Por el equipo de Kiwop · Agencia Digital especializada en Desarrollo de Software e Inteligencia Artificial aplicada para clientes globales en Europa y USA · Publicado el 20 de abril de 2026 · Última actualización: 20 de abril de 2026
TL;DR — Una arquitectura API-First diseña el sistema desde sus contratos máquina-legibles antes que desde cualquier interfaz humana. Cuando el consumidor principal deja de ser un navegador y pasa a ser un agente IA, eso separa productos que sobreviven de los que no. Esta guía recoge los seis principios, los patrones que funcionan, los cuatro antipatrones que matan la adopción y el caso real de Nexo — nuestro SaaS que expone MCP como contrato nativo.

Cada semana llega la misma llamada desde un comité técnico: "Queremos abrir nuestro producto a agentes IA, pero nuestro backend se diseñó para una SPA". La respuesta honesta nunca es "montad un endpoint REST y listo". La respuesta correcta empieza por una pregunta: ¿vuestra arquitectura está pensada para que el consumidor principal sea una máquina, o para que sea un humano con ratón? Si es lo segundo, cada nuevo agente que conectéis va a pagar el impuesto del mismatch — latencia, scraping frágil, reintentos mal gestionados, cuentas compartidas entre humanos y bots. API-First no es un estilo de código; es la decisión arquitectónica que elimina ese impuesto desde el día uno.
Qué es la arquitectura API-First (definición operativa)
Una arquitectura API-First es aquella en la que cada contrato máquina-legible — su shape, su versión, su autenticación, su observabilidad — se diseña y valida antes que cualquier interfaz de usuario que lo consuma. El backend no expone "lo que la SPA necesita hoy"; expone un contrato público, tipado, versionado, documentado y descubrible, del que cualquier cliente (web, móvil, terceros, agentes IA) consume lo que le interesa.
La distinción clave no es técnica sino de secuencia. En API-First, el contrato es el artefacto primario — se revisa en PR, se publica como OpenAPI o AsyncAPI, se versiona como librería independiente. La UI viene después y el agente viene después. Todos son clientes del mismo primer ciudadano.
API-First vs API-Design-First vs Code-First
Tres términos que se usan intercambiables pero significan cosas distintas:
- Code-First: el código va primero. El contrato (OpenAPI, gRPC, GraphQL schema) se genera a partir del código. Rápido para empezar, caro para mantener. El contrato queda siempre un paso detrás.
- API-Design-First: el contrato se diseña como documento humano-legible antes de escribir código. Útil para coordinar equipos grandes, pero no garantiza que el consumidor principal sea una máquina.
- API-First: el contrato máquina-legible es el artefacto primero, último y siempre. Se diseña como producto con su propio roadmap, SLA, changelog y soporte. La UI es un cliente más.
Nuestra recomendación para cualquier plataforma que quiera exponerse a agentes IA: API-First con API-Design-First como ritual de equipo. El contrato vive en su propio repo o package, se revisa en PR, se publica semánticamente versionado.
Por qué con agentes IA la API ES la UI
Históricamente la UI era el producto y la API era un extra. Las empresas invertían en diseño de interacción, pruebas A/B de botones, flujos de onboarding visual. La API existía como backdoor para integraciones o SDKs, pero el presupuesto de producto estaba en la pantalla.
Con agentes IA esa jerarquía se invierte. Un agente no ve tu header, no clica tu CTA, no aprecia tu animación de loading. Lo único que ve es el contrato — y si el contrato es ambiguo, está mal versionado o tiene endpoints que devuelven HTML cuando tenían que devolver JSON, el agente falla silenciosamente o peor, inventa respuestas.
La API ya no es un backdoor. Es la front door. Todo el presupuesto de producto que antes iba a pulir la UI, ahora tiene que ir a pulir el contrato: nombres de campos claros, ejemplos en la doc, errores estructurados, paginación consistente, idempotencia explícita. Un producto con mala API pero buena UI todavía podía venderse a humanos. Un producto con mala API en un mundo de agentes no llega a la primera integración.
Por qué los agentes IA rompen el paradigma UI-first
Los agentes no navegan, invocan contratos tipados
Un humano navegando descubre tu producto por el flujo: entra por el home, lee una feature, clica en "empezar", rellena un formulario, confirma por email. Cada paso le da contexto para el siguiente.
Un agente IA hace exactamente lo contrario: parte de una intención concreta ("reserva una reunión con Marta el jueves"), enumera las herramientas disponibles, elige la que mejor encaja, construye los parámetros y llama. No hay flujo. Hay invocación directa. Eso significa que cada endpoint tiene que ser autocontenido: su descripción en OpenAPI debe ser suficiente para que un modelo entienda qué hace, cuándo usarlo y con qué parámetros, sin haber visto ninguna pantalla previa.
La consecuencia arquitectónica es brutal. Endpoints que en una SPA formaban parte de un flujo guiado ("primero POST /cart, luego POST /cart/items, luego POST /checkout") tienen que ser repensados o explícitamente documentados como secuencia, con errores que dejen claro el siguiente paso. Los "pasos implícitos" que el humano hacía mentalmente, ahora los tiene que hacer el protocolo.
