Door het Kiwop-team · Digitaal agentschap gespecialiseerd in softwareontwikkeling en toegepaste kunstmatige intelligentie voor wereldwijde klanten in Europa en de VS · Gepubliceerd op 20 april 2026 · Laatst bijgewerkt: 20 april 2026
TL;DR — Een API-First-architectuur ontwerpt het systeem vanuit zijn machine-leesbare contracten, vóór welke menselijke interface dan ook. Wanneer de primaire consument niet langer een browser is maar een AI-agent, scheidt dat producten die overleven van producten die dat niet doen. Deze gids bundelt de zes principes, de patronen die werken, de vier antipatronen die adoptie doden en de reële casus van Nexo — onze SaaS die MCP blootstelt als nativ contract.

Elke week komt dezelfde oproep binnen vanuit een technisch comité: "We willen ons product openstellen voor AI-agents, maar onze backend is ontworpen voor een SPA". Het eerlijke antwoord is nooit "zet een REST-endpoint op en klaar is kees". Het juiste antwoord begint met een vraag: is jullie architectuur ontworpen zodat de primaire consument een machine is, of een mens met een muis? Als het laatste het geval is, betaalt elke nieuwe agent die jullie aansluiten de mismatch-belasting — latency, fragiele scraping, slecht beheerde retries, gedeelde accounts tussen mensen en bots. API-First is geen codeerstijl; het is de architectonische beslissing die die belasting vanaf dag één elimineert.
Wat is API-First-architectuur (operationele definitie)
Een API-First-architectuur is er een waarin elk machine-leesbaar contract — zijn shape, zijn versie, zijn authenticatie, zijn observability — wordt ontworpen en gevalideerd vóór welke gebruikersinterface dan ook die het consumeert. De backend stelt niet bloot "wat de SPA vandaag nodig heeft"; hij stelt een publiek, getypeerd, versiebeheerd, gedocumenteerd en vindbaar contract bloot, waaruit elke client (web, mobiel, derden, AI-agents) consumeert wat hem interesseert.
Het cruciale onderscheid is niet technisch maar sequentieel. In API-First is het contract het primaire artefact — het wordt beoordeeld in PR, gepubliceerd als OpenAPI of AsyncAPI, versiebeheerd als onafhankelijke bibliotheek. De UI komt daarna en de agent komt daarna. Allemaal clients van dezelfde eersterangs burger.
API-First vs API-Design-First vs Code-First
Drie termen die door elkaar worden gebruikt maar verschillende dingen betekenen:
- Code-First: de code komt eerst. Het contract (OpenAPI, gRPC, GraphQL schema) wordt uit de code gegenereerd. Snel om te beginnen, duur om te onderhouden. Het contract loopt altijd een stap achter.
- API-Design-First: het contract wordt ontworpen als mensleesbaar document voordat er code wordt geschreven. Nuttig om grote teams te coördineren, maar garandeert niet dat de primaire consument een machine is.
- API-First: het machine-leesbare contract is het artefact eerst, laatst en altijd. Het wordt ontworpen als product met zijn eigen roadmap, SLA, changelog en support. De UI is gewoon een client.
Onze aanbeveling voor elk platform dat zich wil openstellen voor AI-agents: API-First met API-Design-First als teamritueel. Het contract leeft in zijn eigen repo of package, wordt beoordeeld in PR, wordt semantisch versiebeheerd gepubliceerd.
Waarom bij AI-agents de API de UI IS
Historisch was de UI het product en de API een extraatje. Bedrijven investeerden in interactieontwerp, A/B-tests van knoppen, visuele onboarding-flows. De API bestond als backdoor voor integraties of SDK's, maar het productbudget zat in het scherm.
Met AI-agents keert die hiërarchie om. Een agent ziet jouw header niet, klikt niet op jouw CTA, waardeert jouw loading-animatie niet. Het enige wat hij ziet is het contract — en als het contract dubbelzinnig is, slecht versiebeheerd is of endpoints heeft die HTML teruggeven wanneer ze JSON hadden moeten teruggeven, faalt de agent stilzwijgend of, erger nog, verzint antwoorden.
De API is niet langer een backdoor. Het is de front door. Al het productbudget dat vroeger naar het polijsten van de UI ging, moet nu naar het polijsten van het contract: heldere veldnamen, voorbeelden in de docs, gestructureerde fouten, consistente paginering, expliciete idempotentie. Een product met een slechte API maar een goede UI kon nog steeds aan mensen worden verkocht. Een product met een slechte API in een wereld van agents komt niet eens tot de eerste integratie.
Waarom AI-agents het UI-first-paradigma doorbreken
Agents navigeren niet, ze roepen getypeerde contracten aan
Een mens die navigeert ontdekt jouw product via de flow: komt binnen op de homepage, leest een feature, klikt op "beginnen", vult een formulier in, bevestigt via e-mail. Elke stap geeft context voor de volgende.
Een AI-agent doet precies het tegenovergestelde: vertrekt vanuit een concrete intentie ("boek een meeting met Marta op donderdag"), somt de beschikbare tools op, kiest degene die het beste past, bouwt de parameters op en roept aan. Er is geen flow. Er is directe invocatie. Dat betekent dat elk endpoint zelfstandig moet zijn: de beschrijving in OpenAPI moet voldoende zijn voor een model om te begrijpen wat het doet, wanneer het te gebruiken en met welke parameters, zonder eerder een scherm te hebben gezien.
De architectonische consequentie is brutaal. Endpoints die in een SPA deel uitmaakten van een begeleide flow ("eerst POST /cart, dan POST /cart/items, dan POST /checkout") moeten opnieuw worden doordacht of expliciet gedocumenteerd als sequentie, met fouten die de volgende stap duidelijk maken. De "impliciete stappen" die de mens mentaal uitvoerde, moet nu het protocol uitvoeren.
