to consume your product with zero friction there's a layer of specific protocols. MCP (Model Context Protocol) is the standard for exposing tools to an agent running in a harness (Claude, ChatGPT, Cursor). WebMCP does the same from the browser, so that your public website exposes actions to the user's agent. A2A (Agent-to-Agent) orchestrates communication between agents, not between agent and tools.
They don't compete with OpenAPI: they complement it. In production, OpenAPI is the truth of the backend; MCP and WebMCP are thin adapters that translate that contract to the format harnesses expect. We cover the technical comparison and when to use each in MCP, WebMCP and A2A: which protocol to choose for your AI agents.
Architectural patterns that work
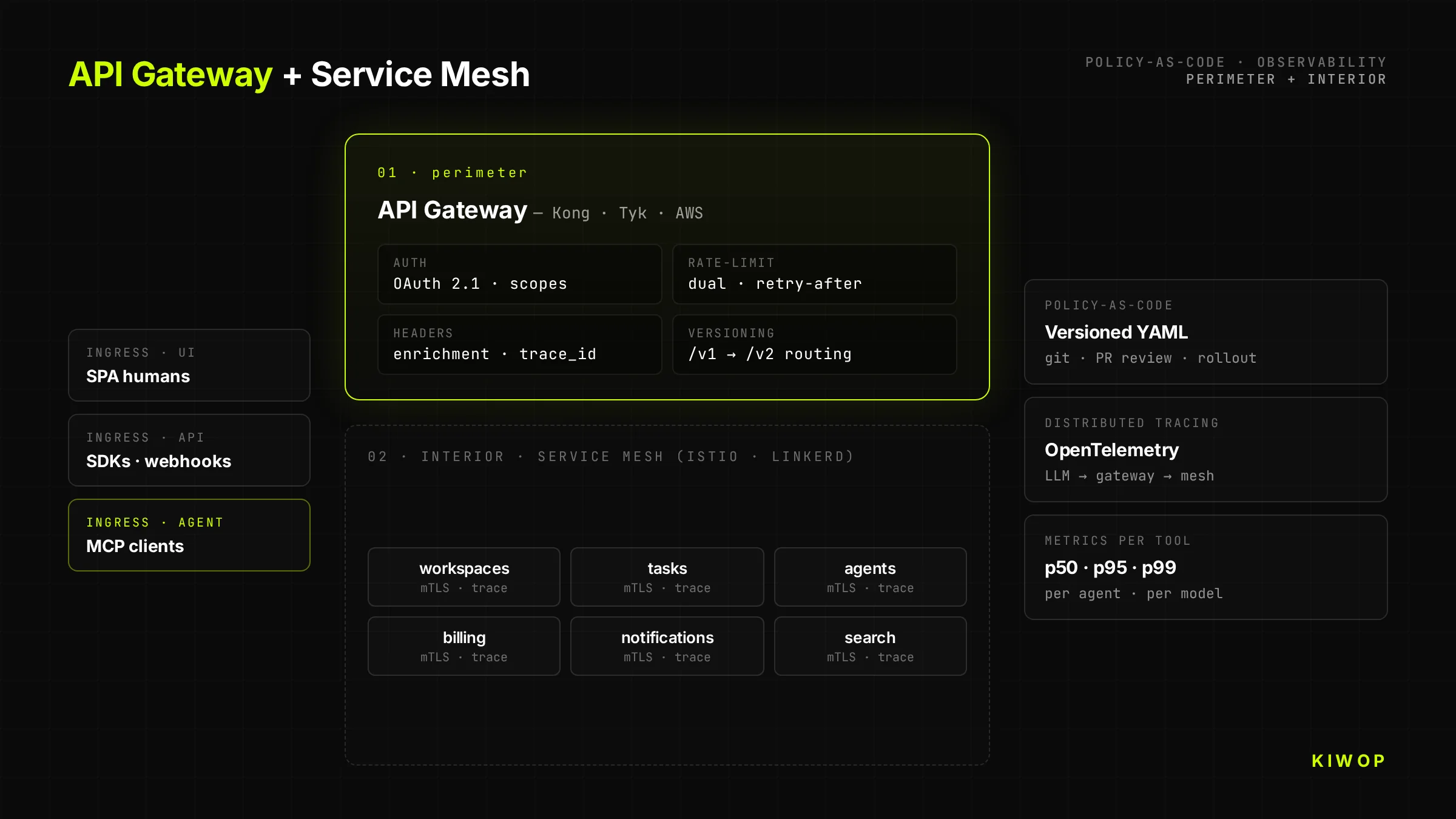
API Gateway + Service Mesh with policy-as-code
Every serious API-First goes through a gateway that applies policies before reaching the backend: authentication, rate-limiting, observability, header enrichment, transformation between versions. Our recommended stack: Kong, Tyk or AWS API Gateway for the perimeter; Istio or Linkerd for the internal service mesh. Policies are defined as code (YAML versioned in git), not as clicks in the vendor console.