El coste real del scraping vs la API bien diseñada
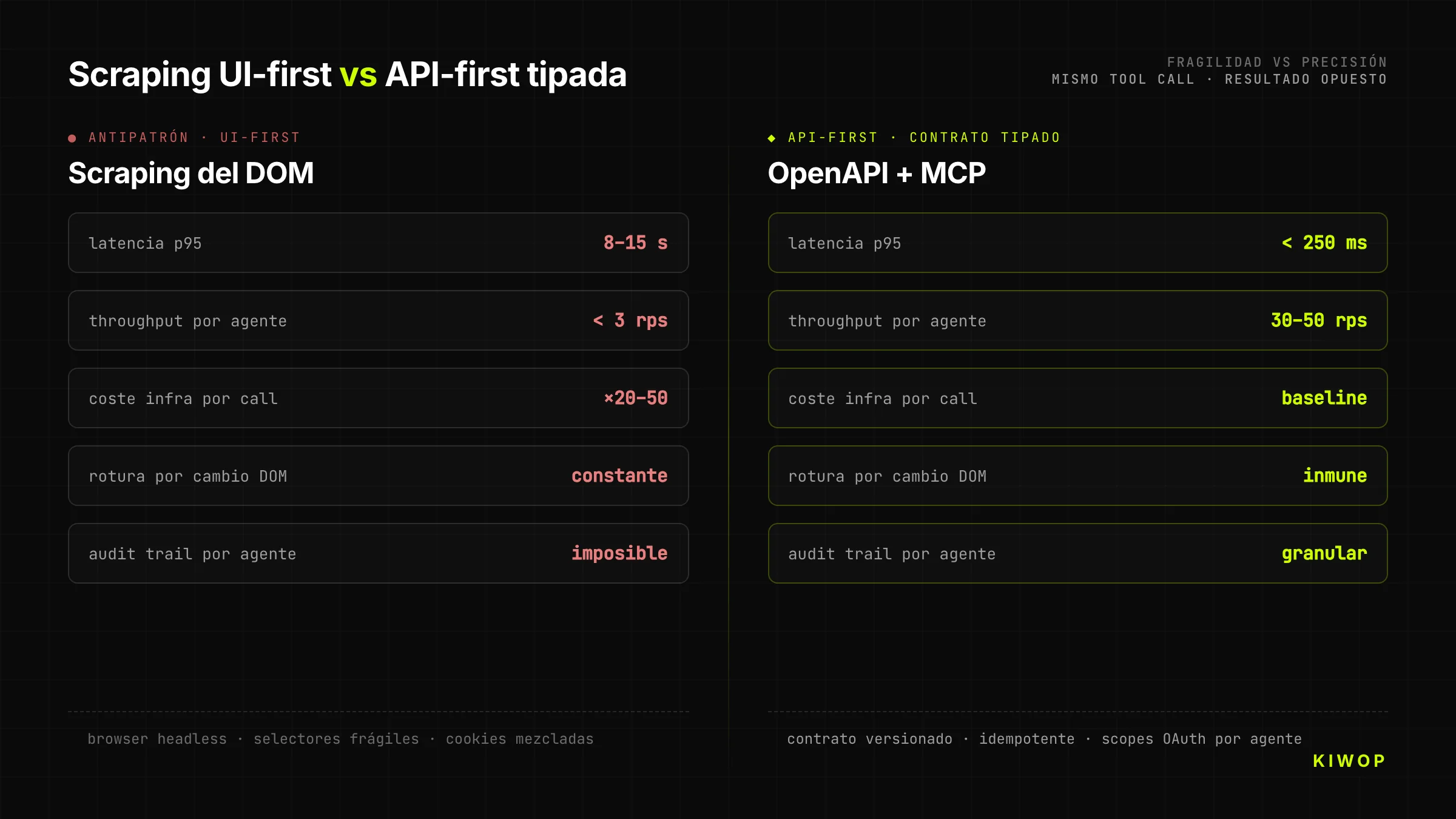
La tentación es obvia: ya que el sitio web existe y funciona, ¿para qué construir API nueva? Ponemos un browser-use o un puppeteer delante y que el agente haga clics. Es barato, rápido, no requiere tocar el backend. Es también la decisión que destruye proyectos.
El scraping-as-backend tiene tres costes que no aparecen hasta meses después. Primero, es frágil: cualquier cambio en el DOM rompe el agente, y como el equipo de frontend no sabe que hay agentes dependiendo del DOM, los cambios son constantes. Segundo, es lento: un tool call contra una API bien diseñada se resuelve en 200-400 ms; el mismo paso vía browser tarda 8-15 segundos cargando CSS, JS y esperando a que los selectores aparezcan. Tercero, es caro: correr un navegador headless por petición multiplica por 20-50 el coste de infraestructura respecto a servir JSON.
Una API diseñada para agentes cuesta más en fase de diseño, pero se amortiza en la primera integración real. Las empresas que llegan a Kiwop con un año de "solución temporal" con scraping llegan siempre con el mismo síntoma: el coste de mantenimiento ha igualado al coste estimado de construir la API bien desde el principio.
El pivote de Salesforce tras casi tres décadas
En febrero de 2026 Marc Benioff, CEO de Salesforce, lo dijo sin rodeos: "APIs are the new UI". Veintisiete años después de fundar una compañía que definió qué era "el SaaS", Salesforce reconoce públicamente que el navegador ya no es el punto de contacto principal de su producto. Su foco se desplaza a que los agentes IA consuman directamente su data, sus workflows, sus tasks — vía API.
No es una declaración disruptiva, es una confirmación tardía. Las empresas que construyen plataformas nuevas hoy ya asumen que la primera integración real va a ser con un agente, no con un humano. El movimiento de Salesforce es la señal de que hasta las incumbentes más grandes están aceptando la misma realidad. Si en 2028 un producto SaaS todavía tiene su mejor DX detrás del navegador, es porque llegará tarde al ciclo.