De werkelijke kosten van scraping versus een goed ontworpen API
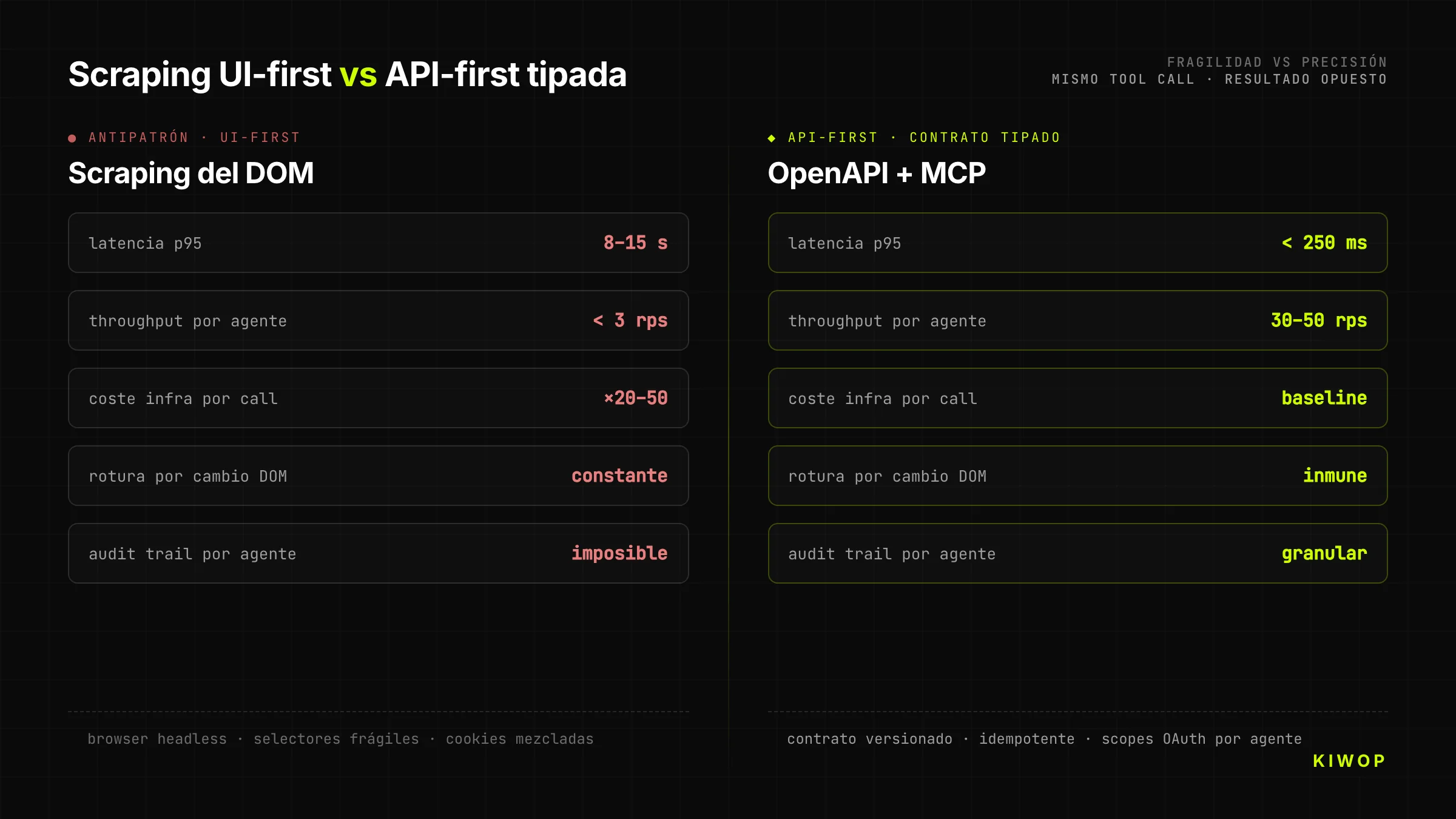
De verleiding ligt voor de hand: aangezien de website bestaat en werkt, waarom een nieuwe API bouwen? We zetten een browser-use of een puppeteer ervoor en laten de agent klikken. Het is goedkoop, snel, vereist geen aanpassingen aan de backend. Het is ook de beslissing die projecten kapotmaakt.
Scraping-as-backend heeft drie kosten die pas maanden later opduiken. Ten eerste is het fragiel: elke wijziging in de DOM breekt de agent, en omdat het frontend-team niet weet dat er agents afhankelijk zijn van de DOM, zijn wijzigingen constant. Ten tweede is het traag: een tool call tegen een goed ontworpen API wordt in 200-400 ms afgehandeld; dezelfde stap via browser duurt 8-15 seconden met het laden van CSS, JS en het wachten tot de selectors verschijnen. Ten derde is het duur: per request een headless browser draaien vermenigvuldigt de infrastructuurkosten met 20-50 ten opzichte van het serveren van JSON.
Een API die voor agents is ontworpen kost meer in de ontwerpfase, maar verdient zichzelf terug bij de eerste echte integratie. De bedrijven die bij Kiwop aankomen na een jaar "tijdelijke oplossing" met scraping komen altijd met hetzelfde symptoom: de onderhoudskosten zijn gelijk gaan staan aan de geschatte kosten om de API vanaf het begin goed te bouwen.
De pivot van Salesforce na bijna drie decennia
In februari 2026 zei Marc Benioff, CEO van Salesforce, het zonder omwegen: "APIs are the new UI". Zevenentwintig jaar na de oprichting van een bedrijf dat definieerde wat "SaaS" was, erkent Salesforce publiekelijk dat de browser niet langer het primaire contactpunt is van zijn product. Zijn focus verschuift naar het rechtstreeks laten consumeren door AI-agents van zijn data, zijn workflows, zijn tasks — via API.
Het is geen disruptieve verklaring, het is een late bevestiging. Bedrijven die vandaag nieuwe platformen bouwen nemen al aan dat de eerste echte integratie met een agent zal zijn, niet met een mens. De beweging van Salesforce is het signaal dat zelfs de grootste gevestigde spelers dezelfde realiteit accepteren. Als in 2028 een SaaS-product zijn beste DX nog steeds achter de browser heeft, is dat omdat het te laat in de cyclus zal aankomen.
