Vom Kiwop-Team · Digitalagentur spezialisiert auf Softwareentwicklung und angewandte Künstliche Intelligenz für globale Kunden in Europa und den USA · Veröffentlicht am 20. April 2026 · Zuletzt aktualisiert: 20. April 2026
TL;DR — Eine API-First-Architektur entwirft das System ausgehend von seinen maschinenlesbaren Verträgen, bevor irgendeine menschliche Schnittstelle existiert. Sobald der Hauptkonsument kein Browser mehr ist, sondern ein KI-Agent, trennt genau das die Produkte, die überleben, von denen, die es nicht tun. Dieser Leitfaden fasst die sechs Prinzipien zusammen, die Muster, die funktionieren, die vier Antipatterns, die die Adoption töten, und den realen Fall Nexo — unser SaaS, das MCP als nativen Vertrag freilegt.
 KI-Agenten — Diagramm des Headless-Stacks von Kiwop mit MCP, OpenAPI, API Gateway und Event-Driven" width="800" height="450" loading="lazy" />
KI-Agenten — Diagramm des Headless-Stacks von Kiwop mit MCP, OpenAPI, API Gateway und Event-Driven" width="800" height="450" loading="lazy" />Jede Woche kommt derselbe Anruf aus einem technischen Komitee: "Wir wollen unser Produkt für KI-Agenten öffnen, aber unser Backend wurde für eine SPA entworfen". Die ehrliche Antwort lautet nie: "Stellt einen REST-Endpoint bereit und fertig". Die richtige Antwort beginnt mit einer Frage: Ist eure Architektur darauf ausgelegt, dass der Hauptkonsument eine Maschine ist, oder ein Mensch mit Maus? Wenn Letzteres, zahlt jeder neue Agent, den ihr anbindet, die Mismatch-Steuer — Latenz, fragiles Scraping, schlecht verwaltete Retries, zwischen Menschen und Bots geteilte Accounts. API-First ist kein Coding-Stil; es ist die architektonische Entscheidung, die diese Steuer ab Tag eins eliminiert.
Was ist die API-First-Architektur (operative Definition)
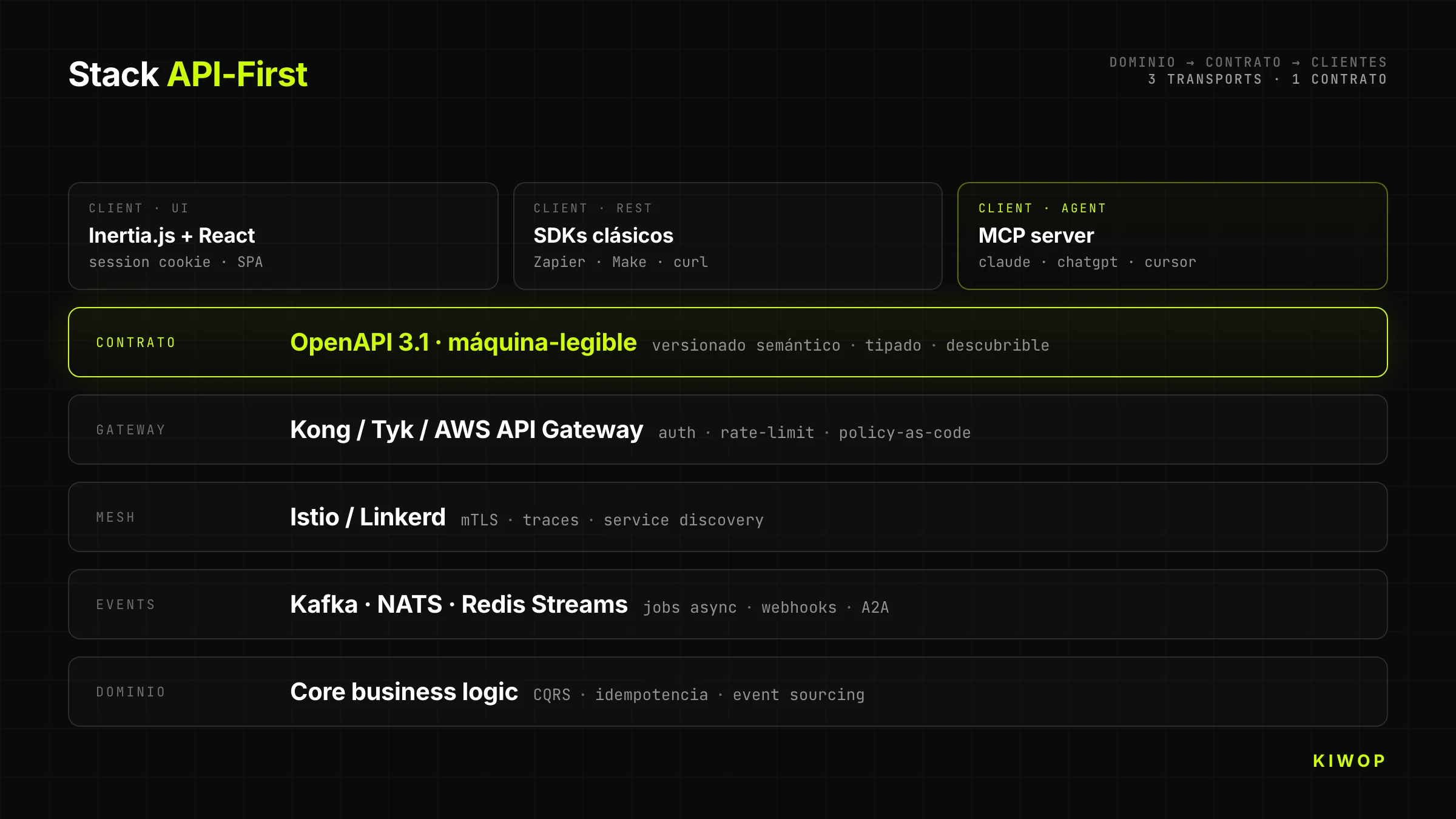
Eine API-First-Architektur ist eine, in der jeder maschinenlesbare Vertrag — seine Shape, seine Version, seine Authentifizierung, seine Observability — vor jeder konsumierenden Benutzeroberfläche entworfen und validiert wird. Das Backend exponiert nicht "das, was die SPA heute braucht"; es exponiert einen öffentlichen, typisierten, versionierten, dokumentierten und auffindbaren Vertrag, von dem jeder Client (Web, Mobile, Dritte, KI-Agenten) das konsumiert, was ihn interessiert.
Der Schlüsselunterschied ist nicht technisch, sondern eine Frage der Reihenfolge. In API-First ist der Vertrag das primäre Artefakt — er wird im PR reviewed, als OpenAPI oder AsyncAPI veröffentlicht, als eigenständige Library versioniert. Die UI kommt danach und der Agent kommt danach. Alle sind Clients desselben First-Class-Citizen.