Los seis principios de una API-First lista para agentes
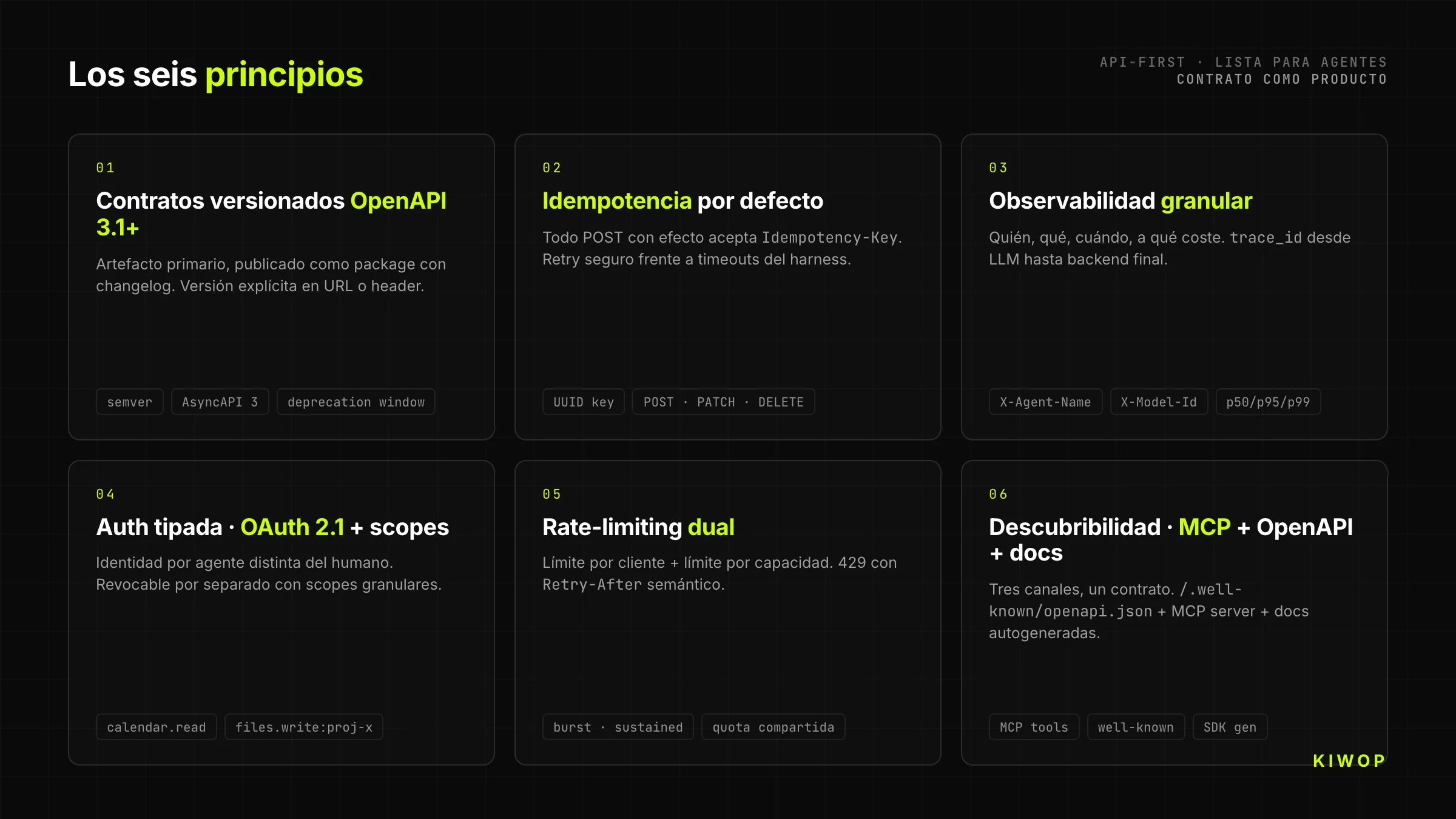
1. Contratos versionados con OpenAPI 3.1+
Toda API-First empieza por un contrato OpenAPI 3.1 (o AsyncAPI 3 para lo event-driven) publicado como artefacto versionado semánticamente. No como PDF generado al final del sprint. No como archivo flotante en Confluence. Como package publicado con changelog, que cualquier consumidor puede fijar en una versión concreta y actualizar con intención.
La versión va en la URL (/v2/...) o en el header (Accept-Version); da igual el mecanismo mientras sea explícito y el servidor pueda servir dos versiones en paralelo durante el deprecation window. Para agentes IA esto es crítico: un modelo aprendido sobre la v1 de tu API no debe romperse porque hayas añadido un campo en v2.
2. Idempotencia por defecto
Los agentes reintentan. Mucho. Por timeouts, por saturación de contexto, por políticas de retry del propio harness. Una API-First asume idempotencia como contrato: todo POST que genera efecto colateral acepta un header Idempotency-Key (UUID generado por el cliente) y garantiza que dos llamadas con la misma key producen un único efecto.
La regla se extiende a los PATCH, DELETE y operaciones costosas. Sin idempotencia, el primer timeout de red crea un pedido duplicado, un email enviado dos veces o una reserva duplicada. Con idempotencia, el agente puede reintentar con tranquilidad y tu lógica de negocio no depende de la suerte.
3. Observabilidad granular: quién, qué, cuándo, a qué coste
Cuando el tráfico principal deja de ser humano, los dashboards clásicos ("usuarios activos") ya no representan nada. Lo que importa es: qué agente llamó a qué tool, con qué parámetros, cuánto tardó, cuántos tokens consumió en el modelo que le llamó, y si el resultado fue útil (el agente reintentó o siguió adelante).
Los headers User-Agent, X-Agent-Name, X-Model-Id son ahora obligatorios, no opcionales. El logging estructurado incluye trace_id que se propaga desde el LLM hasta el backend final. Y las métricas por tool — p50, p95, p99 de latencia, tasa de error, tasa de retry — son el equivalente nuevo de los KPIs de producto.
4. Autenticación tipada: OAuth + scopes por agente
Cada agente que consume tu API debe tener su propia identidad distinta de la del humano que lo autorizó. Esto se implementa con OAuth 2.1 + scopes granulares: el humano delega a su agente un subconjunto explícito de permisos (calendar.read, calendar.write:2026-05, files.read:project-x), y cada token queda trazable hasta el par (humano, agente, timestamp).
La consecuencia práctica: dos agentes del mismo humano son dos identidades distintas. Uno puede ser revocado sin romper el otro. Y los logs del backend pueden responder la pregunta que nadie se hacía hace dos años — "¿qué agente de qué humano hizo esta acción a las 3 de la madrugada?".
5. Rate-limiting dual: por cliente y por capacidad
El rate-limiting clásico (X peticiones por minuto por token) no funciona con agentes porque un agente bien hecho puede generar ráfagas legítimas de cientos de tool calls en segundos para cumplir una tarea compleja. La API tiene que combinar dos límites: un límite por cliente (para proteger al agente de bucles) y un límite por capacidad (para proteger al backend de la suma de todos los agentes).
Los errores 429 Too Many Requests deben incluir Retry-After y distinguir claramente entre "vuelve a intentarlo en 2 segundos" y "esta operación está bloqueada para ti durante 10 minutos por abuso". Esta diferencia es lo que permite al agente razonar sobre cómo adaptarse.