De zes principes van een API-First die klaar is voor agents
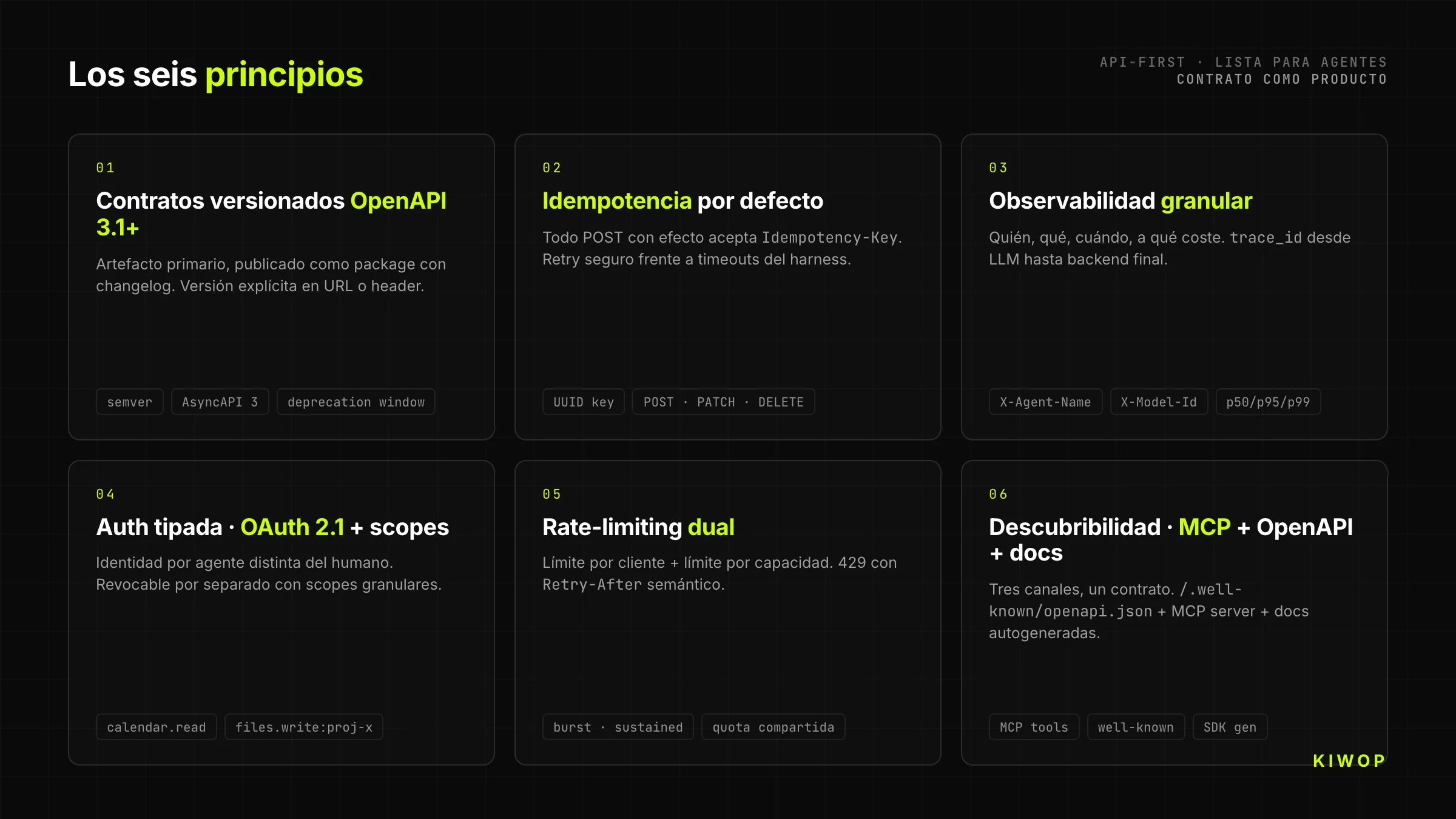
1. Versiebeheerde contracten met OpenAPI 3.1+
Elke API-First begint met een OpenAPI 3.1-contract (of AsyncAPI 3 voor event-driven) gepubliceerd als semantisch versiebeheerd artefact. Niet als PDF gegenereerd aan het eind van de sprint. Niet als zwevend bestand in Confluence. Als gepubliceerd package met changelog, dat elke consument kan vastzetten op een concrete versie en met opzet kan updaten.
De versie staat in de URL (/v2/...) of in de header (Accept-Version); het mechanisme maakt niet uit zolang het expliciet is en de server twee versies parallel kan serveren tijdens het deprecation window. Voor AI-agents is dit cruciaal: een model dat is geleerd op de v1 van jouw API mag niet breken omdat je een veld hebt toegevoegd in v2.
2. Idempotentie standaard
Agents retryen. Veel. Door timeouts, door contextverzadiging, door retry-beleid van de harness zelf. Een API-First gaat uit van idempotentie als contract: elke POST die een neveneffect genereert accepteert een Idempotency-Key-header (UUID gegenereerd door de client) en garandeert dat twee aanroepen met dezelfde key één enkel effect produceren.
De regel strekt zich uit tot PATCH, DELETE en kostbare operaties. Zonder idempotentie creëert de eerste netwerktimeout een dubbele bestelling, een dubbel verzonden e-mail of een dubbele reservering. Met idempotentie kan de agent rustig retryen en hangt je bedrijfslogica niet af van geluk.
3. Granulaire observability: wie, wat, wanneer, tegen welke kosten
Wanneer het primaire verkeer niet langer menselijk is, betekenen klassieke dashboards ("actieve gebruikers") niets meer. Wat telt is: welke agent heeft welke tool aangeroepen, met welke parameters, hoe lang duurde het, hoeveel tokens heeft hij verbruikt in het model dat hem aanriep, en of het resultaat nuttig was (heeft de agent opnieuw geprobeerd of is hij doorgegaan).
De headers User-Agent, X-Agent-Name, X-Model-Id zijn nu verplicht, niet optioneel. Gestructureerde logging bevat een trace_id die zich van de LLM tot de uiteindelijke backend propageert. En de metrics per tool — p50, p95, p99 van latency, foutpercentage, retry-percentage — zijn het nieuwe equivalent van product-KPI's.
4. Getypeerde authenticatie: OAuth + scopes per agent
Elke agent die jouw API consumeert moet zijn eigen identiteit hebben, onderscheiden van de mens die hem heeft geautoriseerd. Dit wordt geïmplementeerd met OAuth 2.1 + granulaire scopes: de mens delegeert aan zijn agent een expliciete subset van permissies (calendar.read, calendar.write:2026-05, files.read:project-x), en elke token blijft traceerbaar tot het paar (mens, agent, timestamp).
De praktische consequentie: twee agents van dezelfde mens zijn twee verschillende identiteiten. De een kan worden ingetrokken zonder de ander te breken. En de backend-logs kunnen de vraag beantwoorden die twee jaar geleden niemand stelde — "welke agent van welke mens heeft deze actie om 3 uur 's nachts uitgevoerd?".
5. Dual rate-limiting: per client en per capaciteit
Klassieke rate-limiting (X requests per minuut per token) werkt niet met agents omdat een goed gemaakte agent legitieme bursts van honderden tool calls in seconden kan genereren om een complexe taak te vervullen. De API moet twee limieten combineren: een limiet per client (om de agent tegen loops te beschermen) en een limiet per capaciteit (om de backend tegen de som van alle agents te beschermen).