The separation matters: the gateway worries about "which client can call which endpoint"; the mesh worries about "which service can talk to which service inside the cluster". Mixing the two responsibilities is the shortest path to an architecture nobody understands in six months.
Backend-for-Frontend ≠ Backend-for-Agent
The BFF (Backend-for-Frontend) pattern was born so that each UI (web, mobile, smart TV) had its own optimized endpoint. The temptation is to also apply it to agents: build a "BFA" (Backend-for-Agent) that aggregates calls to minimize round-trips.
Don't do it without thinking twice. An agent is not a UI with human latency; it's a client that reasons. If you aggregate too much, the agent loses granularity — it can't combine tools as it wants. If you aggregate too little, it wastes context on unnecessary calls. The right decision depends on the case: read tools can benefit from aggregated endpoints (GET /dashboard returning user + permissions + recent actions); write tools should be atomic and composable (POST /bookings isolated, with no hidden side-effects).
Event-driven with Kafka, NATS or Redis Streams
Agents trigger long-running jobs. Generating a report, processing an order, training a model — operations that take seconds to minutes. Exposing them as synchronous REST forces the agent to hold the connection and consume context waiting.
The alternative is event-driven: the agent sends a POST /jobs that returns a job_id in under 100 ms, then polls status via GET /jobs/{id} or subscribes to an event channel. Kafka or NATS for high volume; Redis Streams for lighter setups. The pattern frees the agent from blocking and allows your backend to absorb spikes without falling over.
CQRS to separate noisy writes (agents) from critical reads (humans)
When agents become the majority of write traffic, humans reading the same product start to suffer contention: slow queries, constant cache invalidations, dashboards that take forever to load. CQRS (Command Query Responsibility Segregation) separates the write model from the read model: agents send commands to a write-side optimized for consistency; humans consume from a read-side optimized for fast reads, fed by events from the write-side.
It's not free — it adds complexity and eventual consistency. But above a certain agent traffic volume, it's the only way to keep human UX intact.
Antipatterns that kill your agent adoption
Antipattern 1 — We expose the UI with cookies, "and we're done"
The first reflex of a pressured team is to delegate the agent's actions to a browser-use or Playwright. It works in the demo, fails in production at the first DOM rotation. Any visual change to the frontend (A/B test of a button, refactor of selectors) silently breaks the agent. The debt is invisible until it's too late — at which point the cost of rebuilding the API "properly" is triple.
Antipattern 2 — APIs without explicit versioning
Having an API at /api/... without a version prefix works until the first breaking change. From that moment, all agents in production break at once. Teams betting on "always backwards compatible" end up accumulating 15 years of debt in the same endpoint. The correct discipline is versioning from the first commit, with deprecation windows documented in the changelog.