6. Descubribilidad: MCP + OpenAPI + docs autogeneradas
Una API-First moderna debería ser descubrible por tres canales complementarios. OpenAPI publicado en un endpoint predecible (/.well-known/openapi.json) para consumo por herramientas de dev y SDKs. MCP server exponiendo las mismas capacidades como tools listos para conectar con Claude, ChatGPT o cualquier agente que hable el protocolo. Y docs para humanos autogeneradas a partir del mismo contrato, para cuando el developer del otro lado necesita mirar con ojos humanos.
Los tres canales consumen el mismo contrato. Si la docs y el OpenAPI se desincronizan, es porque hay algo mal arquitectónicamente — el contrato no es el artefacto primario.
La capa específica para agentes — MCP, WebMCP, A2A
OpenAPI te da la base, pero para que un agente consuma tu producto con fricción cero existe una capa de protocolos específica. MCP (Model Context Protocol) es el estándar para exponer tools a un agente que corre en un harness (Claude, ChatGPT, Cursor). WebMCP hace lo mismo desde el navegador, para que tu web pública exponga acciones al agente del usuario. A2A (Agent-to-Agent) orquesta comunicación entre agentes, no entre agente y tools.
No compiten con OpenAPI: lo complementan. En producción, OpenAPI es la verdad del backend; MCP y WebMCP son adaptadores finos que traducen ese contrato al formato que los harnesses esperan. Cubrimos la comparativa técnica y cuándo usar cada uno en MCP, WebMCP y A2A: qué protocolo elegir para tus agentes IA.
Patrones arquitectónicos que funcionan
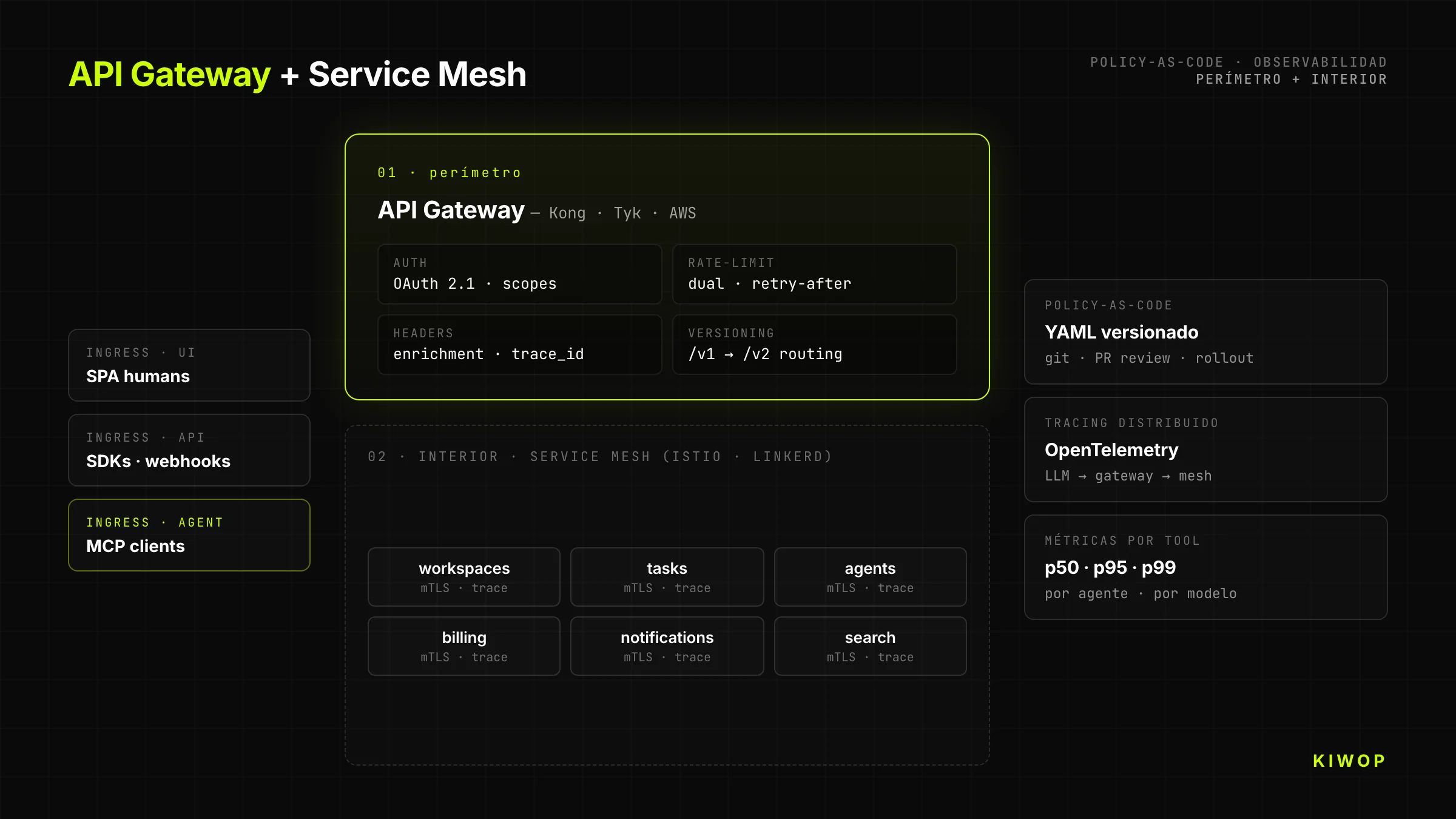
API Gateway + Service Mesh con policy-as-code
Toda API-First seria pasa por un gateway que aplica políticas antes de llegar al backend: autenticación, rate-limiting, observabilidad, enrichment de headers, transformación entre versiones. Nuestra stack recomendada: Kong, Tyk o AWS API Gateway para el perímetro; Istio o Linkerd para el service mesh interno. Las políticas se definen como código (YAML versionado en git), no como clicks en la consola del vendor.
La separación importa: el gateway se preocupa de "qué cliente puede llamar qué endpoint"; el mesh se preocupa de "qué servicio puede hablar con qué servicio dentro del cluster". Mezclar las dos responsabilidades es el camino más corto a una arquitectura que nadie entiende en seis meses.