De fouten 429 Too Many Requests moeten Retry-After bevatten en duidelijk onderscheid maken tussen "probeer het over 2 seconden opnieuw" en "deze operatie is voor jou 10 minuten geblokkeerd wegens misbruik". Dit verschil is wat de agent in staat stelt te redeneren over hoe hij zich moet aanpassen.
6. Vindbaarheid: MCP + OpenAPI + auto-gegenereerde docs
Een moderne API-First moet vindbaar zijn via drie complementaire kanalen. OpenAPI gepubliceerd op een voorspelbaar endpoint (/.well-known/openapi.json) voor consumptie door dev-tools en SDK's. MCP-server die dezelfde capabilities blootstelt als tools klaar om te verbinden met Claude, ChatGPT of elke agent die het protocol spreekt. En docs voor mensen auto-gegenereerd uit hetzelfde contract, voor wanneer de developer aan de andere kant met menselijke ogen wil kijken.
De drie kanalen consumeren hetzelfde contract. Als de docs en de OpenAPI uit sync raken, is er iets architectonisch mis — het contract is niet het primaire artefact.
De laag specifiek voor agents — MCP, WebMCP, A2A
OpenAPI geeft je de basis, maar om een agent jouw product met nul frictie te laten consumeren bestaat er een laag specifieke protocollen. MCP (Model Context Protocol) is de standaard om tools bloot te stellen aan een agent die in een harness draait (Claude, ChatGPT, Cursor). WebMCP doet hetzelfde vanuit de browser, zodat jouw publieke site acties blootstelt aan de agent van de gebruiker. A2A (Agent-to-Agent) orkestreert communicatie tussen agents, niet tussen agent en tools.
Ze concurreren niet met OpenAPI: ze vullen het aan. In productie is OpenAPI de waarheid van de backend; MCP en WebMCP zijn dunne adapters die dat contract vertalen naar het formaat dat de harnesses verwachten. We behandelen de technische vergelijking en wanneer je welke moet gebruiken in MCP, WebMCP en A2A: welk protocol kiezen voor jouw AI-agents.
Architectonische patronen die werken
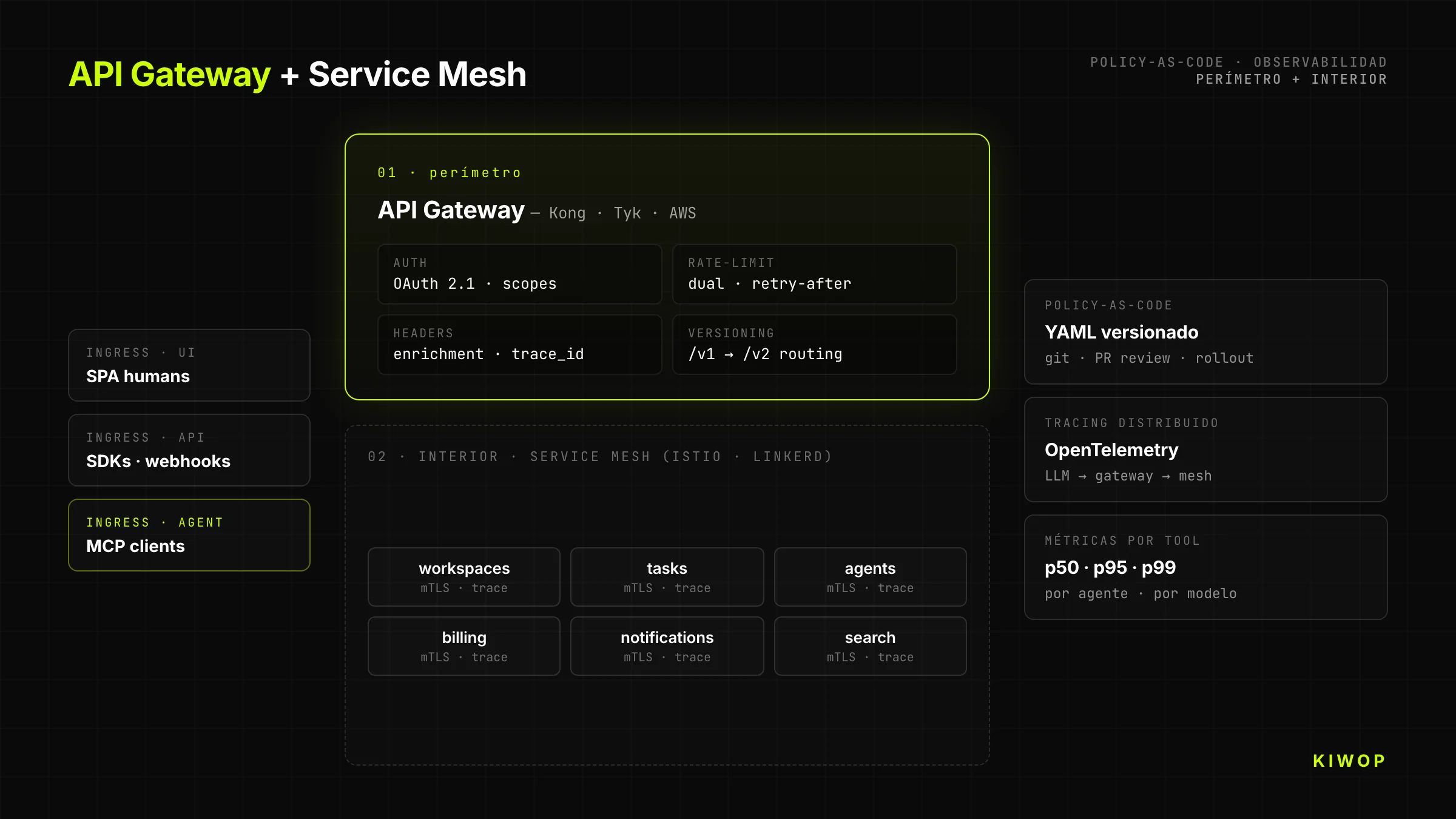
API Gateway + Service Mesh met policy-as-code
Elke serieuze API-First gaat door een gateway die policies toepast voordat ze de backend bereiken: authenticatie, rate-limiting, observability, header-enrichment, transformatie tussen versies. Onze aanbevolen stack: Kong, Tyk of AWS API Gateway voor de perimeter; Istio of Linkerd voor de interne service mesh. Policies worden als code gedefinieerd (YAML versiebeheerd in git), niet als clicks in de vendor-console.
De scheiding is belangrijk: de gateway houdt zich bezig met "welke client mag welk endpoint aanroepen"; de mesh houdt zich bezig met "welke service mag met welke service praten binnen het cluster". De twee verantwoordelijkheden mengen is de kortste weg naar een architectuur die niemand over zes maanden nog begrijpt.