API-First vs. API-Design-First vs. Code-First
Drei Begriffe, die austauschbar verwendet werden, aber unterschiedliche Dinge bedeuten:
- Code-First: Der Code kommt zuerst. Der Vertrag (OpenAPI, gRPC, GraphQL-Schema) wird aus dem Code generiert. Schnell zu starten, teuer zu warten. Der Vertrag liegt immer einen Schritt zurück.
- API-Design-First: Der Vertrag wird als menschenlesbares Dokument entworfen, bevor Code geschrieben wird. Nützlich zur Koordination großer Teams, garantiert aber nicht, dass der Hauptkonsument eine Maschine ist.
- API-First: Der maschinenlesbare Vertrag ist das erste, letzte und ständige Artefakt. Er wird als Produkt mit eigener Roadmap, SLA, Changelog und Support entworfen. Die UI ist nur ein weiterer Client.
Unsere Empfehlung für jede Plattform, die sich KI-Agenten öffnen will: API-First mit API-Design-First als Team-Ritual. Der Vertrag lebt in seinem eigenen Repo oder Package, wird im PR reviewed und semantisch versioniert veröffentlicht.
Warum bei KI-Agenten die API DIE UI IST
Historisch war die UI das Produkt und die API ein Extra. Unternehmen investierten in Interaktionsdesign, A/B-Tests von Buttons, visuelle Onboarding-Flows. Die API existierte als Hintertür für Integrationen oder SDKs, aber das Produktbudget lag im Screen.
Mit KI-Agenten kehrt sich diese Hierarchie um. Ein Agent sieht deinen Header nicht, klickt nicht auf dein CTA, würdigt deine Loading-Animation nicht. Das Einzige, was er sieht, ist der Vertrag — und wenn der Vertrag mehrdeutig ist, schlecht versioniert oder Endpoints enthält, die HTML zurückgeben, wenn sie JSON hätten zurückgeben sollen, scheitert der Agent lautlos oder — schlimmer — halluziniert Antworten.
Die API ist keine Hintertür mehr. Sie ist die Vordertür. Das gesamte Produktbudget, das früher in das Polieren der UI floss, muss jetzt in das Polieren des Vertrags fließen: klare Feldnamen, Beispiele in der Doku, strukturierte Fehler, konsistente Paginierung, explizite Idempotenz. Ein Produkt mit schlechter API, aber guter UI, konnte sich noch an Menschen verkaufen. Ein Produkt mit schlechter API in einer Agentenwelt schafft es nicht einmal zur ersten Integration.
Warum KI-Agenten das UI-first-Paradigma sprengen
Agenten navigieren nicht, sie rufen typisierte Verträge auf
Ein Mensch entdeckt dein Produkt über den Flow: Er kommt über die Startseite, liest ein Feature, klickt auf "Loslegen", füllt ein Formular aus, bestätigt per E-Mail. Jeder Schritt liefert Kontext für den nächsten.
Ein KI-Agent macht genau das Gegenteil: Er startet mit einer konkreten Absicht ("Buche einen Termin mit Marta am Donnerstag"), listet die verfügbaren Tools auf, wählt das am besten passende, baut die Parameter zusammen und ruft auf. Es gibt keinen Flow. Es gibt direkten Aufruf. Das bedeutet, dass jeder Endpoint selbstenthaltend sein muss: Seine OpenAPI-Beschreibung muss ausreichen, damit ein Modell versteht, was er tut, wann er zu verwenden ist und mit welchen Parametern — ohne jemals einen Screen gesehen zu haben.
Die architektonische Konsequenz ist brutal. Endpoints, die in einer SPA Teil eines geführten Flows waren ("erst POST /cart, dann POST /cart/items, dann POST /checkout"), müssen überdacht oder explizit als Sequenz dokumentiert werden — mit Fehlern, die den nächsten Schritt klarmachen. Die "impliziten Schritte", die der Mensch im Kopf machte, muss jetzt das Protokoll ausführen.
Die realen Kosten von Scraping vs. gut designter API
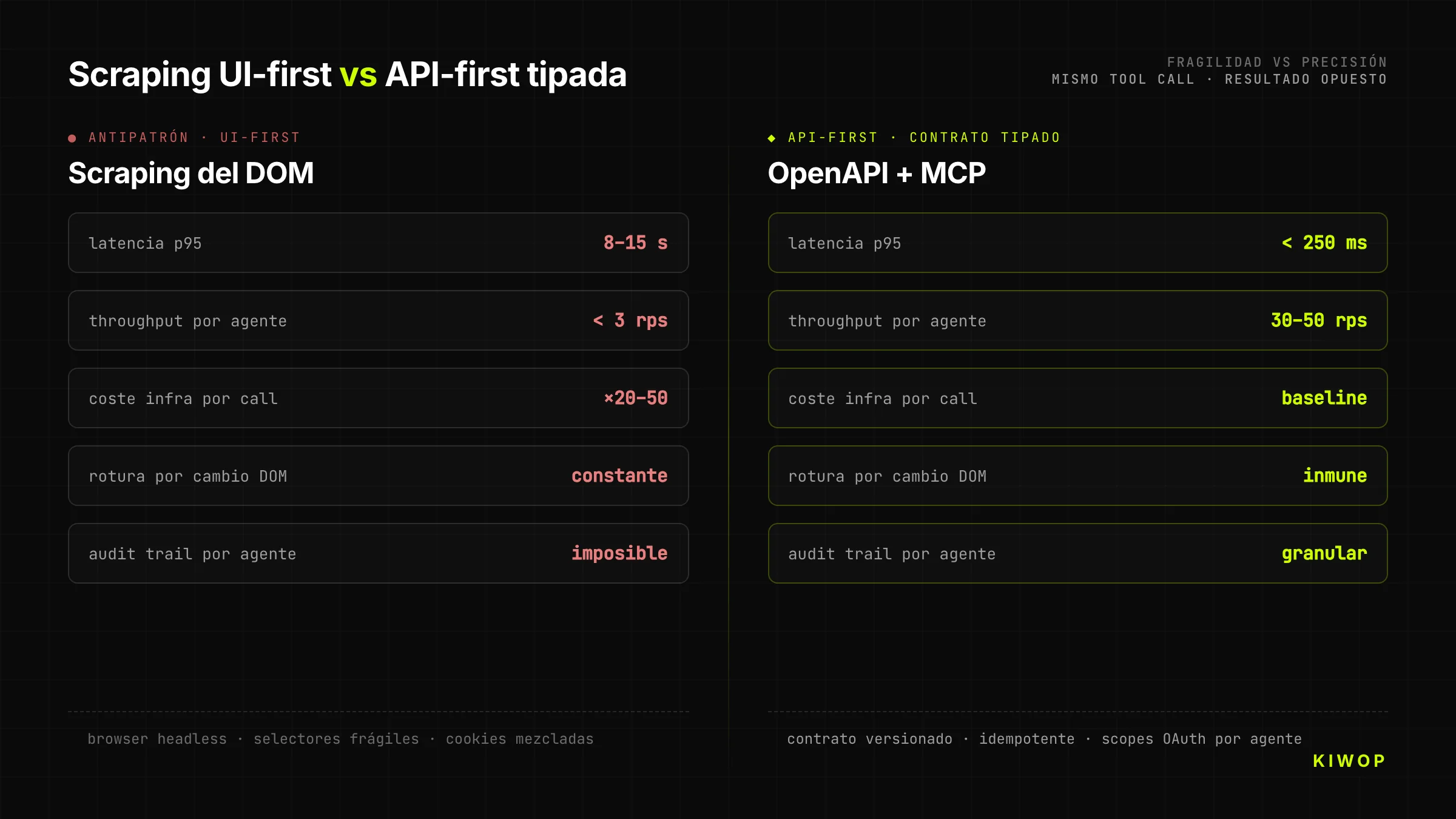
Die Versuchung liegt auf der Hand: Die Website existiert bereits und funktioniert — warum eine neue API bauen? Wir schalten einen Browser-Use oder Puppeteer davor und lassen den Agenten klicken. Billig, schnell, kein Backend-Eingriff. Es ist auch die Entscheidung, die Projekte zerstört.