Backend-for-Frontend ≠ Backend-for-Agent
El patrón BFF (Backend-for-Frontend) nació para que cada UI (web, móvil, smart TV) tuviera su propio endpoint optimizado. La tentación es aplicarlo también a los agentes: construir un "BFA" (Backend-for-Agent) que agregue llamadas para minimizar round-trips.
No lo hagas sin pensarlo dos veces. Un agente no es una UI con latencia humana; es un cliente que razona. Si agregas demasiado, el agente pierde granularidad — no puede combinar tools como quiere. Si agregas demasiado poco, desperdicia contexto en calls innecesarios. La decisión correcta depende del caso: tools de lectura pueden beneficiarse de endpoints agregados (GET /dashboard que devuelve usuario + permisos + últimas acciones); tools de escritura deben ser atómicos y compositivos (POST /bookings aislado, sin side-effects ocultos).
Event-driven con Kafka, NATS o Redis Streams
Los agentes disparan trabajos que tardan. Generar un informe, procesar un pedido, entrenar un modelo — operaciones de segundos a minutos. Exponerlas como REST síncrono obliga al agente a sostener la conexión y consumir contexto esperando.
La alternativa es event-driven: el agente manda un POST /jobs que devuelve un job_id en menos de 100 ms, luego consulta el estado vía GET /jobs/{id} o se suscribe a un canal de eventos. Kafka o NATS para volumen alto; Redis Streams para setups ligeros. El patrón libera al agente de bloquear y permite a tu backend absorber picos sin caer.
CQRS para separar escritura ruidosa (agentes) de lectura crítica (humanos)
Cuando los agentes pasan a ser mayoría del tráfico de escritura, los humanos que leen el mismo producto empiezan a sufrir contención: queries lentas, invalidaciones de cache constantes, dashboards que tardan en cargar. CQRS (Command Query Responsibility Segregation) separa el modelo que escribe del modelo que lee: los agentes mandan commands a una write-side optimizada para consistencia; los humanos consumen de una read-side optimizada para lectura rápida, alimentada por eventos desde la write-side.
No es gratis — añade complejidad y eventual consistency. Pero por encima de cierto volumen de tráfico agente, es la única forma de mantener la UX humana intacta.
Antipatrones que matan tu adopción por agentes
Antipatrón 1 — Exponemos la UI con cookies, "y listo"