Backend-for-Frontend ≠ Backend-for-Agent
Het BFF-patroon (Backend-for-Frontend) is ontstaan zodat elke UI (web, mobiel, smart TV) zijn eigen geoptimaliseerde endpoint zou hebben. De verleiding is om dit ook op agents toe te passen: een "BFA" (Backend-for-Agent) bouwen die aanroepen aggregeert om round-trips te minimaliseren.
Doe dit niet zonder er twee keer over na te denken. Een agent is geen UI met menselijke latency; het is een client die redeneert. Als je te veel aggregeert, verliest de agent granulariteit — hij kan tools niet combineren zoals hij wil. Als je te weinig aggregeert, verspilt hij context aan onnodige calls. De juiste beslissing hangt af van het geval: lees-tools kunnen profiteren van geaggregeerde endpoints (GET /dashboard die gebruiker + permissies + laatste acties teruggeeft); schrijf-tools moeten atomair en compositioneel zijn (POST /bookings geïsoleerd, zonder verborgen side-effects).
Event-driven met Kafka, NATS of Redis Streams
Agents triggeren jobs die tijd kosten. Een rapport genereren, een bestelling verwerken, een model trainen — operaties van seconden tot minuten. Ze als synchrone REST blootstellen dwingt de agent de verbinding vast te houden en context te consumeren tijdens het wachten.
Het alternatief is event-driven: de agent stuurt een POST /jobs die in minder dan 100 ms een job_id teruggeeft, raadpleegt vervolgens de status via GET /jobs/{id} of abonneert zich op een event-kanaal. Kafka of NATS voor hoog volume; Redis Streams voor lichte setups. Het patroon bevrijdt de agent van blokkeren en stelt jouw backend in staat pieken op te vangen zonder te vallen.
CQRS om luidruchtig schrijven (agents) te scheiden van kritisch lezen (mensen)
Wanneer agents de meerderheid van het schrijfverkeer worden, beginnen de mensen die hetzelfde product lezen te lijden onder contentie: trage queries, constante cache-invalidations, dashboards die lang laden. CQRS (Command Query Responsibility Segregation) scheidt het model dat schrijft van het model dat leest: agents sturen commands naar een write-side die is geoptimaliseerd voor consistency; mensen consumeren van een read-side die is geoptimaliseerd voor snelle lezing, gevoed door events vanuit de write-side.
Het is niet gratis — het voegt complexiteit en eventual consistency toe. Maar boven een bepaald volume agent-verkeer is het de enige manier om de menselijke UX intact te houden.
Antipatronen die jouw adoptie door agents doden
Antipatroon 1 — We stellen de UI bloot met cookies, "en klaar"
De eerste reflex van een haastig team is om aan een browser-use of Playwright de acties van de agent te delegeren. Werkt in de demo, faalt in productie bij de eerste DOM-rotatie. Elke visuele wijziging van de frontend (A/B-test van een knop, refactor van selectors) breekt de agent stilzwijgend. De schuld is onzichtbaar totdat het te laat is — moment waarop de kosten om de API "goed" te herbouwen verdrievoudigd zijn.
Antipatroon 2 — API's zonder expliciete versionering
Een API hebben op /api/... zonder versieprefix werkt tot de eerste breaking change. Vanaf dat moment breken alle agents in productie tegelijk. Teams die inzetten op "altijd backwards compatible" stapelen uiteindelijk 15 jaar schuld op in hetzelfde endpoint. De juiste discipline is versionering vanaf de eerste commit, met deprecation windows gedocumenteerd in de changelog.
Antipatroon 3 — Docs alleen voor mensen geschreven
Mooie pagina's in Mintlify of ReadMe met gifs en tutorials zijn nutteloos voor een agent. De agent consumeert rauwe OpenAPI, JSON Schema, TypeScript-types of een MCP-beschrijving. Als dat machine-leesbare artefact niet bestaat of verouderd is, verzint de agent. De menselijke docs worden gegenereerd vanuit het contract; niet andersom.
Antipatroon 4 — Gemengde authenticatie: menselijke sessie + agent-token op hetzelfde endpoint
Een veelgemaakte fout in teams die migreren vanuit menselijke producten: de cookie-sessie van de gebruiker hergebruiken zodat zijn agent de API aanroept "alsof hij het zelf is". Resultaat: onmogelijk te onderscheiden wie wat doet in de logs, onmogelijk een agent in te trekken zonder de menselijke sessie onderuit te halen, onmogelijk verschillende scopes per oorsprong te beperken.
De juiste scheiding: menselijke sessie met HttpOnly-cookie voor de UI; OAuth-tokens met scopes voor de agents; ieder met zijn eigen authenticatie-endpoint en zijn eigen audit trail.