Scraping-as-Backend hat drei Kosten, die erst nach Monaten auftauchen. Erstens, es ist fragil: Jede DOM-Änderung zerbricht den Agenten, und da das Frontend-Team nicht weiß, dass Agenten vom DOM abhängen, sind die Änderungen ständig. Zweitens, es ist langsam: Ein Tool-Call gegen eine gut designte API löst in 200–400 ms auf; derselbe Schritt per Browser dauert 8–15 Sekunden — CSS, JS laden und warten, bis die Selektoren erscheinen. Drittens, es ist teuer: Einen Headless-Browser pro Request zu fahren, multipliziert die Infrastrukturkosten um Faktor 20–50 gegenüber dem Ausliefern von JSON.
Eine für Agenten designte API kostet in der Designphase mehr, amortisiert sich aber bei der ersten echten Integration. Unternehmen, die mit einem Jahr "Übergangslösung" per Scraping zu Kiwop kommen, kommen immer mit demselben Symptom: Die Wartungskosten haben die geschätzten Kosten für den sauberen Aufbau der API vom Start weg eingeholt.
Der Pivot von Salesforce nach fast drei Jahrzehnten
Im Februar 2026 sagte es Marc Benioff, CEO von Salesforce, ohne Umschweife: "APIs are the new UI". Siebenundzwanzig Jahre nach Gründung eines Unternehmens, das definierte, was "SaaS" ist, erkennt Salesforce öffentlich an, dass der Browser nicht mehr der primäre Kontaktpunkt ihres Produkts ist. Ihr Fokus verlagert sich darauf, dass KI-Agenten ihre Daten, ihre Workflows, ihre Tasks direkt konsumieren — per API.
Es ist keine disruptive Erklärung, es ist eine späte Bestätigung. Unternehmen, die heute neue Plattformen bauen, gehen bereits davon aus, dass die erste echte Integration mit einem Agenten erfolgen wird, nicht mit einem Menschen. Der Move von Salesforce ist das Signal, dass selbst die größten Incumbents dieselbe Realität akzeptieren. Wenn 2028 ein SaaS-Produkt seine beste DX noch hinter dem Browser versteckt, kommt es zu spät im Zyklus.
Die sechs Prinzipien einer agentenreifen API-First
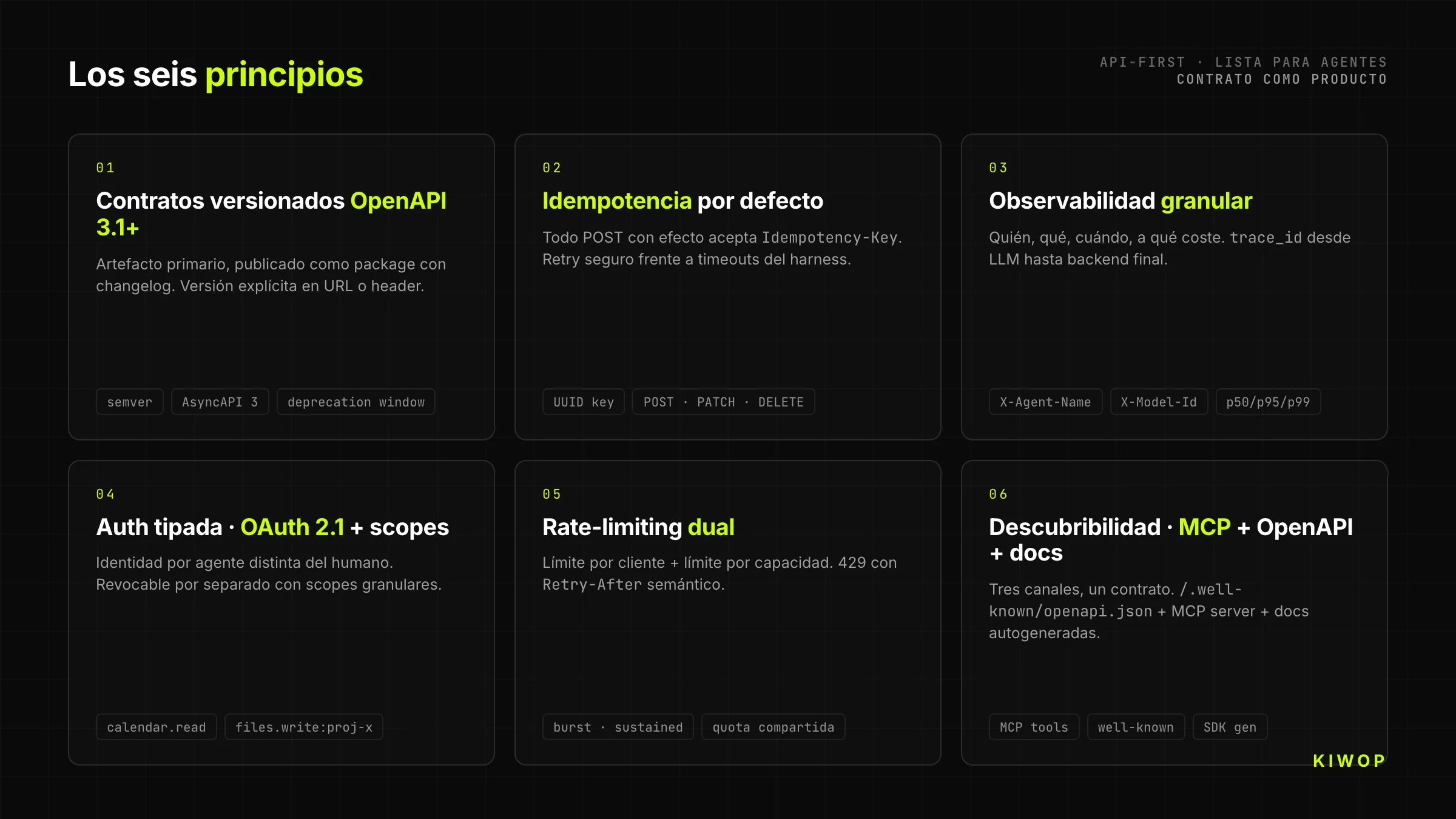
1. Versionierte Verträge mit OpenAPI 3.1+
Jede API-First beginnt mit einem OpenAPI-3.1-Vertrag (oder AsyncAPI 3 für Event-Driven), der als semantisch versioniertes Artefakt veröffentlicht wird. Nicht als PDF, das am Ende des Sprints generiert wird. Nicht als frei schwebende Datei in Confluence. Als veröffentlichtes Package mit Changelog, das jeder Konsument auf eine konkrete Version pinnen und bewusst aktualisieren kann.