El primer reflejo de un equipo apurado es delegar a un browser-use o Playwright las acciones del agente. Funciona en la demo, falla en producción en la primera rotación del DOM. Cualquier cambio visual del frontend (A/B test de un botón, refactor de selectores) rompe al agente silenciosamente. La deuda es invisible hasta que es tarde — momento en el cual el coste de reconstruir la API "bien" es triple.
Antipatrón 2 — APIs sin versionado explícito
Tener una API en /api/... sin prefijo de versión funciona hasta el primer cambio breaking. A partir de ahí, todos los agentes en producción se rompen a la vez. Los equipos que apuestan por "siempre backwards compatible" acaban acumulando 15 años de deuda en el mismo endpoint. La disciplina correcta es versionado desde el primer commit, con deprecation windows documentadas en el changelog.
Antipatrón 3 — Docs escritas solo para humanos
Bonitas páginas en Mintlify o ReadMe con gifs y tutoriales son inútiles para un agente. El agente consume OpenAPI crudo, JSON Schema, tipos TypeScript o una descripción MCP. Si ese artefacto máquina-legible no existe o está desactualizado, el agente inventa. La docs humana se genera del contrato; no al revés.
Antipatrón 4 — Autenticación mezclada: sesión humana + token agente en el mismo endpoint
Un error común en equipos que migran desde productos humanos: reutilizar la sesión de cookie del usuario para que su agente llame a la API "como si fuera él". Resultado: imposible distinguir quién hace qué en los logs, imposible revocar un agente sin tumbar la sesión humana, imposible limitar scopes distintos por origen.
La separación correcta: sesión humana con cookie HttpOnly para la UI; tokens OAuth con scopes para los agentes; cada uno con su propio endpoint de autenticación y su propio audit trail.
Caso real — Nexo como servidor MCP
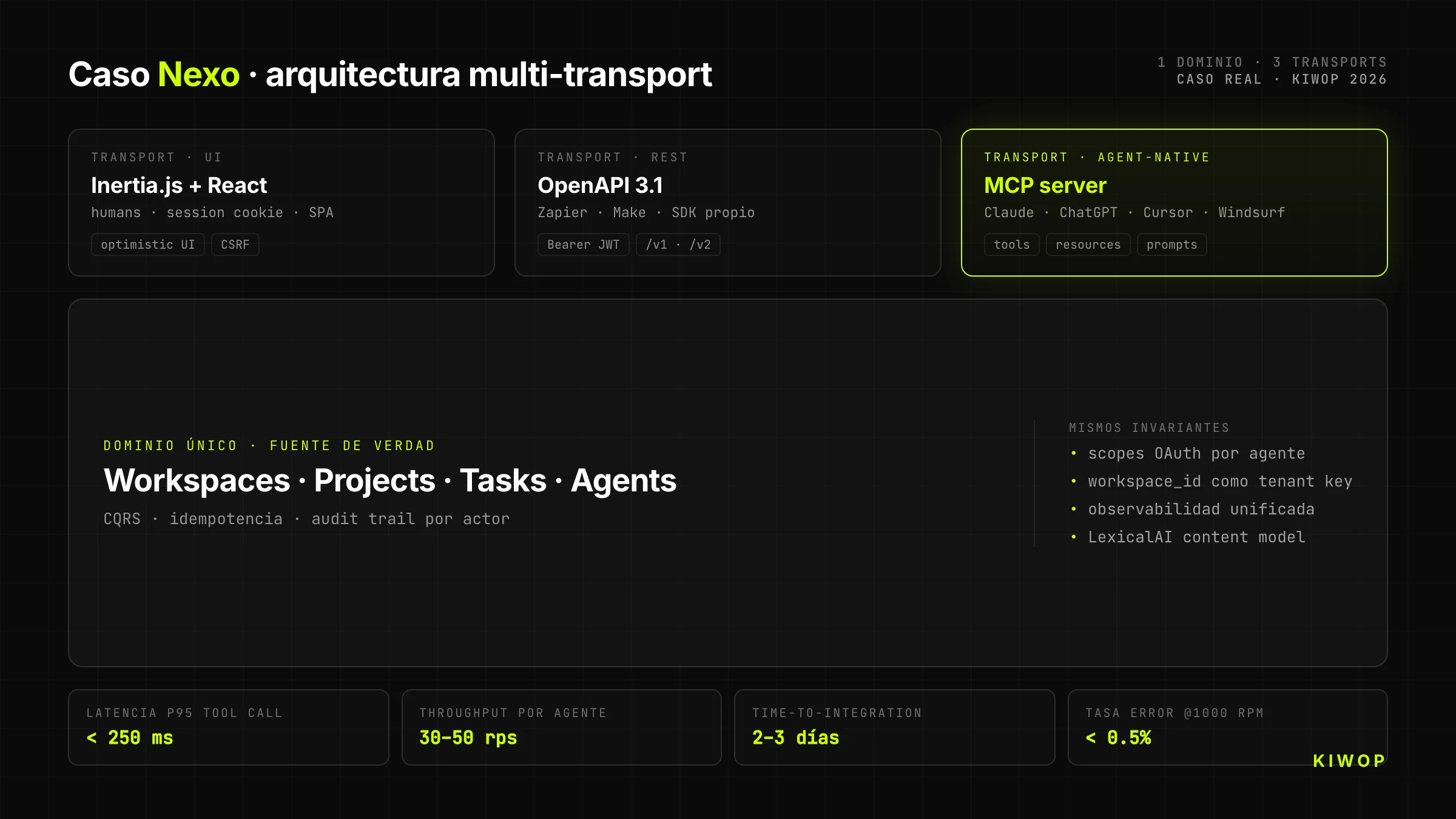
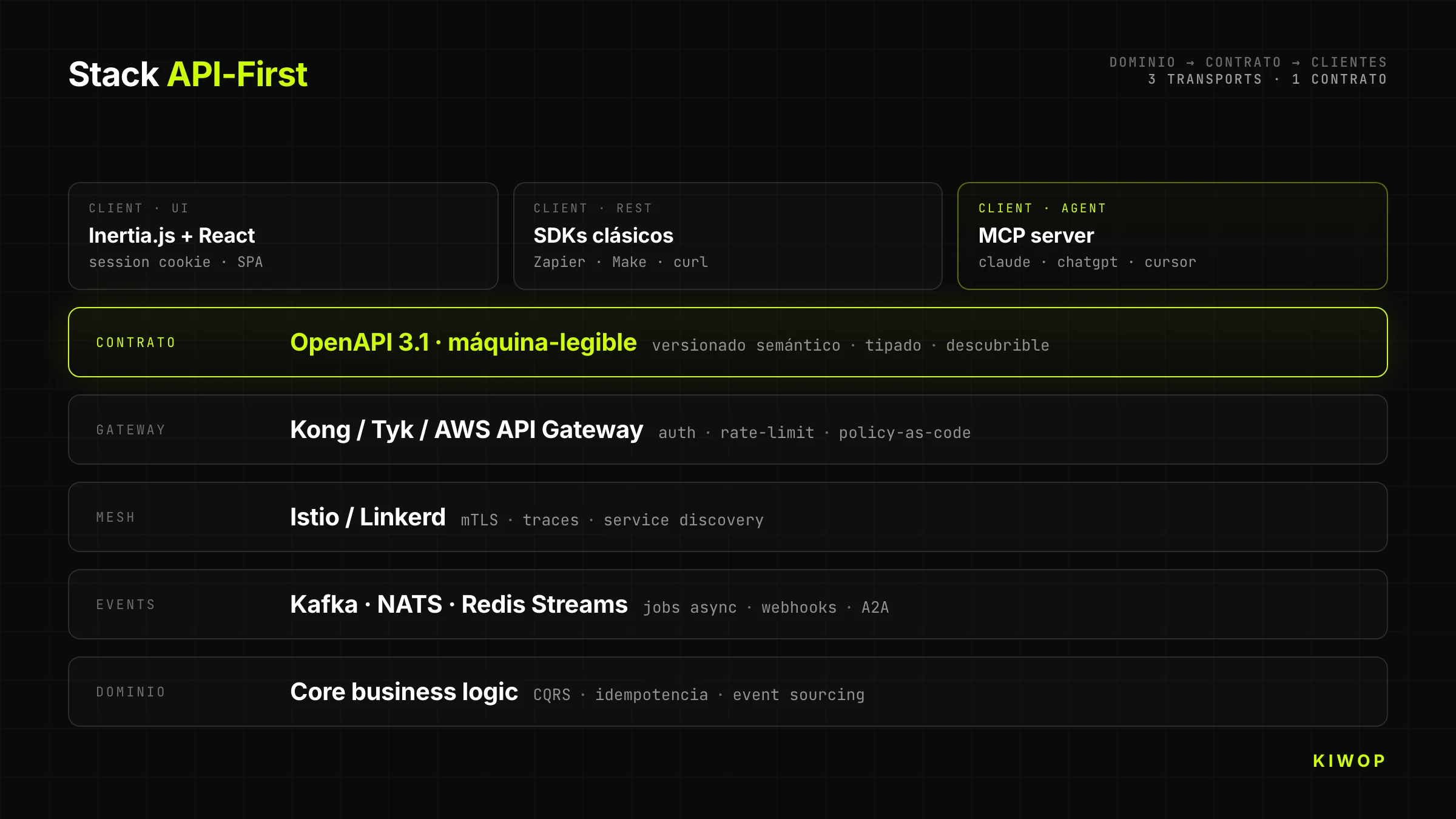
Nexo es nuestro SaaS propio de workspace para equipos. Empezó como una app Laravel + React + Inertia.js orientada a humanos (documentación técnica: Nexo: anatomía técnica de nuestro SaaS multi-tenant). Cuando decidimos abrirlo a agentes IA, tomamos una decisión arquitectónica que condicionó todo lo demás: no expondríamos REST "y punto"; expondríamos directamente un servidor MCP encima del mismo dominio que ya servía a la UI.