Reële casus — Nexo als MCP-server
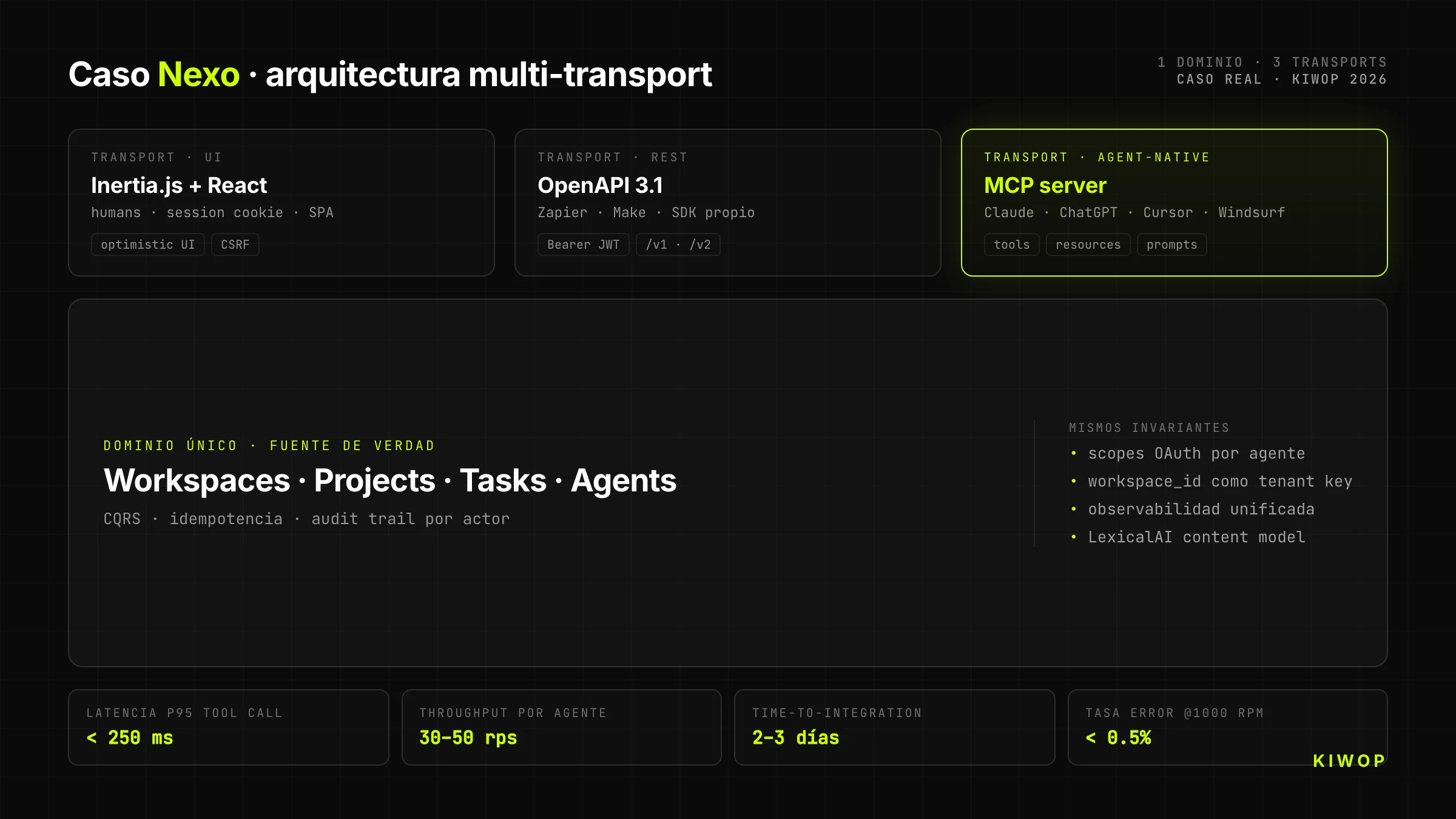
Nexo is onze eigen SaaS-workspace voor teams. Het begon als een Laravel + React + Inertia.js-app gericht op mensen (technische documentatie: Nexo: technische anatomie van onze multi-tenant SaaS). Toen we besloten het open te stellen voor AI-agents, namen we een architectonische beslissing die al het andere bepaalde: we zouden geen REST "en punt uit" blootstellen; we zouden direct een MCP-server blootstellen bovenop hetzelfde domein dat al de UI bediende.
Headless-architectuur van Nexo
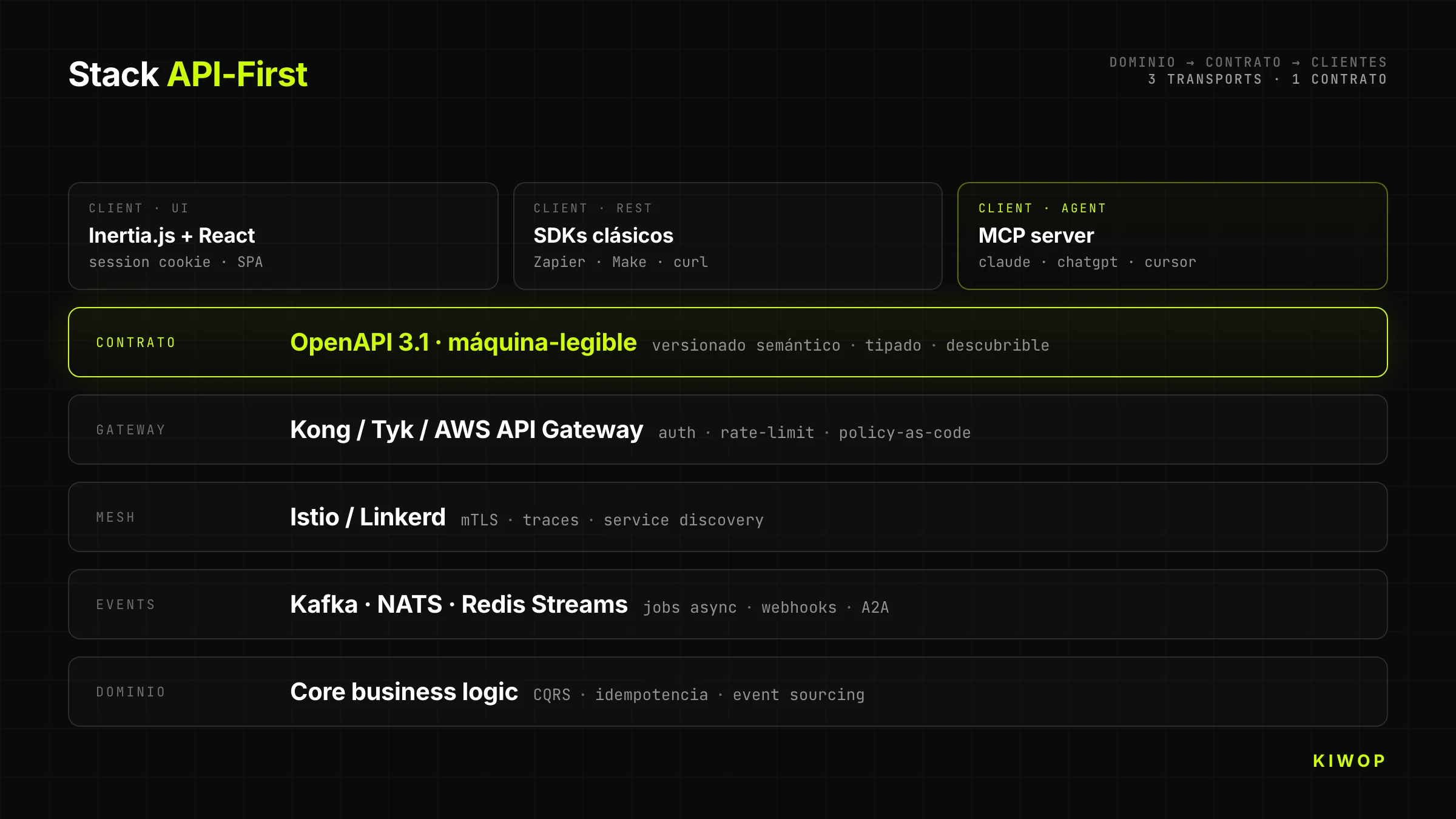
De backend van Nexo heeft één bedrijfsdomein (workspaces, projecten, taken, notities, agents). Bovenop dat domein draaien drie verschillende transports die hetzelfde contract delen:
- Inertia.js + React voor de menselijke UI (cookiesessie, optimistisch, verrijkte client)
- REST + OpenAPI 3.1 voor klassieke integraties (Zapier, Make, eigen SDK)
- MCP-server voor directe consumptie vanuit Claude, ChatGPT en elke agent met een MCP-client
Het domein is hetzelfde. Wat verandert is de transport-laag en de identiteit van de client. Dat betekent dat wanneer een agent een taak aanmaakt via MCP, die taak onmiddellijk verschijnt in de menselijke UI van dezelfde workspace, met de juiste gebruiker als eigenaar en met de agent duidelijk gelabeld als actor.