Die Version steht in der URL (/v2/...) oder im Header (Accept-Version); der Mechanismus ist egal, solange er explizit ist und der Server zwei Versionen parallel während des Deprecation-Windows bedienen kann. Für KI-Agenten ist das kritisch: Ein auf der v1 deiner API trainiertes Modell darf nicht kaputtgehen, weil du in v2 ein Feld hinzugefügt hast.
2. Idempotenz per Default
Agenten retryen. Und zwar viel. Wegen Timeouts, wegen Kontextsättigung, wegen Retry-Policies des Harness selbst. Eine API-First setzt Idempotenz als Vertrag voraus: Jeder POST, der einen Seiteneffekt erzeugt, akzeptiert einen Idempotency-Key-Header (UUID vom Client generiert) und garantiert, dass zwei Calls mit demselben Key einen einzigen Effekt erzeugen.
Die Regel erstreckt sich auf PATCH, DELETE und teure Operationen. Ohne Idempotenz erzeugt der erste Netzwerk-Timeout eine doppelte Bestellung, eine zweimal gesendete E-Mail oder eine doppelte Reservierung. Mit Idempotenz kann der Agent gelassen retryen, und deine Business-Logik hängt nicht vom Zufall ab.
3. Granulare Observability: Wer, was, wann, zu welchen Kosten
Wenn der Haupttraffic nicht mehr menschlich ist, repräsentieren die klassischen Dashboards ("Aktive Nutzer") nichts mehr. Was zählt: welcher Agent welches Tool mit welchen Parametern aufgerufen hat, wie lange es dauerte, wie viele Tokens im aufrufenden Modell verbraucht wurden, und ob das Ergebnis nützlich war (hat der Agent retryed oder ist er weitergezogen).
Die Header User-Agent, X-Agent-Name, X-Model-Id sind jetzt Pflicht, nicht optional. Das strukturierte Logging enthält eine trace_id, die vom LLM bis zum finalen Backend propagiert wird. Und die Metriken pro Tool — p50, p95, p99 der Latenz, Fehlerquote, Retry-Rate — sind das neue Äquivalent der Produkt-KPIs.
4. Typisierte Authentifizierung: OAuth + Scopes pro Agent
Jeder Agent, der deine API konsumiert, muss eine eigene Identität haben — getrennt von der des Menschen, der ihn autorisiert hat. Das wird mit OAuth 2.1 + granularen Scopes umgesetzt: Der Mensch delegiert an seinen Agenten eine explizite Teilmenge von Permissions (calendar.read, calendar.write:2026-05, files.read:project-x), und jedes Token bleibt rückverfolgbar bis zum Paar (Mensch, Agent, Timestamp).
Die praktische Konsequenz: Zwei Agenten desselben Menschen sind zwei unterschiedliche Identitäten. Einer kann revoked werden, ohne den anderen zu brechen. Und die Backend-Logs können die Frage beantworten, die sich vor zwei Jahren niemand gestellt hat — "welcher Agent welches Menschen hat diese Aktion um 3 Uhr morgens ausgeführt?".
5. Duales Rate-Limiting: pro Client und pro Kapazität
Klassisches Rate-Limiting (X Requests pro Minute pro Token) funktioniert nicht mit Agenten, weil ein gut gebauter Agent legitime Bursts von Hunderten von Tool-Calls innerhalb von Sekunden erzeugen kann, um einen komplexen Task abzuschließen. Die API muss zwei Limits kombinieren: ein Limit pro Client (um den Agenten vor Loops zu schützen) und ein Limit pro Kapazität (um das Backend vor der Summe aller Agenten zu schützen).
429 Too Many Requests-Fehler müssen Retry-After enthalten und klar unterscheiden zwischen "versuche es in 2 Sekunden erneut" und "diese Operation ist wegen Missbrauchs 10 Minuten lang für dich gesperrt". Dieser Unterschied ist es, der dem Agenten erlaubt, zu räsonieren, wie er sich anpasst.
6. Discoverability: MCP + OpenAPI + autogenerierte Docs
Eine moderne API-First sollte über drei komplementäre Kanäle auffindbar sein. OpenAPI publiziert an einem vorhersagbaren Endpoint (/.well-known/openapi.json) für den Konsum durch Dev-Tools und SDKs. MCP-Server, der dieselben Capabilities als Tools bereitstellt, fertig zum Anbinden an Claude, ChatGPT oder jeden Agenten, der das Protokoll spricht. Und Docs für Menschen, autogeneriert aus demselben Vertrag, für den Fall, dass der Entwickler auf der anderen Seite mit menschlichen Augen draufschauen muss.
Alle drei Kanäle konsumieren denselben Vertrag. Wenn Docs und OpenAPI desynchronisieren, stimmt etwas architektonisch nicht — der Vertrag ist nicht das primäre Artefakt.
Die agentenspezifische Schicht — MCP, WebMCP, A2A
OpenAPI liefert die Basis, aber damit ein Agent dein Produkt ohne Reibung konsumiert, gibt es eine spezifische Protokollschicht. MCP (Model Context Protocol) ist der Standard, um Tools an einen Agenten bereitzustellen, der in einem Harness läuft (Claude, ChatGPT, Cursor). WebMCP tut dasselbe vom Browser aus, damit deine öffentliche Website Aktionen an den Agenten des Nutzers exponiert. A2A (Agent-to-Agent) orchestriert Kommunikation zwischen Agenten, nicht zwischen Agent und Tools.
Sie konkurrieren nicht mit OpenAPI: Sie ergänzen es. In Produktion ist OpenAPI die Wahrheit des Backends; MCP und WebMCP sind dünne Adapter, die diesen Vertrag in das Format übersetzen, das die Harnesses erwarten. Den technischen Vergleich und wann was zu verwenden ist, behandeln wir in MCP, WebMCP und A2A: welches Protokoll für deine KI-Agenten.