Antipattern 3 — Docs written only for humans
Pretty pages on Mintlify or ReadMe with gifs and tutorials are useless to an agent. The agent consumes raw OpenAPI, JSON Schema, TypeScript types or an MCP description. If that machine-readable artifact doesn't exist or is out of date, the agent hallucinates. The human docs are generated from the contract; not the other way around.
Antipattern 4 — Mixed authentication: human session + agent token on the same endpoint
A common mistake in teams migrating from human products: reusing the user's cookie session so their agent calls the API "as if it were them". Result: impossible to distinguish who does what in the logs, impossible to revoke an agent without killing the human session, impossible to limit different scopes per origin.
The correct separation: human session with HttpOnly cookie for the UI; OAuth tokens with scopes for agents; each one with its own authentication endpoint and its own audit trail.
Real case — Nexo as an MCP server
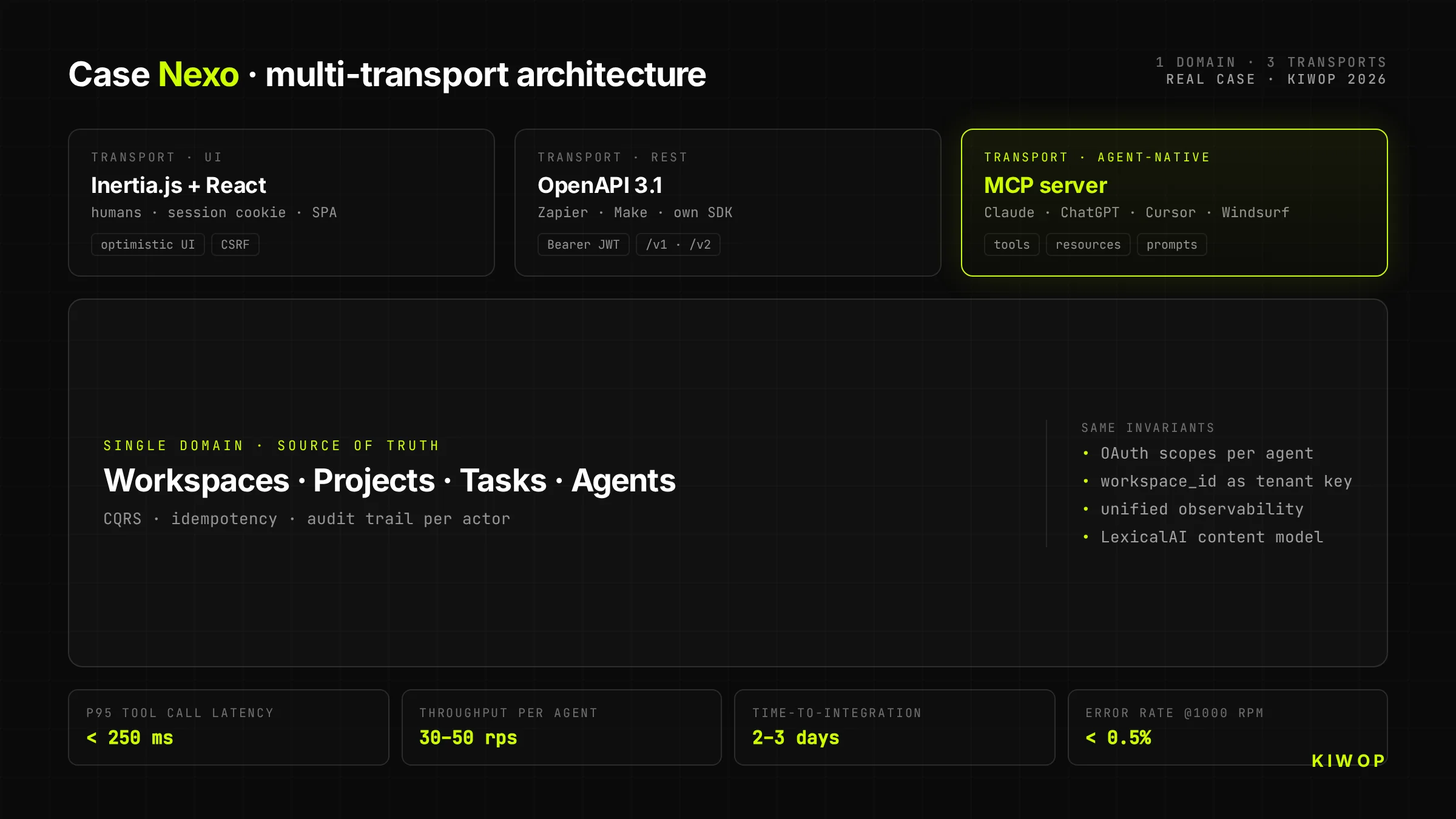
Nexo is our own workspace SaaS for teams. It started as a Laravel + React + Inertia.js app oriented toward humans (technical documentation: Nexo: technical anatomy of our multi-tenant SaaS). When we decided to open it to AI agents, we made an architectural decision that shaped everything else: we wouldn't expose REST "and call it a day"; we would expose an MCP server directly on top of the same domain that already served the UI.