Waarom MCP in plaats van REST "en punt uit"
We hadden alleen REST kunnen blootstellen en elke integrator zijn eigen MCP-wrapper laten bouwen. We kozen ervoor native MCP bloot te stellen om drie redenen:
- Het MCP-contract vangt intentie beter op dan generieke REST. Een MCP-tool wordt beschreven met naam, beschrijving, getypeerde parameters en voorbeelden — de LLM hoeft niet te deduceren welk van de twintig REST-endpoints te gebruiken; hij ziet het letterlijk.
- Het MCP-ecosysteem groeit sneller dan welke proprietary SDK dan ook. Claude, ChatGPT, Cursor, Windsurf, VS Code, Cline — allemaal spreken MCP. Als we MCP blootstellen, consumeren ze ons allemaal vanaf dag één.
- Observability is gratis. MCP-harnesses rapporteren al welke tool is aangeroepen en met welk resultaat. We besparen onszelf het bouwen van ons eigen adoptie-dashboard per agent.
Doelmetrics (ontwerpprojecties)
De volgende cijfers zijn ontwerpdoelen gekalibreerd tegen vergelijkbare implementaties, nog geen metingen in productie op grote schaal. We publiceren ze als referentie van wat redelijk is om te verwachten van een goed gemaakte MCP-first-architectuur:
Waarden gekalibreerd in interne tests en tegen vergelijkbare literatuur; ze zullen worden verfijnd met productiedata naarmate we opschalen.
Lessen uit de eerste hand
Wat we al weten na het ontwerpen en opereren van de MCP-laag van Nexo, en wat in geen enkele paper stond toen we begonnen:
- De werkelijke architectonische kosten zijn niet MCP schrijven; het is het refactoren van je backend zodat de endpoints granulair, idempotent en compositioneel zijn. De MCP-server zelf is ~600 regels TypeScript. Het moeilijke is dat je bedrijfslaag kan verdragen wat de agents ervan vragen.
- De audit trail per agent verandert gesprekken met klanten. Wanneer een B2B-klant in zijn dashboard ziet "jouw Claude-agent heeft vrijdag de status van 14 taken gewijzigd", verandert het gesprek van "kan ik dit vertrouwen?" naar "ik wil toegang geven aan meer agents".
- Granulaire OAuth-scopes verkopen. Het eerste technische bezwaar in verkoop was altijd "en als de agent uit de hand loopt?". Een getypeerd antwoord hebben — "deze agent kan alleen project X lezen tot 31 mei" — deblokkeert de ondertekening.
Wanneer NIET migreren naar API-First
Migratie naar API-First is duur en loont niet altijd. Drie gevallen waarin onze eerlijke aanbeveling niet doen is:
- Product zonder reële agentic use case. Als je product een interne ERP is die door 30 werknemers wordt gebruikt en niemand gaat agents bouwen, zal een API-first-migratie je geen ROI opleveren. Investeer in andere dingen.
- Onvoldoende volume om de overhead terug te verdienen. Als je totale verkeer 100 requests per dag is, weegt de toegevoegde complexiteit (gateway, versionering, strikte OpenAPI, MCP) zwaarder dan het voordeel. Valideer eerst dat er vraag is.
- Team zonder DevEx-maturiteit. API-First vereist een cultuur van contract als product: gedisciplineerde changelog, contract-tests, gedocumenteerde SLA's. Zonder die cultuur raakt het contract binnen zes maanden uit sync en gaat al het werk verloren. Investeer voor de migratie in de cultuur.
Als je in een van de drie past, is het beter door te gaan met je huidige stack en het over een jaar opnieuw te bekijken.
Migratie-roadmap — waar te beginnen
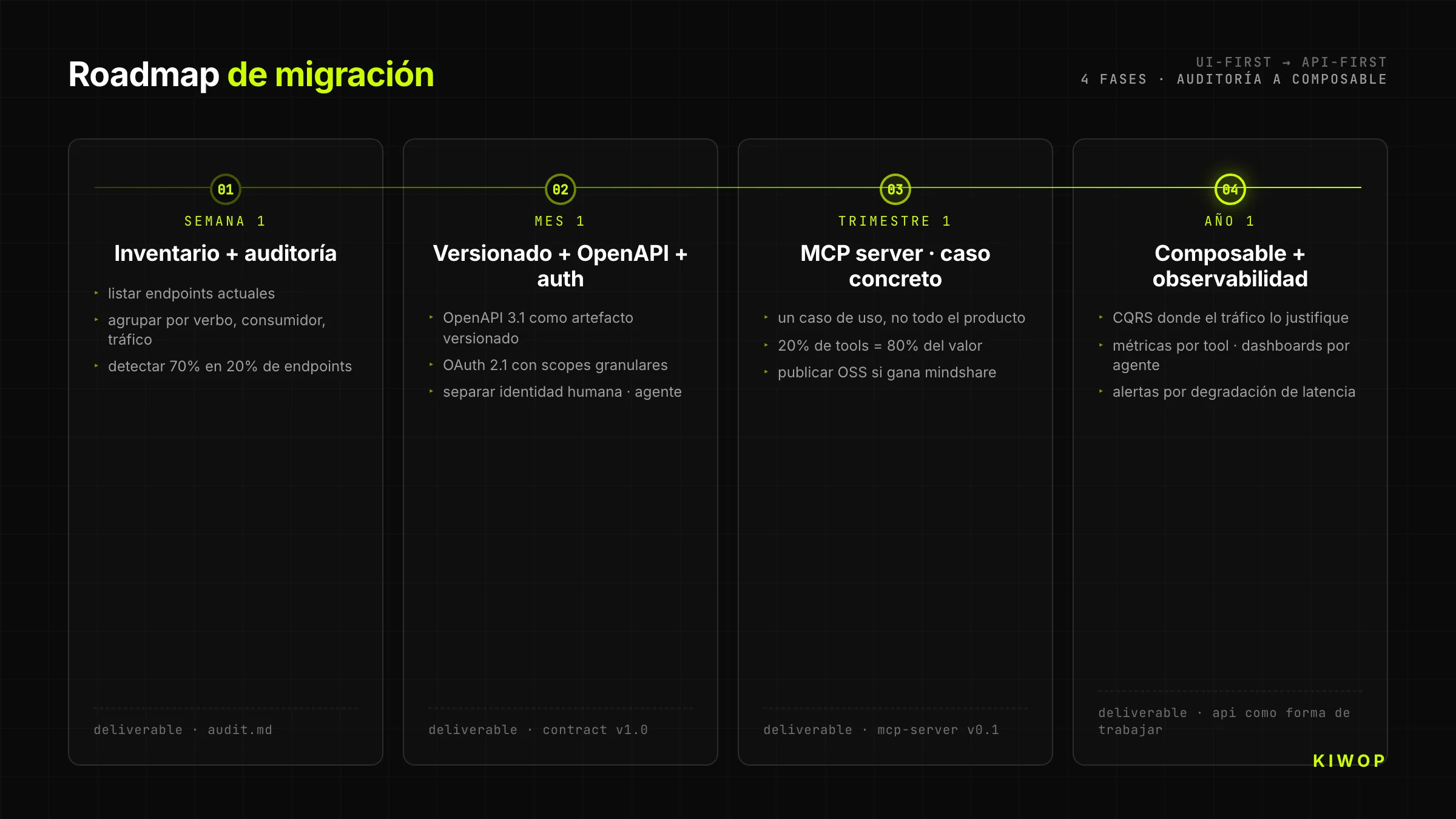
Week 1 — Inventarisatie en audit
Maak een lijst van alle huidige endpoints van je backend. Groepeer ze op HTTP-werkwoord, op consument (web, mobiel, intern), op gebruiksfrequentie. Markeer welke expliciete versionering hebben, welke gestructureerde fouten teruggeven, welke idempotentie hebben. Deze audit onthult vaak dat 70% van de code in 20% van de endpoints leeft — dat zijn de prioritaire kandidaten om API-first te maken.
Maand 1 — Versionering + OpenAPI + schone auth
Publiceer OpenAPI 3.1 als versiebeheerd artefact voor de kritieke endpoints. Migreer de authenticatie naar OAuth 2.1 met granulaire scopes. Scheid de menselijke identiteit van de agent-identiteit. Probeer niet alles te herschrijven; begin met een afgebakend domein (bijvoorbeeld alleen de module "reserveringen" of "facturen") en behandel het als proof.