Architekturmuster, die funktionieren
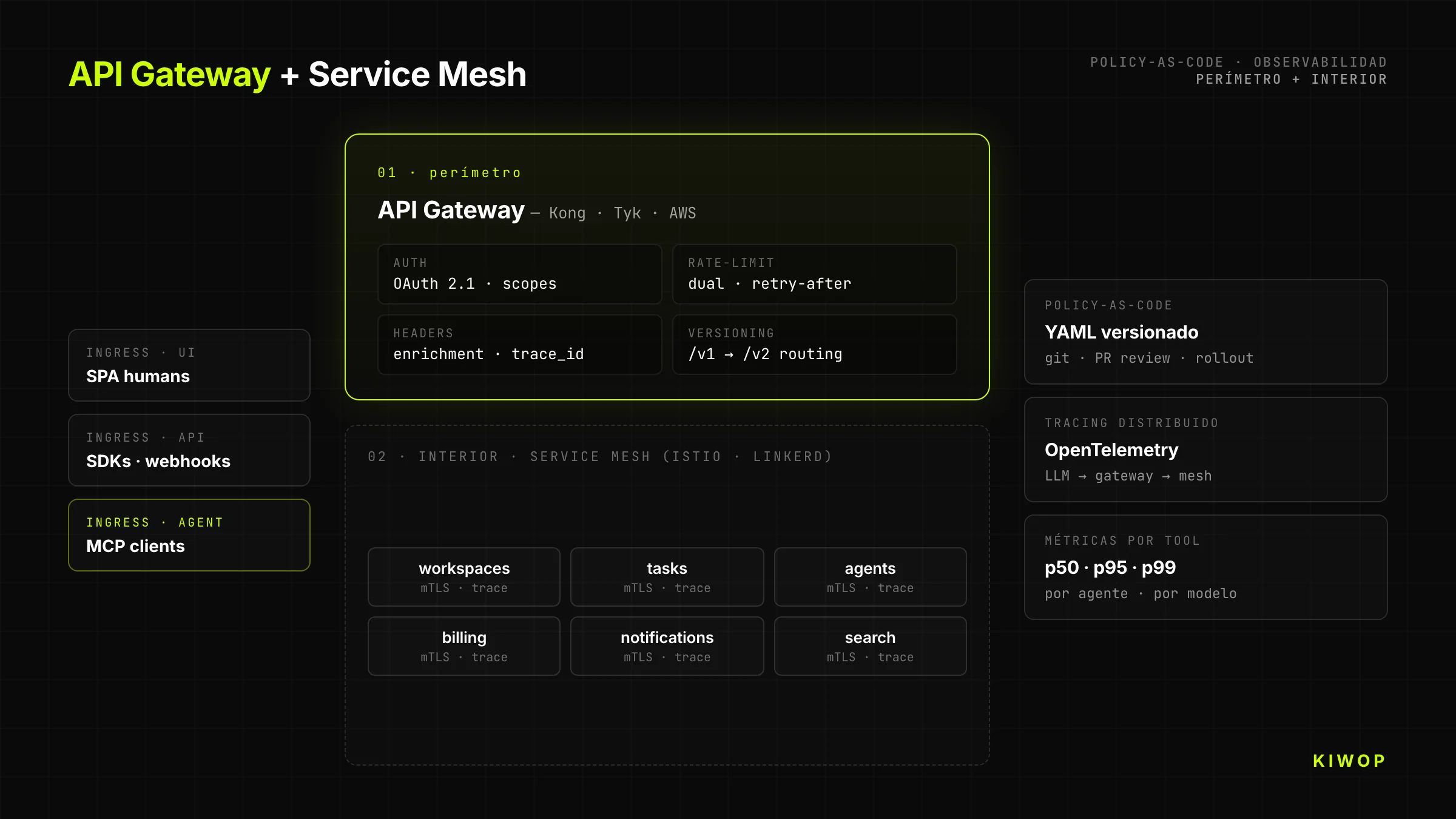
API Gateway + Service Mesh mit Policy-as-Code
Jede ernsthafte API-First läuft durch ein Gateway, das Policies anwendet, bevor es zum Backend geht: Authentifizierung, Rate-Limiting, Observability, Header-Enrichment, Versions-Transformation. Unser empfohlener Stack: Kong, Tyk oder AWS API Gateway für den Perimeter; Istio oder Linkerd für das interne Service Mesh. Die Policies werden als Code definiert (versioniertes YAML in Git), nicht als Klicks in der Vendor-Konsole.
Die Trennung ist wichtig: Das Gateway kümmert sich darum, "welcher Client welchen Endpoint aufrufen darf"; das Mesh kümmert sich darum, "welcher Service mit welchem Service innerhalb des Clusters sprechen darf". Diese beiden Verantwortungen zu vermischen, ist der kürzeste Weg zu einer Architektur, die in sechs Monaten niemand mehr versteht.
Backend-for-Frontend ≠ Backend-for-Agent
Das BFF-Pattern (Backend-for-Frontend) entstand, damit jede UI (Web, Mobile, Smart TV) ihren eigenen optimierten Endpoint hat. Die Versuchung liegt nahe, es auch auf Agenten anzuwenden: ein "BFA" (Backend-for-Agent) zu bauen, das Calls aggregiert, um Round-Trips zu minimieren.
Tu es nicht, ohne zweimal nachzudenken. Ein Agent ist keine UI mit menschlicher Latenz; er ist ein Client, der räsoniert. Wenn du zu viel aggregierst, verliert der Agent Granularität — er kann Tools nicht mehr beliebig kombinieren. Wenn du zu wenig aggregierst, verschwendet er Kontext in unnötigen Calls. Die richtige Entscheidung hängt vom Fall ab: Read-Tools können von aggregierten Endpoints profitieren (GET /dashboard liefert User + Permissions + letzte Aktionen); Write-Tools müssen atomar und kompositionsfähig sein (POST /bookings isoliert, ohne versteckte Seiteneffekte).
Event-Driven mit Kafka, NATS oder Redis Streams
Agenten stoßen Jobs an, die dauern. Einen Report generieren, eine Bestellung verarbeiten, ein Modell trainieren — Operationen im Bereich von Sekunden bis Minuten. Sie als synchrones REST freizugeben, zwingt den Agenten, die Verbindung zu halten und Kontext im Warten zu verbrennen.
Die Alternative ist Event-Driven: Der Agent schickt einen POST /jobs, der in weniger als 100 ms eine job_id zurückgibt, dann fragt er den Status per GET /jobs/{id} ab oder abonniert einen Event-Channel. Kafka oder NATS für hohes Volumen; Redis Streams für leichte Setups. Das Pattern befreit den Agenten vom Blockieren und erlaubt deinem Backend, Spikes zu absorbieren, ohne zu fallen.
CQRS zur Trennung von lautem Write (Agenten) und kritischem Read (Menschen)
Wenn Agenten zur Mehrheit des Write-Traffics werden, beginnen die Menschen, die dasselbe Produkt lesen, unter Contention zu leiden: langsame Queries, ständige Cache-Invalidierungen, Dashboards, die ewig laden. CQRS (Command Query Responsibility Segregation) trennt das Write-Modell vom Read-Modell: Agenten senden Commands an eine auf Konsistenz optimierte Write-Side; Menschen konsumieren aus einer auf schnelles Lesen optimierten Read-Side, die per Events aus der Write-Side gefüttert wird.
Es ist nicht umsonst — es fügt Komplexität und Eventual Consistency hinzu. Aber oberhalb eines bestimmten Volumens von Agenten-Traffic ist es die einzige Möglichkeit, die menschliche UX unbeschadet zu halten.