Nexo's headless architecture
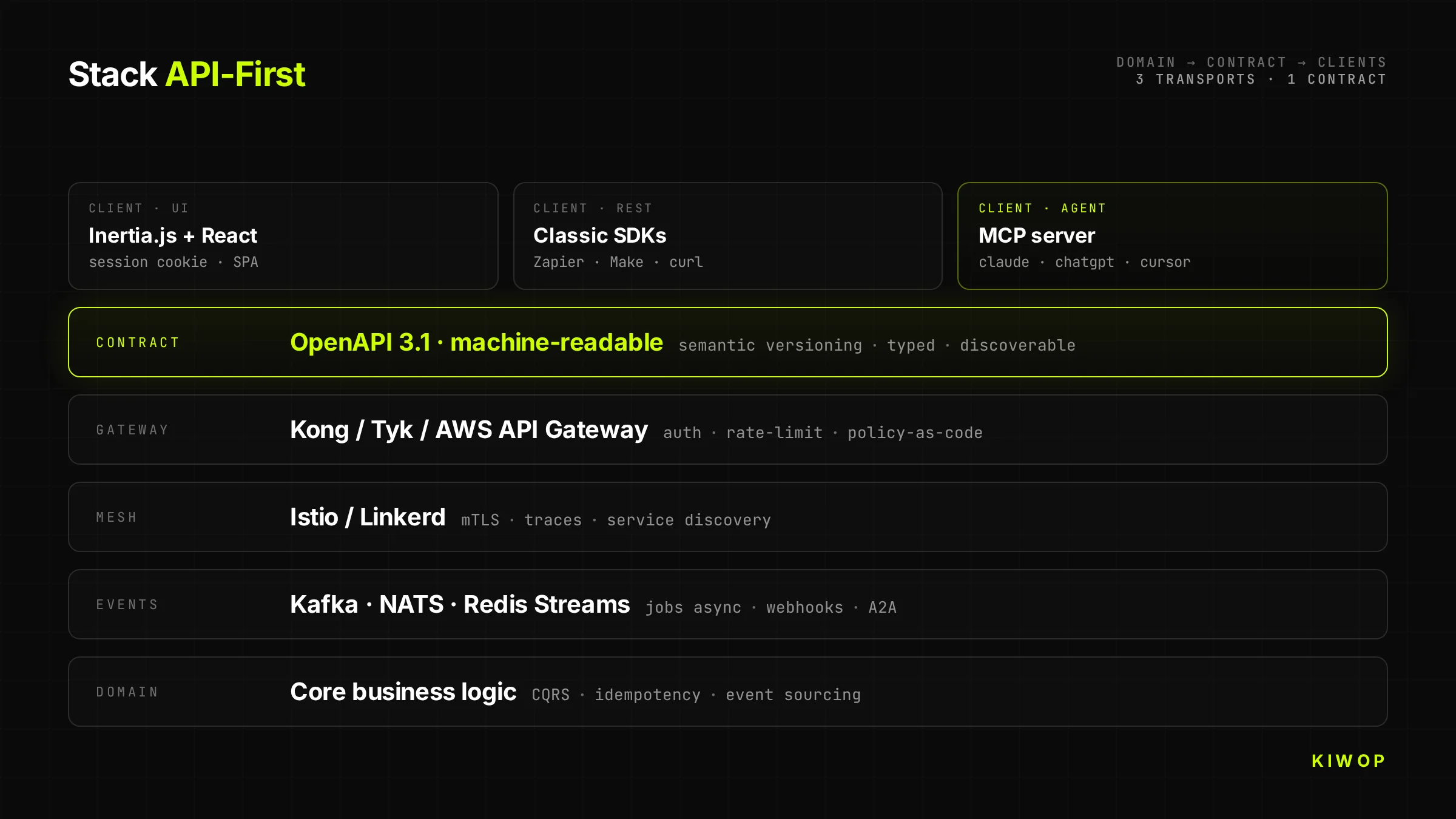
Nexo's backend has a single business domain (workspaces, projects, tasks, notes, agents). On top of that domain run three different transports that share the same contract:
- Inertia.js + React for the human UI (cookie session, optimistic, rich client)
- REST + OpenAPI 3.1 for classic integrations (Zapier, Make, own SDK)
- MCP server for direct consumption from Claude, ChatGPT and any agent with an MCP client
The domain is the same. What changes is the transport layer and the client's identity. That means when an agent creates a task via MCP, that task immediately appears in the human UI of the same workspace, with the correct user as owner and with the agent clearly tagged as actor.
Why MCP instead of just REST
We could have exposed only REST and let each integrator build their own MCP wrapper. We chose to expose native MCP for three reasons:
- The MCP contract captures intent better than generic REST. An MCP tool is described with a name, description, typed parameters and examples — the LLM doesn't have to deduce which of twenty REST endpoints to use; it sees it literally.
- The MCP ecosystem grows faster than any proprietary SDK. Claude, ChatGPT, Cursor, Windsurf, VS Code, Cline — they all speak MCP. If we expose MCP, they all consume us on day one.
- Observability is free. MCP harnesses already report which tool was called and with what result. We save ourselves building our own per-agent adoption dashboard.
Target metrics (design projections)
The following figures are design targets calibrated against comparable implementations, not large-scale production readings yet. We publish them as a reference of what's reasonable to expect from a well-done MCP-first architecture:
Values calibrated in internal tests and against comparable literature; they will be refined with production data as we scale.
First-hand lessons
What we already know after designing and operating Nexo's MCP layer, and which wasn't in any paper when we started:
- The real architectural cost isn't writing MCP; it's refactoring your backend so endpoints are granular, idempotent and composable. The MCP server itself is ~600 lines of TypeScript. The hard part is your business layer holding up to what agents ask of it.
- The per-agent audit trail changes conversations with clients. When a B2B client sees in their dashboard "your Claude agent changed the status of 14 tasks on Friday", the conversation shifts from "can I trust this?" to "I want to give access to more agents".
- Granular OAuth scopes sell. The first technical objection in sales was always "what if the agent goes rogue?". Having a typed answer — "this agent can only read project X until May 31st" — unlocks the signature.
When NOT to migrate to API-First
Migrating to API-First is expensive and doesn't always pay off. Three cases in which our honest recommendation is don't do it:
- Product with no real agentic use case. If your product is an internal ERP used by 30 employees and none of them will build agents, an API-first migration will give you no ROI. Invest in other things.
- Insufficient volume to amortize the overhead. If your total traffic is 100 requests a day, the added complexity (gateway, versioning, strict OpenAPI, MCP) weighs more than the benefit. First validate there's demand.