Arquitectura headless de Nexo
El backend de Nexo tiene un solo dominio de negocio (workspaces, proyectos, tareas, notas, agentes). Sobre ese dominio corren tres transports distintos que comparten el mismo contrato:
- Inertia.js + React para la UI humana (sesión cookie, optimista, cliente enriquecido)
- REST + OpenAPI 3.1 para integraciones clásicas (Zapier, Make, SDK propio)
- MCP server para consumo directo desde Claude, ChatGPT y cualquier agente con cliente MCP
El dominio es el mismo. Lo que cambia es la capa de transport y la identidad del cliente. Eso significa que cuando un agente crea una tarea vía MCP, esa tarea aparece inmediatamente en la UI humana del mismo workspace, con el usuario correcto como propietario y con el agente claramente etiquetado como actor.
Por qué MCP en vez de REST "y punto"
Podríamos haber expuesto solo REST y dejar que cada integrador construyera su propio wrapper MCP. Optamos por exponer MCP nativo por tres razones:
- El contrato MCP captura intención mejor que REST genérico. Una tool MCP se describe con nombre, descripción, parámetros tipados y ejemplos — el LLM no tiene que deducir cuál de veinte endpoints REST usar; lo ve literal.
- El ecosistema MCP crece más rápido que cualquier SDK propietario. Claude, ChatGPT, Cursor, Windsurf, VS Code, Cline — todos hablan MCP. Si exponemos MCP, todos nos consumen día uno.
- La observabilidad es gratis. Los harnesses MCP ya reportan qué tool se llamó y con qué resultado. Nos ahorramos construir nuestro propio dashboard de adopción por agente.
Métricas objetivo (proyecciones de diseño)
Las siguientes cifras son objetivos de diseño calibrados contra implementaciones comparables, no lecturas en producción a gran escala todavía. Las publicamos como referencia de qué es razonable esperar de una arquitectura MCP-first bien hecha:
Valores calibrados en tests internos y contra literatura comparable; se refinarán con datos de producción a medida que escalemos.
Lecciones de primera mano
Lo que ya sabemos después de diseñar y operar la capa MCP de Nexo, y que no estaba en ningún paper cuando empezamos:
- El coste arquitectónico real no es escribir MCP; es refactorizar tu backend para que los endpoints sean granulares, idempotentes y compositivos. El MCP server en sí son ~600 líneas de TypeScript. Lo duro es que tu capa de negocio aguante lo que los agentes le piden.
- El audit trail por agente cambia conversaciones con clientes. Cuando un cliente B2B ve en su dashboard "tu agente Claude cambió el estado de 14 tareas el viernes", la conversación pasa de "¿puedo confiar en esto?" a "quiero dar acceso a más agentes".
- Los scopes OAuth granulares venden. La primera objeción técnica en ventas era siempre "¿y si el agente se descontrola?". Tener respuesta tipada — "este agente solo puede leer el proyecto X hasta el 31 de mayo" — desbloquea la firma.
Cuándo NO migrar a API-First
La migración a API-First es cara y no siempre compensa. Tres casos en los que nuestra recomendación honesta es no hacerlo:
- Producto sin caso de uso agentic real. Si tu producto es un ERP interno usado por 30 empleados y ninguno va a construir agentes, una migración API-first no te dará ROI. Invierte en otras cosas.
- Volumen insuficiente para amortizar el overhead. Si tu tráfico total es de 100 peticiones al día, la complejidad añadida (gateway, versionado, OpenAPI estricto, MCP) pesa más que el beneficio. Primero valida que hay demanda.
- Equipo sin madurez DevEx. API-First requiere cultura de contrato como producto: changelog disciplinado, tests de contract, SLA documentados. Sin esa cultura, el contrato se desincroniza en seis meses y todo el trabajo se pierde. Antes de migrar, invierte en la cultura.
Si encajas en alguno de los tres, mejor seguir con tu stack actual y revisitarlo en un año.
Roadmap de migración — por dónde empezar
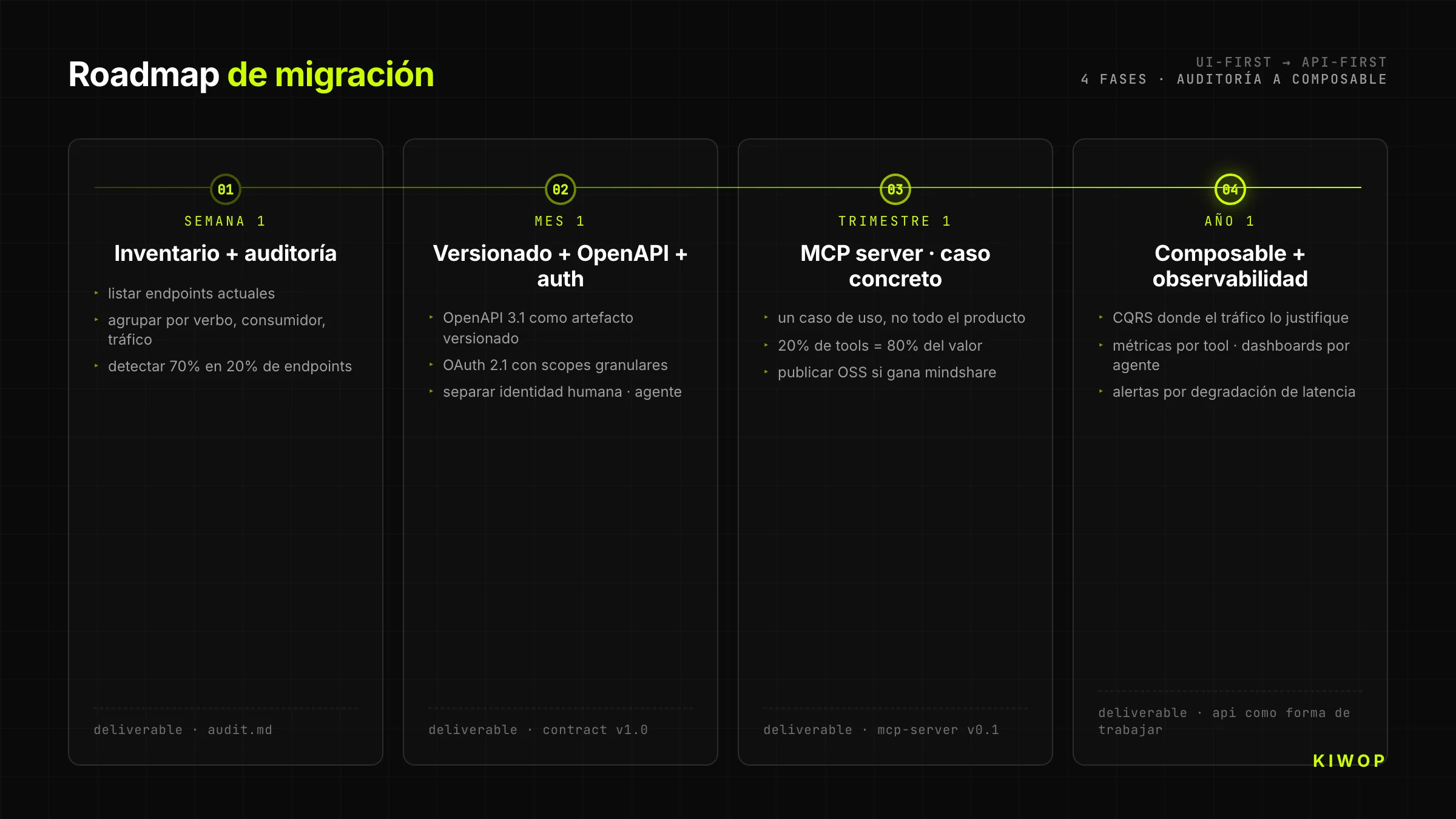
Semana 1 — Inventario y auditoría
Lista todos los endpoints actuales de tu backend. Agrúpalos por verbo HTTP, por consumidor (web, móvil, interno), por frecuencia de uso. Marca cuáles tienen versionado explícito, cuáles devuelven errores estructurados, cuáles tienen idempotencia. Esta auditoría suele revelar que el 70% del código vive en el 20% de los endpoints — esos son los candidatos prioritarios a convertir en API-first.