Antipatterns, die deine Agenten-Adoption töten
Antipattern 1 — Wir exponieren die UI mit Cookies, "und fertig"
Der erste Reflex eines gehetzten Teams ist, die Agenten-Aktionen an einen Browser-Use oder Playwright zu delegieren. Funktioniert in der Demo, scheitert in Produktion bei der ersten DOM-Rotation. Jede visuelle Frontend-Änderung (A/B-Test eines Buttons, Selektor-Refactor) bricht den Agenten lautlos. Die Schuld ist unsichtbar — bis sie es nicht mehr ist, und dann kostet der saubere API-Neuaufbau das Dreifache.
Antipattern 2 — APIs ohne explizite Versionierung
Eine API unter /api/... ohne Versions-Prefix zu haben, funktioniert bis zur ersten Breaking Change. Ab da brechen alle Agenten in Produktion gleichzeitig. Teams, die auf "immer rückwärtskompatibel" setzen, häufen am Ende 15 Jahre Schuld in demselben Endpoint an. Die richtige Disziplin ist Versionierung vom ersten Commit an, mit Deprecation-Windows, die im Changelog dokumentiert sind.
Antipattern 3 — Docs, die nur für Menschen geschrieben sind
Schöne Seiten in Mintlify oder ReadMe mit GIFs und Tutorials sind für einen Agenten nutzlos. Der Agent konsumiert rohes OpenAPI, JSON Schema, TypeScript-Typen oder eine MCP-Beschreibung. Wenn dieses maschinenlesbare Artefakt nicht existiert oder veraltet ist, halluziniert der Agent. Die menschliche Doku wird aus dem Vertrag generiert; nicht umgekehrt.
Antipattern 4 — Gemischte Authentifizierung: menschliche Session + Agent-Token am selben Endpoint
Ein häufiger Fehler bei Teams, die von menschenzentrierten Produkten migrieren: Die Cookie-Session des Users wiederverwenden, damit sein Agent "als wäre er er" die API aufruft. Ergebnis: Es ist unmöglich, in den Logs zu unterscheiden, wer was macht; unmöglich, einen Agenten zu revoken, ohne die menschliche Session zu kippen; unmöglich, unterschiedliche Scopes je Origin zu begrenzen.
Die richtige Trennung: menschliche Session mit HttpOnly-Cookie für die UI; OAuth-Tokens mit Scopes für die Agenten; jeder mit eigenem Auth-Endpoint und eigenem Audit-Trail.
Realer Fall — Nexo als MCP-Server
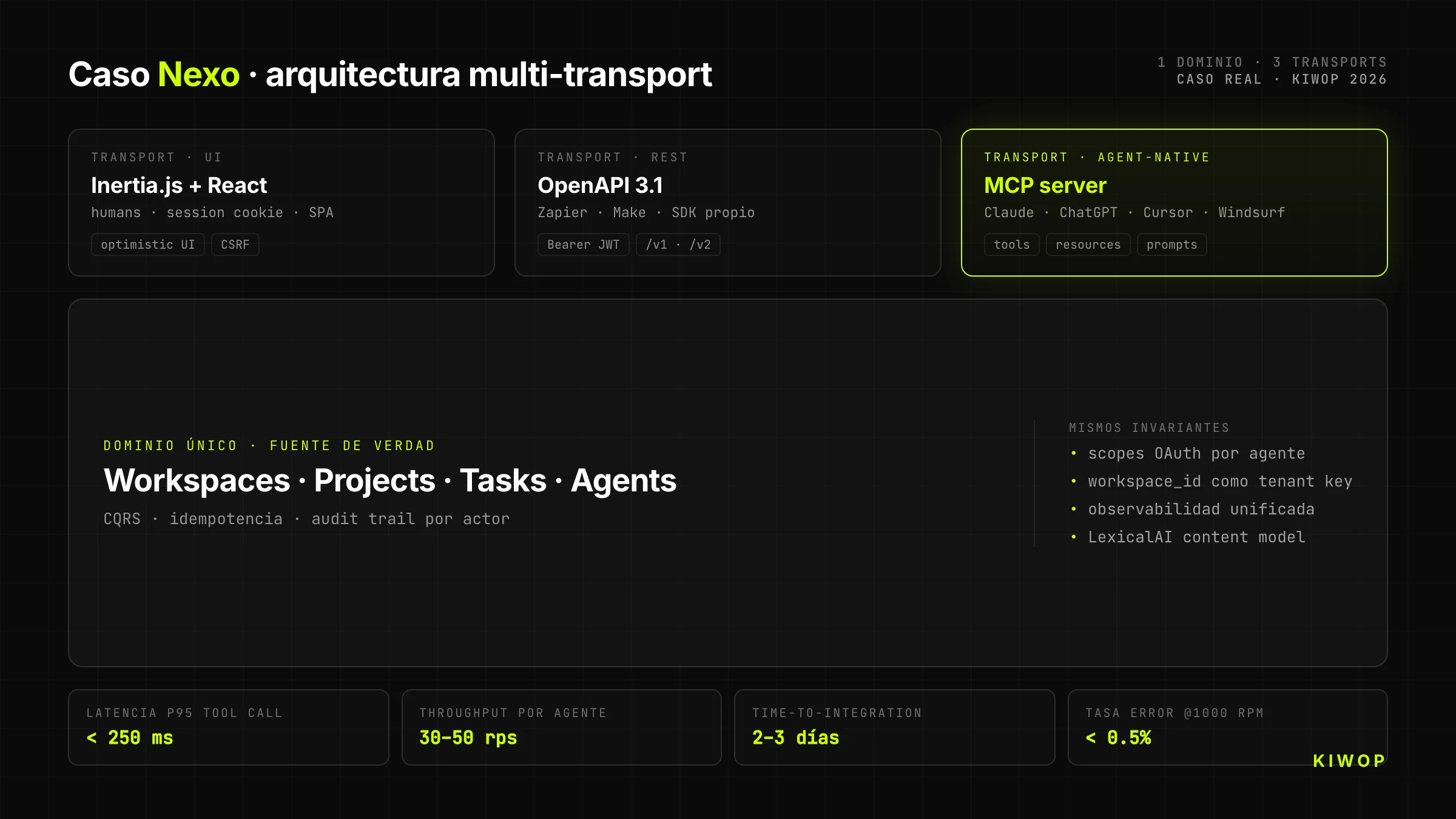
Nexo ist unser eigenes Workspace-SaaS für Teams. Es begann als Laravel-+-React-+-Inertia.js-App für Menschen (technische Dokumentation: Nexo: technische Anatomie unseres Multi-Tenant-SaaS). Als wir beschlossen, es für KI-Agenten zu öffnen, trafen wir eine architektonische Entscheidung, die alles Weitere vorgab: wir würden nicht REST "und Schluss" exponieren; wir würden direkt einen MCP-Server oberhalb derselben Domain exponieren, die bereits die UI bediente.