- Team without DevEx maturity. API-First requires a culture of contract-as-product: disciplined changelog, contract tests, documented SLAs. Without that culture, the contract drifts out of sync in six months and all the work is lost. Before migrating, invest in the culture.
If you fit any of the three, better stick with your current stack and revisit it in a year.
Migration roadmap — where to start
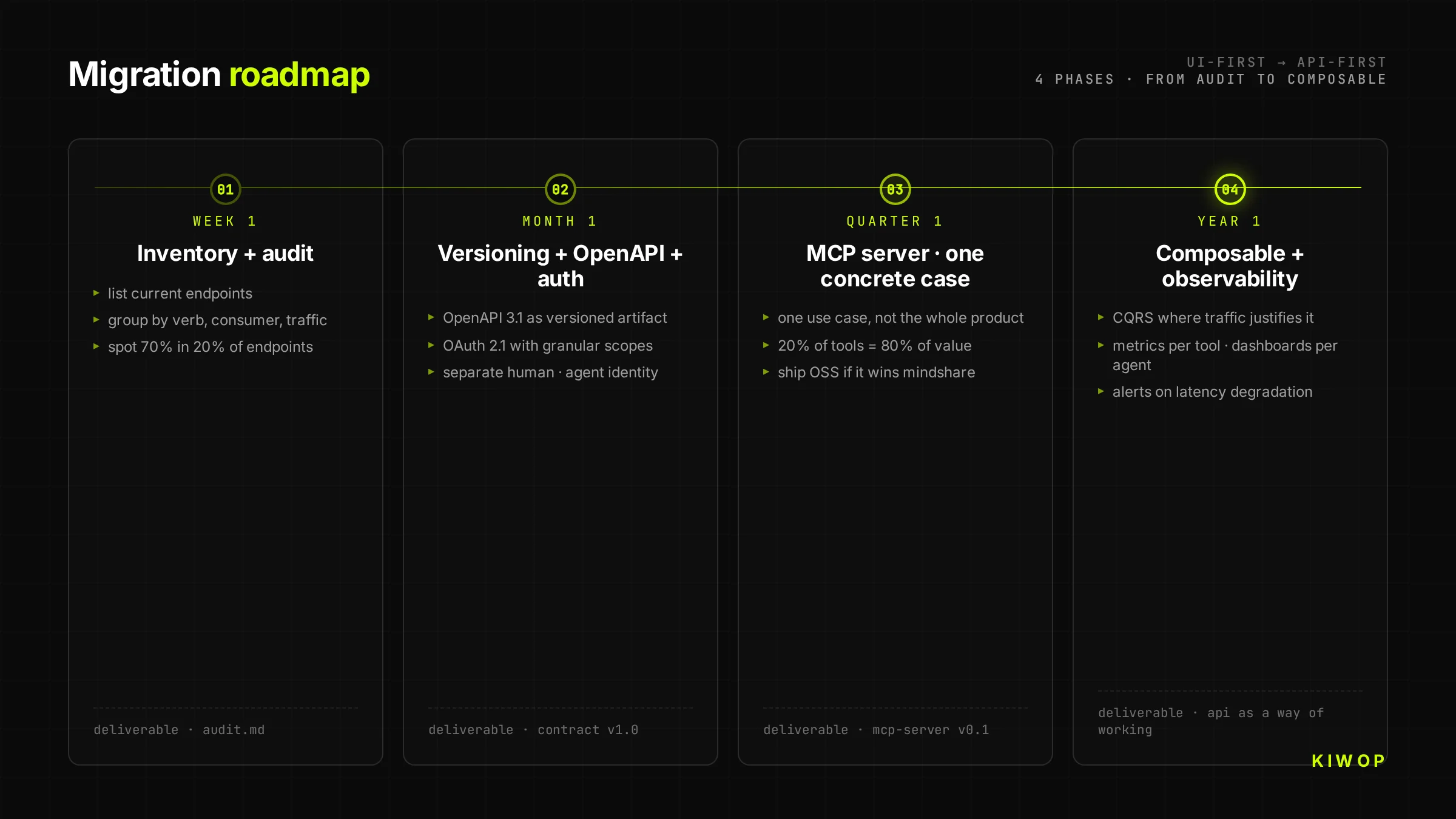
Week 1 — Inventory and audit
List all the current endpoints of your backend. Group them by HTTP verb, by consumer (web, mobile, internal), by usage frequency. Mark which have explicit versioning, which return structured errors, which have idempotency. This audit usually reveals that 70% of the code lives in 20% of the endpoints — those are the priority candidates to convert to API-first.