Kwartaal 1 — MCP-server voor één use case
Kies een concrete use case en bouw een MCP-server die hem blootstelt. Probeer niet het hele product te dekken; dek de 20% van de tools die 80% van de waarde genereert. Publiceer de MCP-server als open-source als het zinvol is (mindshare winnen), of gesloten maar gedocumenteerd.
Jaar 1 — Composable + volledige observability
Migreer de rest van de backend naar het composable model. Implementeer CQRS waar het agent-schrijfverkeer het rechtvaardigt. Instrumenteer metrics per tool, adoptie-dashboards per agent, alerts bij latency-degradatie. Op dit punt is de API-First-architectuur geen project meer en wordt het de manier van werken van het team.
Veelgestelde vragen
Wat is API-First in één regel?
Een architectuur waarin het machine-leesbare contract wordt ontworpen, versiebeheerd en gepubliceerd vóór welke menselijke interface dan ook die het consumeert.
Is het hetzelfde als headless?
Nee. Headless betekent "zonder presentatielaag gekoppeld aan de backend" — het is een structurele eigenschap. API-First is een ontwerpdiscipline: het contract komt eerst. Elke API-First-architectuur is headless, maar niet elke headless is API-First (je kunt headless hebben met een belabberd contract).
Heb ik MCP nodig als ik al REST heb?
Niet strikt, maar MCP versnelt de adoptie door agents brutaal. Als je klanten je product gaan consumeren via Claude, ChatGPT of Cursor, bespaart native MCP blootstellen hen het bouwen van hun eigen adapter. De technische behandeling staat in MCP, WebMCP en A2A: protocollen voor AI-agents.
Hoe wordt een API die door agents wordt geconsumeerd gemonetariseerd?
Het klassieke model (prijs per gebruiker) past niet — een agent is geen gebruiker. De modellen die werken: prijs per volume (requests of verbruikte tokens), prijs per geleverde waarde (aantal voltooide acties), prijs per verbonden agent (licentie per bot). Sommige platforms rekenen per agent-tier op basis van kriticiteit.
Hoeveel kost het om van UI-First naar API-First te migreren?
Hangt af van het vertrekpunt, maar een eerlijke migratie voor een middelgroot SaaS-platform (50-200 endpoints) ligt tussen 3 en 9 maanden met een toegewijd team. De grootste kosten zijn niet technisch maar cultureel — het eens worden dat het contract het primaire artefact is.
Wat gebeurt er met mijn SEO als ik geen UI meer heb?
API-First betekent niet het elimineren van de publieke UI. De UI blijft voor mensen en SEO; wat je toevoegt is de API/MCP-laag voor agents. Het interessante is dat je met WebMCP directe acties kunt blootstellen aan de AI-agents die je site bezoeken, wat nieuwe acquisitie-oppervlakken opent.
Conclusie
Een API-First-architectuur is geen technische luxe of modegril; het is de manier om product te bouwen wanneer de primaire consument geen mens meer is en een agent wordt. De publieke pivot van Salesforce in 2026 is de late bevestiging van iets dat de teams die vandaag bouwen al voor gegeven aannemen: de API is de front door en de UI is gewoon een client.
Bij Kiwop — Digitaal agentschap gespecialiseerd in softwareontwikkeling en toegepaste kunstmatige intelligentie voor wereldwijde klanten in Europa en de VS — hebben we Nexo met dit model vanaf dag één gebouwd, en helpen we technische teams hun huidige architectuur te diagnosticeren en de kortste weg naar API-First te tekenen zonder te breken wat al werkt. Als je de migratie overweegt, vraag een audit aan van de API-first-architectuur of bekijk onze diensten voor ontwikkeling van AI-agents, consultancy in kunstmatige intelligentie en LLM-integratie.
En als je de technische richting interessant vond, volg de lijn met de cluster-posts: MCP, WebMCP en A2A: protocollen voor AI-agents, AI-agents in productie: patronen en antipatronen, Nexo: technische anatomie van onze multi-tenant SaaS en van OpenClaw naar PA met Claude Code en MCP.