Mes 1 — Versionado + OpenAPI + auth limpia
Publica OpenAPI 3.1 como artefacto versionado para los endpoints críticos. Migra la autenticación a OAuth 2.1 con scopes granulares. Separa la identidad humana de la identidad agente. No intentes reescribir todo; empieza por un dominio acotado (por ejemplo, solo el módulo de "reservas" o "facturas") y trátalo como prueba.
Trimestre 1 — MCP server para un caso de uso
Elige un caso de uso concreto y construye un MCP server que lo exponga. No intentes cubrir todo el producto; cubre el 20% de herramientas que genera el 80% del valor. Publica el MCP server como open-source si tiene sentido (gana mindshare), o cerrado pero documentado.
Año 1 — Composable + observabilidad completa
Migra el resto del backend al modelo composable. Implementa CQRS donde el tráfico de escritura agente lo justifique. Instrumenta métricas por tool, dashboards de adopción por agente, alertas por degradación de latencia. En este punto, la arquitectura API-First deja de ser un proyecto y pasa a ser la forma de trabajar del equipo.
Preguntas frecuentes
¿Qué es API-First en una línea?
Una arquitectura en la que el contrato máquina-legible se diseña, versiona y publica antes que cualquier interfaz humana que lo consuma.
¿Es lo mismo que headless?
No. Headless significa "sin capa de presentación acoplada al backend" — es una propiedad estructural. API-First es una disciplina de diseño: el contrato va primero. Toda arquitectura API-First es headless, pero no toda headless es API-First (puedes tener headless con un contrato pésimo).
¿Necesito MCP si ya tengo REST?
No estrictamente, pero MCP acelera brutalmente la adopción por agentes. Si tus clientes van a consumir tu producto vía Claude, ChatGPT o Cursor, exponer MCP nativo les ahorra construir su propio adaptador. La cobertura técnica está en MCP, WebMCP y A2A: protocolos para agentes IA.
¿Cómo se monetiza una API consumida por agentes?
El modelo clásico (precio por usuario) no encaja — un agente no es un usuario. Los modelos que funcionan: precio por volumen (peticiones o tokens consumidos), precio por valor entregado (número de acciones completadas), precio por agente conectado (licencia por bot). Algunas plataformas cobran por tier de agente según criticidad.
¿Cuánto cuesta migrar de UI-First a API-First?
Depende del punto de partida, pero una migración honesta para una plataforma SaaS mediana (50-200 endpoints) está entre 3 y 9 meses con un equipo dedicado. El mayor coste no es técnico sino cultural — acordar que el contrato es el artefacto primario.
¿Qué pasa con mi SEO si dejo de tener UI?
API-First no significa eliminar la UI pública. La UI se queda para humanos y SEO; lo que añades es la capa API/MCP para agentes. Lo interesante es que con WebMCP puedes exponer acciones directas a los agentes IA que visitan tu web, lo que abre nuevas superficies de adquisición.
Conclusión
Una arquitectura API-First no es un lujo técnico ni una moda; es la forma de construir producto cuando el consumidor principal deja de ser un humano y pasa a ser un agente. El pivote público de Salesforce en 2026 es la confirmación tardía de algo que los equipos que construyen hoy ya dan por supuesto: la API es la front door y la UI es un cliente más.
En Kiwop — Agencia Digital especializada en Desarrollo de Software e Inteligencia Artificial aplicada para clientes globales en Europa y USA — hemos construido Nexo con este modelo desde el primer día, y ayudamos a equipos técnicos a diagnosticar su arquitectura actual y dibujar el camino más corto hasta API-First sin romper lo que ya funciona. Si estás considerando la migración, solicita una auditoría de arquitectura API-first o echa un vistazo a nuestros servicios de desarrollo de agentes IA, consultoría de inteligencia artificial e integración de LLMs.
Y si te ha interesado la dirección técnica, sigue el hilo con los posts del cluster: MCP, WebMCP y A2A: protocolos para agentes IA, agentes IA en producción: patrones y antipatrones, Nexo: anatomía técnica de nuestro SaaS multi-tenant y de OpenClaw a PA con Claude Code y MCP.