Month 1 — Versioning + OpenAPI + clean auth
Publish OpenAPI 3.1 as a versioned artifact for critical endpoints. Migrate authentication to OAuth 2.1 with granular scopes. Separate human identity from agent identity. Don't try to rewrite everything; start with a bounded domain (for example, just the "bookings" or "invoices" module) and treat it as a pilot.
Quarter 1 — MCP server for one use case
Pick a concrete use case and build an MCP server that exposes it. Don't try to cover the whole product; cover the 20% of tools that generate 80% of the value. Publish the MCP server as open-source if it makes sense (gain mindshare), or closed but documented.
Year 1 — Composable + full observability
Migrate the rest of the backend to the composable model. Implement CQRS where agent write traffic justifies it. Instrument per-tool metrics, per-agent adoption dashboards, alerts for latency degradation. At this point, the API-First architecture stops being a project and becomes the way the team works.
Frequently asked questions
What is API-First in one line?
An architecture in which the machine-readable contract is designed, versioned and published before any human interface that consumes it.
Is it the same as headless?
No. Headless means "no presentation layer coupled to the backend" — it's a structural property. API-First is a design discipline: the contract comes first. Every API-First architecture is headless, but not every headless one is API-First (you can have headless with a terrible contract).
Do I need MCP if I already have REST?
Not strictly, but MCP drastically accelerates agent adoption. If your clients are going to consume your product via Claude, ChatGPT or Cursor, exposing native MCP saves them building their own adapter. Full technical coverage is in MCP, WebMCP and A2A: protocols for AI agents.
How do you monetize an API consumed by agents?
The classic model (price per user) doesn't fit — an agent is not a user. Models that work: price by volume (requests or tokens consumed), price by value delivered (number of actions completed), price per connected agent (license per bot). Some platforms charge by agent tier based on criticality.
How much does it cost to migrate from UI-First to API-First?
It depends on the starting point, but an honest migration for a mid-sized SaaS platform (50-200 endpoints) runs between 3 and 9 months with a dedicated team. The biggest cost is not technical but cultural — agreeing that the contract is the primary artifact.
What happens to my SEO if I no longer have a UI?
API-First doesn't mean removing the public UI. The UI stays for humans and SEO; what you add is the API/MCP layer for agents. What's interesting is that with WebMCP you can expose direct actions to the AI agents visiting your site, which opens new acquisition surfaces.
Conclusion
An API-First architecture is not a technical luxury or a trend; it's the way to build a product when the primary consumer is no longer a human and becomes an agent. Salesforce's public pivot in 2026 is the late confirmation of something teams building today already take for granted: the API is the front door and the UI is just another client.
At Kiwop — Digital agency specialized in Software Development and Applied Artificial Intelligence for global clients across Europe and USA — we have built Nexo with this model from day one, and we help technical teams diagnose their current architecture and chart the shortest path to API-First without breaking what already works. If you're considering the migration, request an API-first architecture audit or take a look at our services in AI agent development, artificial intelligence consulting and LLM integration.
And if the technical direction interests you, follow the thread with the posts in the cluster: MCP, WebMCP and A2A: protocols for AI agents, AI agents in production: patterns and antipatterns, Nexo: technical anatomy of our multi-tenant SaaS and from OpenClaw to PA with Claude Code and MCP.