Headless-Architektur von Nexo
Das Backend von Nexo hat eine einzige Business-Domain (Workspaces, Projekte, Tasks, Notizen, Agenten). Auf dieser Domain laufen drei unterschiedliche Transports, die denselben Vertrag teilen:
- Inertia.js + React für die menschliche UI (Cookie-Session, optimistisch, angereicherter Client)
- REST + OpenAPI 3.1 für klassische Integrationen (Zapier, Make, eigenes SDK)
- MCP-Server für direkten Konsum aus Claude, ChatGPT und jedem Agenten mit MCP-Client
Die Domain ist dieselbe. Was sich ändert, ist die Transport-Schicht und die Client-Identität. Das bedeutet: Wenn ein Agent per MCP einen Task erstellt, erscheint dieser Task sofort in der menschlichen UI desselben Workspaces, mit dem korrekten User als Owner und dem klar als Akteur markierten Agenten.
Warum MCP statt REST "und Schluss"
Wir hätten nur REST exponieren und jeden Integrator seinen eigenen MCP-Wrapper bauen lassen können. Wir haben uns aus drei Gründen für natives MCP entschieden:
- Der MCP-Vertrag erfasst Intention besser als generisches REST. Ein MCP-Tool wird mit Name, Beschreibung, typisierten Parametern und Beispielen beschrieben — das LLM muss nicht erraten, welchen von zwanzig REST-Endpoints es nehmen soll; es sieht es buchstäblich.
- Das MCP-Ökosystem wächst schneller als jedes proprietäre SDK. Claude, ChatGPT, Cursor, Windsurf, VS Code, Cline — alle sprechen MCP. Wenn wir MCP exponieren, konsumieren uns alle ab Tag eins.
- Observability ist gratis. Die MCP-Harnesses melden bereits, welches Tool aufgerufen wurde und mit welchem Ergebnis. Wir sparen uns den Bau eines eigenen Adoption-Dashboards pro Agent.
Zielmetriken (Design-Projektionen)
Die folgenden Zahlen sind Designziele, kalibriert gegen vergleichbare Implementierungen, noch keine Produktionsmessungen im großen Maßstab. Wir veröffentlichen sie als Referenz dafür, was von einer gut gemachten MCP-first-Architektur vernünftigerweise zu erwarten ist:
Werte kalibriert in internen Tests und gegen vergleichbare Literatur; sie werden mit Produktionsdaten beim Skalieren verfeinert.
Lektionen aus erster Hand
Was wir nach dem Design und Betrieb der MCP-Schicht von Nexo bereits wissen, und was in keinem Paper stand, als wir anfingen:
- Die realen architektonischen Kosten sind nicht, MCP zu schreiben; es ist, dein Backend zu refactoren, damit die Endpoints granular, idempotent und kompositionsfähig sind. Der MCP-Server selbst sind ~600 Zeilen TypeScript. Das Harte ist, dass deine Business-Schicht das aushält, was die Agenten von ihr verlangen.
- Der Audit-Trail pro Agent verändert die Gespräche mit Kunden. Wenn ein B2B-Kunde in seinem Dashboard sieht "dein Claude-Agent hat am Freitag den Status von 14 Tasks geändert", verschiebt sich das Gespräch von "kann ich darauf vertrauen?" zu "ich will mehr Agenten Zugang geben".
- Granulare OAuth-Scopes verkaufen. Der erste technische Einwand im Sales war immer "und wenn der Agent außer Kontrolle gerät?". Eine typisierte Antwort — "dieser Agent kann nur Projekt X bis zum 31. Mai lesen" — blockiert die Unterschrift.
Wann NICHT auf API-First migrieren
Die Migration auf API-First ist teuer und rechtfertigt sich nicht immer. Drei Fälle, in denen unsere ehrliche Empfehlung lautet: tu es nicht:
- Produkt ohne realen Agentic-Use-Case. Wenn dein Produkt ein internes ERP ist, das von 30 Mitarbeitern genutzt wird, und keiner davon Agenten bauen wird, liefert dir eine API-first-Migration keinen ROI. Investiere in andere Dinge.
- Unzureichendes Volumen zur Amortisation des Overheads. Wenn dein Gesamttraffic bei 100 Requests pro Tag liegt, wiegt die zusätzliche Komplexität (Gateway, Versionierung, striktes OpenAPI, MCP) mehr als der Nutzen. Validiere zuerst, dass es Nachfrage gibt.
- Team ohne DevEx-Reife. API-First verlangt eine Kultur, in der der Vertrag ein Produkt ist: disziplinierter Changelog, Contract-Tests, dokumentierte SLAs. Ohne diese Kultur desynchronisiert der Vertrag in sechs Monaten und die ganze Arbeit ist verloren. Bevor du migrierst, investiere in die Kultur.
Wenn du auf einen der drei Fälle passt, bleibe besser bei deinem aktuellen Stack und revidiere in einem Jahr.
Migrations-Roadmap — wo man anfängt
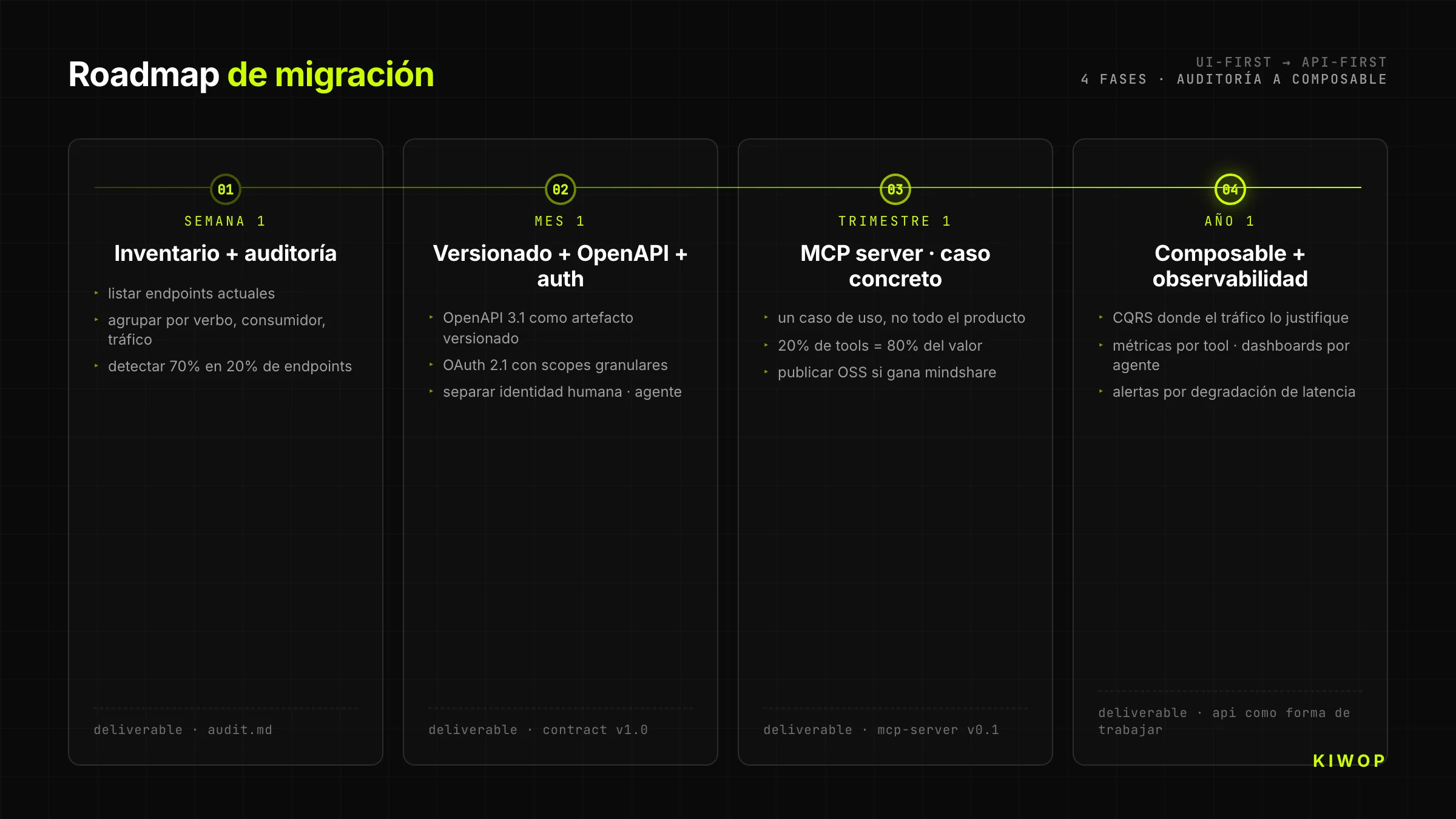
Woche 1 — Inventar und Audit
Liste alle aktuellen Endpoints deines Backends. Gruppiere sie nach HTTP-Verb, nach Konsument (Web, Mobile, intern), nach Nutzungsfrequenz. Markiere, welche explizite Versionierung haben, welche strukturierte Fehler zurückgeben, welche idempotent sind. Dieses Audit zeigt meistens, dass 70 % des Codes in 20 % der Endpoints leben — das sind die Hauptkandidaten für die Umstellung auf API-first.
Monat 1 — Versionierung + OpenAPI + saubere Auth
Publiziere OpenAPI 3.1 als versioniertes Artefakt für die kritischen Endpoints. Migriere die Authentifizierung auf OAuth 2.1 mit granularen Scopes. Trenne die menschliche Identität von der Agenten-Identität. Versuche nicht, alles umzuschreiben; beginne mit einer abgegrenzten Domain (zum Beispiel nur dem Modul "Reservierungen" oder "Rechnungen") und behandle sie als Probe.
Quartal 1 — MCP-Server für einen Use-Case
Wähle einen konkreten Use-Case und baue einen MCP-Server, der ihn exponiert. Versuche nicht, das gesamte Produkt abzudecken; decke die 20 % an Tools ab, die 80 % des Werts erzeugen. Publiziere den MCP-Server als Open-Source, wenn es Sinn ergibt (gewinne Mindshare), oder geschlossen, aber dokumentiert.
Jahr 1 — Composable + vollständige Observability
Migriere den Rest des Backends auf das composable Modell. Implementiere CQRS dort, wo der Agenten-Write-Traffic es rechtfertigt. Instrumentiere Metriken pro Tool, Adoption-Dashboards pro Agent, Alerts bei Latenzdegradation. An diesem Punkt hört die API-First-Architektur auf, ein Projekt zu sein, und wird zur Arbeitsweise des Teams.
Häufig gestellte Fragen
Was ist API-First in einem Satz?
Eine Architektur, in der der maschinenlesbare Vertrag entworfen, versioniert und veröffentlicht wird, bevor irgendeine konsumierende menschliche Schnittstelle existiert.
Ist das dasselbe wie Headless?
Nein. Headless bedeutet "ohne an das Backend gekoppelte Präsentationsschicht" — es ist eine strukturelle Eigenschaft. API-First ist eine Designdisziplin: der Vertrag zuerst. Jede API-First-Architektur ist headless, aber nicht jede Headless ist API-First (du kannst Headless mit einem lausigen Vertrag haben).
Brauche ich MCP, wenn ich bereits REST habe?
Nicht strikt, aber MCP beschleunigt die Agenten-Adoption brutal. Wenn deine Kunden dein Produkt über Claude, ChatGPT oder Cursor konsumieren werden, erspart ihnen natives MCP den Bau eines eigenen Adapters. Die technische Abdeckung findet sich in MCP, WebMCP und A2A: Protokolle für KI-Agenten.
Wie monetarisiert man eine von Agenten konsumierte API?
Das klassische Modell (Preis pro Nutzer) passt nicht — ein Agent ist kein Nutzer. Modelle, die funktionieren: Preis pro Volumen (Requests oder verbrauchte Tokens), Preis pro geliefertem Wert (Anzahl abgeschlossener Aktionen), Preis pro angebundenem Agent (Lizenz pro Bot). Einige Plattformen berechnen nach Agenten-Tier je nach Kritikalität.
Was kostet die Migration von UI-First zu API-First?
Es hängt vom Ausgangspunkt ab, aber eine ehrliche Migration für eine mittelgroße SaaS-Plattform (50–200 Endpoints) liegt zwischen 3 und 9 Monaten mit einem dedizierten Team. Die größten Kosten sind nicht technisch, sondern kulturell — sich darauf zu einigen, dass der Vertrag das primäre Artefakt ist.
Was passiert mit meinem SEO, wenn ich keine UI mehr habe?
API-First heißt nicht, die öffentliche UI zu eliminieren. Die UI bleibt für Menschen und SEO; was du hinzufügst, ist die API/MCP-Schicht für Agenten. Interessant ist, dass du mit WebMCP direkte Aktionen an die KI-Agenten exponieren kannst, die deine Website besuchen — das eröffnet neue Akquisitionsflächen.
Fazit
Eine API-First-Architektur ist kein technischer Luxus und keine Mode; sie ist die Art, Produkt zu bauen, wenn der Hauptkonsument kein Mensch mehr ist, sondern ein Agent. Der öffentliche Pivot von Salesforce im Jahr 2026 ist die späte Bestätigung dessen, was Teams, die heute bauen, bereits voraussetzen: Die API ist die Vordertür und die UI ist nur ein weiterer Client.
Bei Kiwop — Digitalagentur spezialisiert auf Softwareentwicklung und angewandte Künstliche Intelligenz für globale Kunden in Europa und den USA — haben wir Nexo vom ersten Tag an nach diesem Modell gebaut und helfen technischen Teams, ihre aktuelle Architektur zu diagnostizieren und den kürzesten Weg zu API-First zu zeichnen, ohne das Funktionierende zu zerbrechen. Wenn du die Migration erwägst, fordere ein API-first-Architektur-Audit an oder wirf einen Blick auf unsere Services für Entwicklung von KI-Agenten, KI-Beratung und LLM-Integration.
Und wenn dich die technische Richtung interessiert hat, folge dem Faden mit den Posts des Clusters: MCP, WebMCP und A2A: Protokolle für KI-Agenten, KI-Agenten in Produktion: Muster und Antipatterns, Nexo: technische Anatomie unseres Multi-Tenant-SaaS und von OpenClaw zu PA mit Claude Code und MCP.


